




 布隆过滤器是一种空间效率高的数据结构,用于判断一个元素可能是否存在于集合中,但存在误判可能。其原理基于哈希函数和位图。CountingBloomFilter解决了删除数据的问题,但仍有误判。布谷鸟过滤器在空间效率和查询性能上优于布隆过滤器,支持计数,但不适用于所有位图长度。在动态系统中,布隆过滤器的误判率随时间可能上升,需要重建。
布隆过滤器是一种空间效率高的数据结构,用于判断一个元素可能是否存在于集合中,但存在误判可能。其原理基于哈希函数和位图。CountingBloomFilter解决了删除数据的问题,但仍有误判。布谷鸟过滤器在空间效率和查询性能上优于布隆过滤器,支持计数,但不适用于所有位图长度。在动态系统中,布隆过滤器的误判率随时间可能上升,需要重建。
1.概述:
布隆过滤器(Bloom Filter)大概的思路就是,当你请求的信息来的时候,先检查一下你查询的数据我这有没有,有的话将请求压给数据库,没有的话直接返回
2.原理
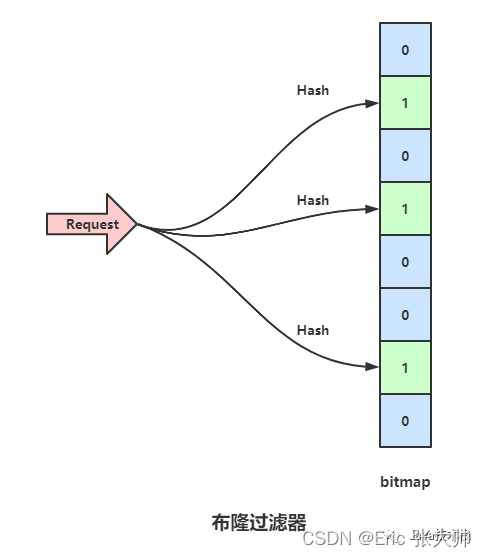
一个bitmap用于记录,bitmap原始数值全都是0,当一个数据存进来的时候,用三个Hash函数分别计算三次Hash值,并且将bitmap对应的位置设置为1,上图中,bitmap 的1,3,6位置被标记为1,这时候如果一个数据请求过来,依然用之前的三个Hash函数计算Hash值,如果是同一个数据的话,势必依旧是映射到1,3,6位,那么就可以判断这个数据之前存储过,如果新的数据映射的三个位置,有一个匹配不上,假如映射到1,3,7位,由于7位是0,也就是这个数据之前并没有加入进数据库,所以直接返回。
3.存在的问题
第一方面,布隆过滤器可能误判:
假如有这么一个情景,放入数据包1时,将bitmap的1,3,6位设置为了1,放入数据包2时将bitmap的3,6,7位设置为了1,此时一个并没有存过的数据包请求3,做三次哈希之后,对应的bitmap位点分别是1,6,7,这个数据之前并没有存进去过,但是由于数据包1和2存入时将对应的点设置为了1,所以请求3也会压倒数据库上,这种情况,会随着存入的数据增加而增加。
第二方面,布隆过滤器没法删除数据,删除数据存在以下两种困境:
一是,由于有误判的可能,并不确定数据是否存在数据库里,例如数据包3。
二是,当你删除某一个数据包对应位图上的标志后,可能影响其他的数据包,例如上面例子中,如果删除数据包1,也就意味着会将bitmap1,3,6位设置为0,此时数据包2来请求时,会显示不存在,因为3,6两位已经被设置为0。
4.布隆过滤器增强版
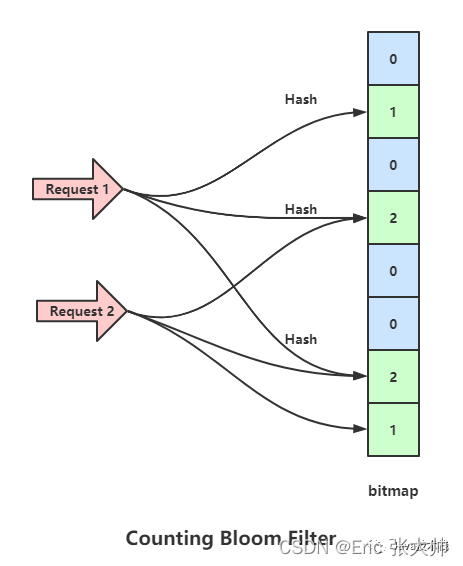
为了解决上面布隆过滤器的问题,出现了一个增强版的布隆过滤器(Counting Bloom Filter),这个过滤器的思路是将布隆过滤器的bitmap更换成数组,当数组某位置被映射一次时就+1,当删除时就-1,这样就避免了普通布隆过滤器删除数据后需要重新计算其余数据包Hash的问题,但是依旧没法避免误判。
布谷鸟过滤器
相比布谷鸟过滤器,布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数。
查询性能弱:是因为布隆过滤器需要使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低。
空间效率低:是因为在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多。不过布隆过滤器并没有要求位图的长度必须是 2 的指数,而布谷鸟过滤器必须有这个要求。从这一点出发,似乎布隆过滤器的空间伸缩性更强一些。
不支持反向删除操作:这个问题着实是击中了布隆过滤器的软肋。在一个动态的系统里面元素总是不断的来也是不断的走。布隆过滤器就好比是印迹,来过来就会有痕迹,就算走了也无法清理干净。比如你的系统里本来只留下 1kw 个元素,但是整体上来过了上亿的流水元素,布隆过滤器很无奈,它会将这些流失的元素的印迹也会永远存放在那里。随着时间的流失,这个过滤器会越来越拥挤,直到有一天你发现它的误判率太高了,不得不进行重建。


















 3495
3495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









