




 本文介绍了布隆过滤器和布谷鸟过滤器在大数据量集合中判断元素是否存在的一种高效方法。布隆过滤器利用位数组和多个哈希函数,存在一定的误判概率,而布谷鸟过滤器解决了不能删除元素的问题,提高了查询性能和空间利用率,但仍有误判率。这两种过滤器常用于缓存、爬虫URL去重和垃圾邮件过滤等领域。
本文介绍了布隆过滤器和布谷鸟过滤器在大数据量集合中判断元素是否存在的一种高效方法。布隆过滤器利用位数组和多个哈希函数,存在一定的误判概率,而布谷鸟过滤器解决了不能删除元素的问题,提高了查询性能和空间利用率,但仍有误判率。这两种过滤器常用于缓存、爬虫URL去重和垃圾邮件过滤等领域。
一、过滤器使用场景:
比如有如下几个需求:
1、原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
2、接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?
解决办法还是上面的两种,很显然,都不太好。
3、同理还有垃圾邮箱的过滤。
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,过滤器应运而生了。
二、布隆过滤器(Bloom Filter)
布隆过滤器:一种数据结构(bitmap),是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
工作流程-添加元素
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。
下面对布隆过滤器工作流程做简单描述,如下图所示:
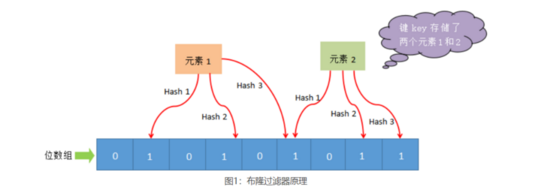
当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1470
1470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









