









 本文介绍了如何使用多项式朴素贝叶斯算法进行文本分类,特别关注于20个新闻组数据集的分类任务。通过sklearn库,我们构建了一个包含TF-IDF向量化和多项式朴素贝叶斯分类器的管道模型,实现了对新闻文章的有效分类。
本文介绍了如何使用多项式朴素贝叶斯算法进行文本分类,特别关注于20个新闻组数据集的分类任务。通过sklearn库,我们构建了一个包含TF-IDF向量化和多项式朴素贝叶斯分类器的管道模型,实现了对新闻文章的有效分类。
贝叶斯算法中最重要用的用的最广的是
使用多项式朴素贝叶斯的地方是文本分类,其中特征与待分类文档中的字数或频率有关。
将使用20个新闻组语料库中的稀疏字数功能来将这些短文档分类。
数据集的介绍
使用 sklearn.datasets中的 fetch_20newsgroups
该数据集介绍
20 newsgroups数据集18000篇新闻文章,一共涉及到20种话题,所以称作20 newsgroups text dataset,分文两部分:训练集和测试集,通常用来做文本分类.
详细可看
https://blog.youkuaiyun.com/imstudying/article/details/77876159
开始
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
只使用了 talk.religion.misc’, ‘soc.religion.christian’,
‘sci.space’, ‘comp.graphics’ 这4 个
categories = ['talk.religion.misc', 'soc.religion.christian',
'sci.space', 'comp.graphics']
train = fetch_20newsgroups(subset='train', categories=categories)
test = fetch_20newsgroups(subset='test', categories=categories)
查看数据
print(train.data[0])

使用tf-idf,并创建一个管道,将其连接到一个多项式的Naive Bayes分类器
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
通过管道,将模型应用于训练数据,并预测测试数据的标签:
model.fit(train.data, train.target)
labels = model.predict(test.data)
labels
# array([2, 0, 1, ..., 1, 2, 1], dtype=int64)
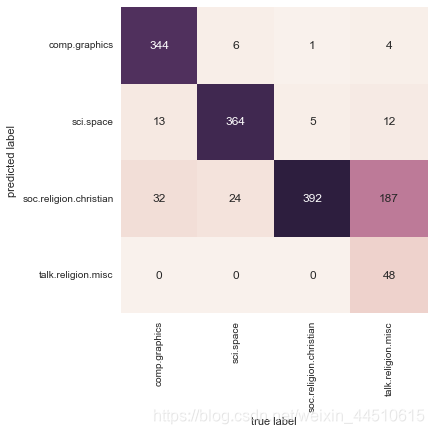
下面是测试数据的真实标签和预测标签之间的混淆矩阵
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(test.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=train.target_names, yticklabels=train.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label')
定义函数,它将返回单个字符串的预测
def predict_category(s, train=train, model=model):
pred = model.predict([s])
return train.target_names[pred[0]]
predict_category('sending a payload to the ISS')
‘sci.space’
predict_category('discussing islam vs atheism')
‘soc.religion.christian’
predict_category('determining the screen resolution')
‘comp.graphics’
完成任务


















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











