







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python爬虫从指定网页抓取2023年全国联行号开户行的名称和联行号信息,并将其存储到Excel文件中,以供后续分析使用。主要涉及requests、BeautifulSoup和openpyxl库的使用。
本文介绍了如何使用Python爬虫从指定网页抓取2023年全国联行号开户行的名称和联行号信息,并将其存储到Excel文件中,以供后续分析使用。主要涉及requests、BeautifulSoup和openpyxl库的使用。
需求分析
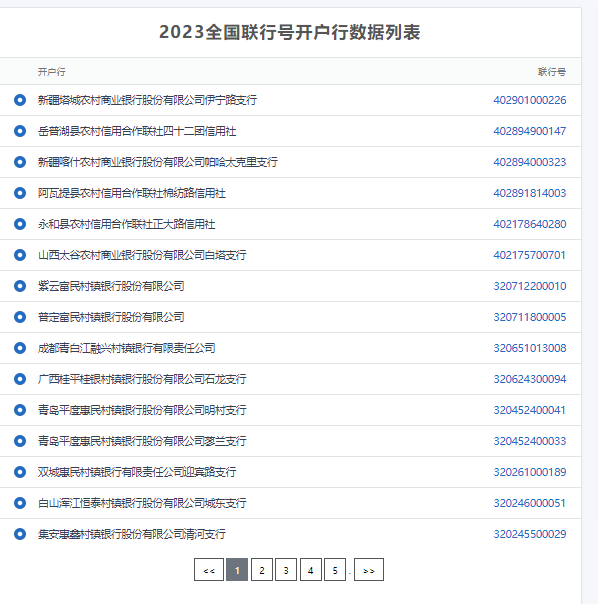
根据链接 https://chakahao.com/lhh/index_1.html ,我们将爬取的信息内容为2023全国联行号开户行数据列表。
具体来说,该页面显示了开户行名称和联行号(也称为行号、网点号、支行号等)的列表。我们的爬虫将获取每一页的数据,并将这些数据保存到Excel文件中,以便进一步使用和分析。
步骤1:导入所需的库
首先,我们需要导入所需的库,包括requests用于发起HTTP请求,BeautifulSoup用于解析HTML页面,以及openpyxl用于创建和保存Excel文件。
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











