







背景
遇到单表多场景下的数据检索,在clickhouse有时真的头疼。
实践过程
已有数据如下:
CREATE TABLE default.table_tmp
(
`rk` String COMMENT 'rk',
`vin` String COMMENT '车辆ID',
`message_time` DateTime COMMENT '报文采集时间',
……
`data_date` Date COMMENT '日期',
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(data_date)
ORDER BY (message_time, vin, rk)
SETTINGS index_granularity = 8192
场景一:检索最近20min,所有的车辆数据。
场景二:检索车辆01,当月所有的车辆数据。
上述的表结构,可以满足场景一,因为数据的存储是按order by的顺序存储,第一个字段是按时间排序,故可以快速检索所需要的数据块
场景二查找vin编码的时候,近乎需要全表扫描。因为前一个排序字段为时间,无法提前过滤数据。所以大数据量的话,检索速度巨慢。
解决方案
方案一:之前的解决方案是物化视图,原理相当于重新copy一份数据,数据在底层重新排序。缺点:似乎比较重(待验证)。
方案二:据调研,clickhouse从21.6引入了新特性——Project。道理与物化视图类似,但他可以根据我们需要指定的列,进行排序,从而减少不必要的冗余,在应用层面也可以达到业务的无感知状态。
实际操作
1、根据需要建立相应的project
alter table table_tmp add project p1
{
select data_date,vin,message
order by data_date,vin
};
2、刷新物化视图
alter table table_tmp materialize project p1;
3、检查物化视图是否已刷新
select * from system.mutations order by create_time desc
如果is_done字段为1,则说明已完成刷新,否则,等待。parts_to_do字段可以查看,还需要执行多少分区。
4、设置参数
set allow_experimental_projection_optimization = 1
5、查询验证
执行计划验证:
expain
select vin from table_tmp
where data_date between '2023-08-06' and '2023-08-07'
and vin = 'LG123456678999
如果ReadFromeStorage是with Normal projection p1,则说明从我们创建的project读取。
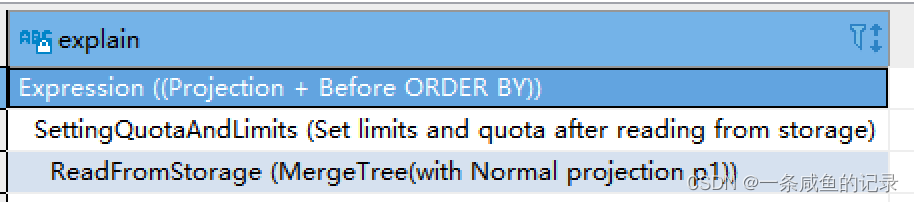
否则,如下,则没走project。
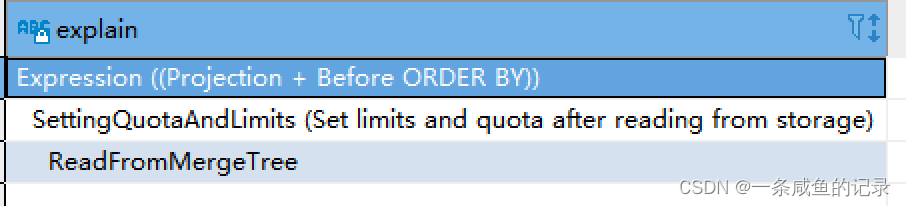
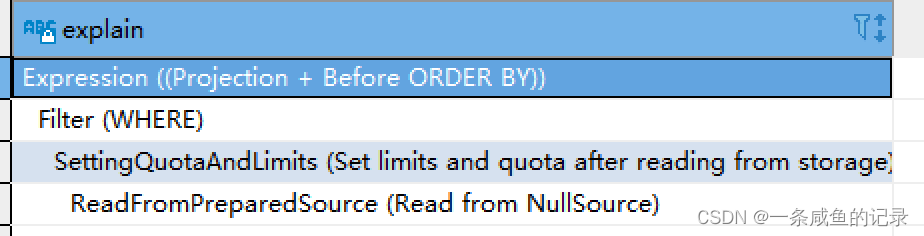
还有一种情况:Read from NullSource。这里的原因是因为分区没数据。
6、测试结果
在一个有1300w的数据集中检索1w条数据,如果不走project,需要大概200s左右,走project的话,仅需不到1s。(从query_log验证,似乎不用走内存,query_log对此查询也未记录)
内存等方面,待验证。


以上,over!

















 5420
5420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









