




一、CUDA内存模型概述
1. CUDA内存模型
对于程序员来说,一般有两种类型的存储器:
· 可编程的:你需要显式地控制哪些数据存放在可编程内存中
· 不可编程的:你不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
在CPU内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。
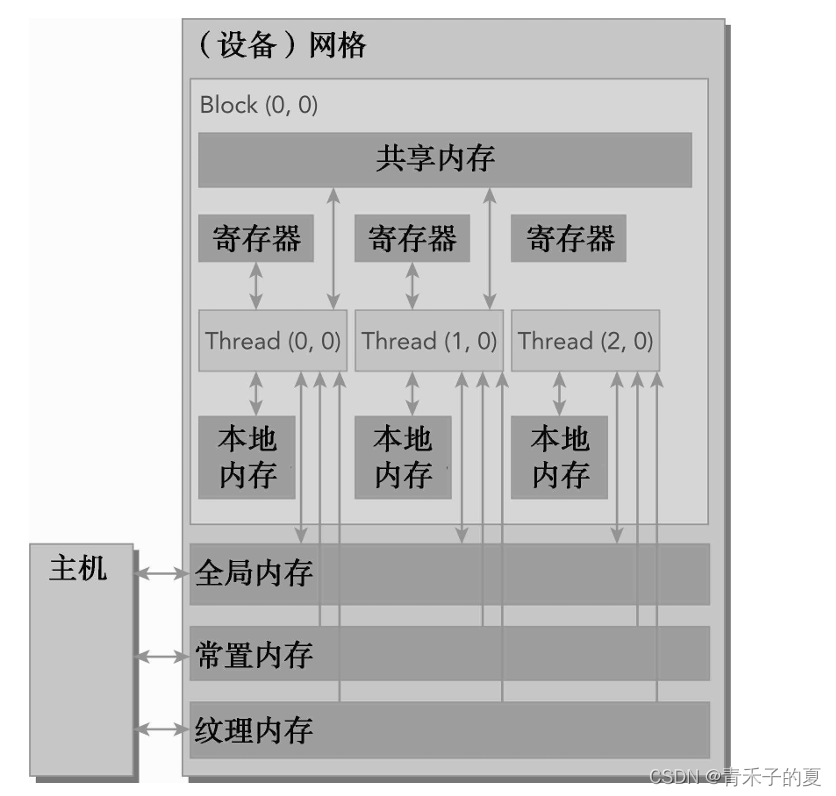
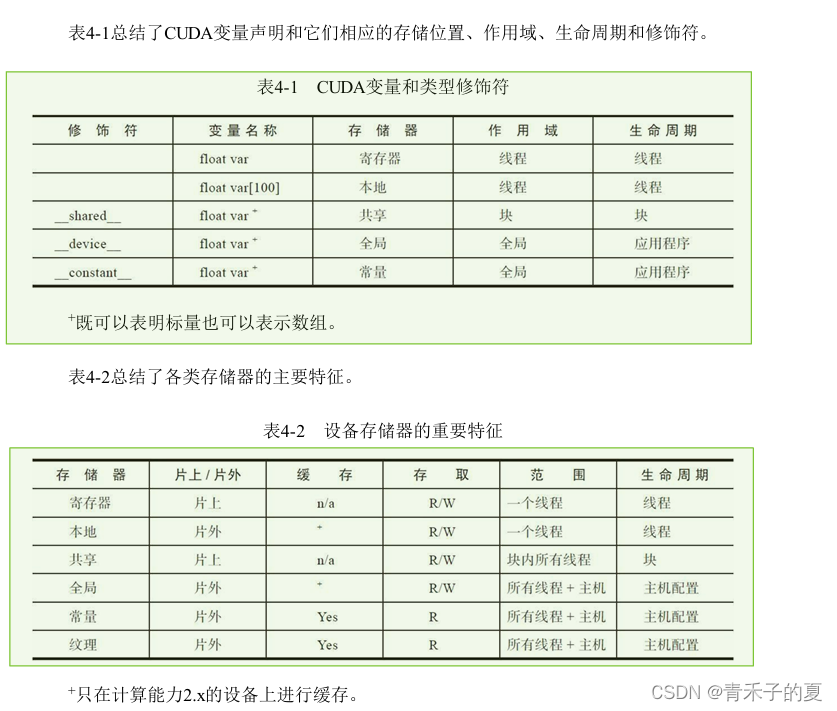
CUDA内存模型提出了多种可编程内存的类型:寄存器、共享内存、本地内存、常量内存、纹理内存、全局内存。
一个核函数中的线程都有自己私有的本地内存。一个线程块有自己的共享内存,对同一线程块中所有线程都可见,其内容持续线程块的整个生命周期。所有线程都可以访问全局内存。所有线程都能访问的只读内存空间有:常量内存空间和纹理内存空间。全局内存、常量内存和纹理内存空间有不同的用途。纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。
寄存器
寄存器是GPU上运行速度最快的内存空间。核函数中声明的一个没有其他修饰符的自变量,通常存储在寄存器中。在核函数声明的数组中,如果用于引用该数组的索引是常量且能在编译时确定,那么该数组也存储在寄存器中。
寄存器变量对于每个线程来说都是私有的,一个核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同。一旦核函数执行完毕,就不能对寄存器变量进行访问了。
如果一个核函数使用了超过硬件限制数量的寄存器,则会用本地内存替代多占用的寄存器。这种寄存器溢出会给性能带来不利影响。nvcc编译器使用启发式策略来最小化寄存器的使用,以避免寄存器溢出。
本地内存

共享内存
在核函数中使用如下修饰符修饰的变量存放在共享内存中:__shared__
共享内存在核函数的范围内声明,其生命周期伴随着整个线程块。当一个线程块执行结束后,其分配的共享内存将被释放并重新分配给其他线程块。
共享内存是线程之间相互通信的基本方式。一个块内的线程通过使用共享内存中的数据可以相互合作。访问共享内存必须同步使用如下调用:
void __syncthreads();该函数设立了一个执行障碍点,即同一个线程块中的所有线程必须在其他线程被允许执行前达到该处。为线程块中所有线程设立障碍点,这样可以避免潜在的数据冲突。

常量内存
常量内存驻留在设备内存中,并在每个SM专用的常量缓存中缓存。常量变量用如下修饰符来修饰:__constant__
常量变量必须在全局空间内和所有核函数之外进行声明。对于所有计算能力的设备,都只可以声明64KB的常量内存。常量内存是静态声明的,并对同一编译单元中的所有核函数可见。
核函数只能从常量内存中读取数据。因此,常量内存必须在主机端使用下面的函数来初始化:
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src, size_t count);这个函数将count个字节从src指向的内存复制到symbol指向的内存中,这个变量存放在设备的全局内存或常量内存中。在大多数情况下这个函数是同步的。
每从一个常量内存中读取一次数据,都会广播给线程束里的所有线程。
纹理内存
纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存。纹理内存是一种通过指定的只读缓存访问的全局内存。只读缓存包括硬件滤波的支持,它可以将浮点插入作为读过程的一部分来执行。纹理内存是对二维空间局部性的优化,所以线程束里使用纹理内存访问二维数据的线程可以达到最优性能。
全局内存
全局内存是GPU中最大、延迟最高并且最常使用的内存。global指的是其作用域和生命周期。它的声明可以在任何SM设备上被访问到,并且贯穿应用程序的整个生命周期。
一个全局内存变量可以被静态声明或动态声明。可以使用__device__修饰符在设备代码中静态地声明一个变量。
在主机端使用cudaMalloc函数分配全局内存,使用cudaFree函数释放全局内存。然后指向全局内存的指针就会作为参数传递给核函数。全局内存分配空间存在于应用程序的整个生命周期中,并且可以访问所有核函数中的所有线程。
全局内存常驻于设备内存中,可通过32字节、64字节或128字节的内存事务进行访问。这些内存事务必须自然对齐。
GPU缓存
GPU缓存是不可编程的内存。在GPU上有4种缓存:

文件作用域中的变量:可见性与可访问性
一般情况下,设备核函数不能访问主机变量,并且主机函数也不能访问设备变量。即使这些变量在同一文件作用域内被声明。
CUDA运行时API能够访问主机和设备变量。
二、内存管理
1. 内存分配和释放
在主机上使用下列函数分配全局内存:
cudaError_t cudaMalloc(void **devPtr, size_t count);这个函数在设备上分配了count字节的全局内存,并用devptr指针返回该内存的地址。如果cudaMalloc函数执行失败则返回cudaErrorMemoryAllocation。在已分配的全局内存中的值不会被清除。你需要用从主机上传输的数据来填充所分配的全局内存,或用下列函数将其初始化:
cudaError_t cudaMemset(void *devPtr, int value, size_t count);这个函数用存储在变量value中的值来填充从设备内存地址devPtr处开始的count字节。
一旦一个应用程序不再使用已分配的全局内存,那么可以用以下代码释放该内存空间:
cudaError_t cudaFree(void *devPtr);这个函数释放了devPtr指向的全局内存,该内存在此前使用了一个设备分配函数(如cudaMalloc)来进行分配。否则,它将返回一个错误cudaErrorInvalidDevicePointer。如果地址空间已经被释放,那么cudaFree也返回一个错误。
设备内存的分配和释放操作成本较高,所有应用程序应重利用设备内存,以减少对整体性能的影响。
2. 内存传输
一旦分配好了全局内存,你就可以使用下列函数从主机向设备传输数据:
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);这个函数从内存位置src复制了count字节到内存位置dst。变量kind指定了复制的方向,可以有下列取值:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









