










这个代码主要是读取 results.csv 文件绘制损失曲线图
说明:
字体设置:通过 plt.rcParams 设置了默认字体为宋体,以确保图表中的中文可以正常显示。
负号问题:plt.rcParams[‘axes.unicode_minus’] = False 用于解决负号显示为方块的问题。
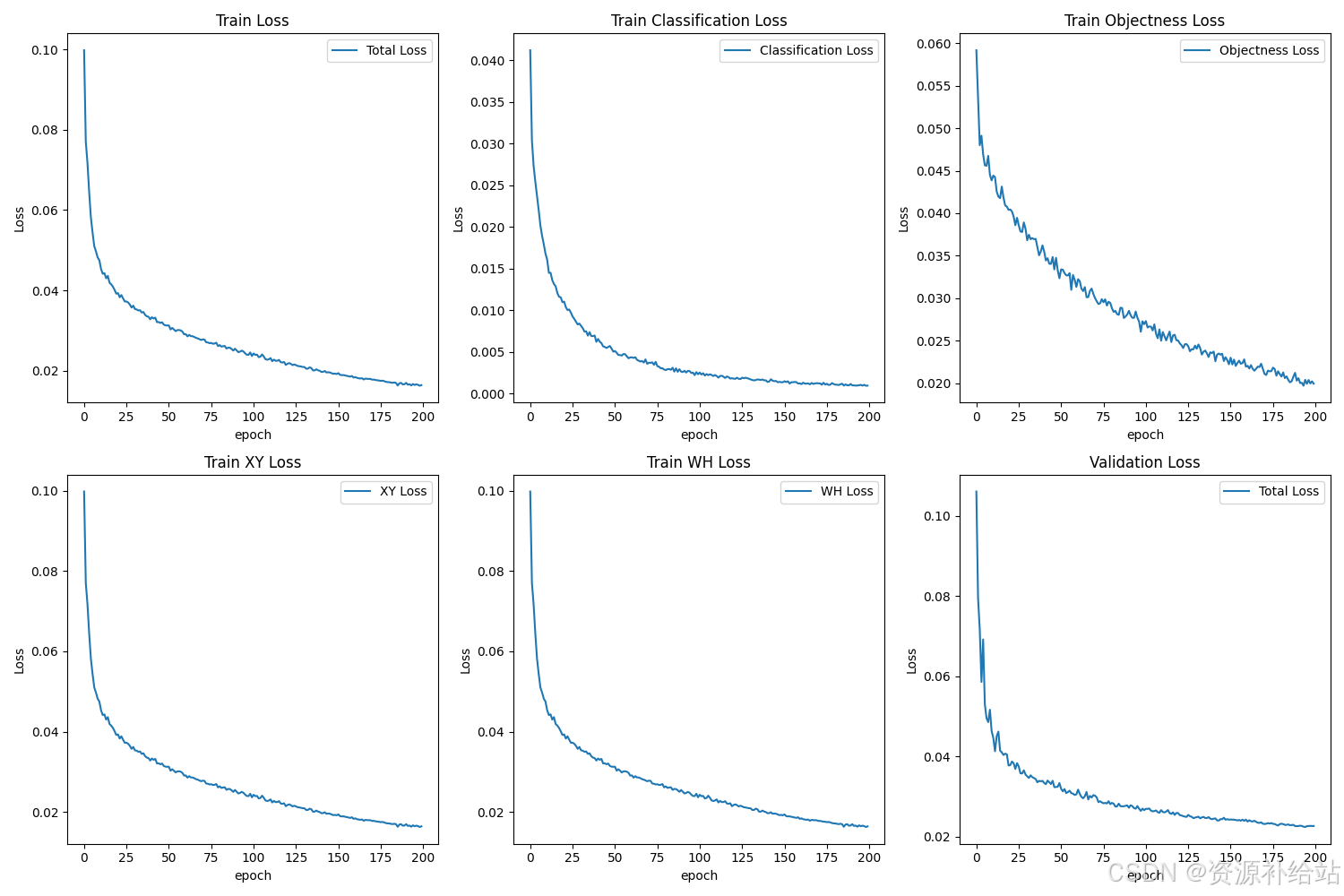
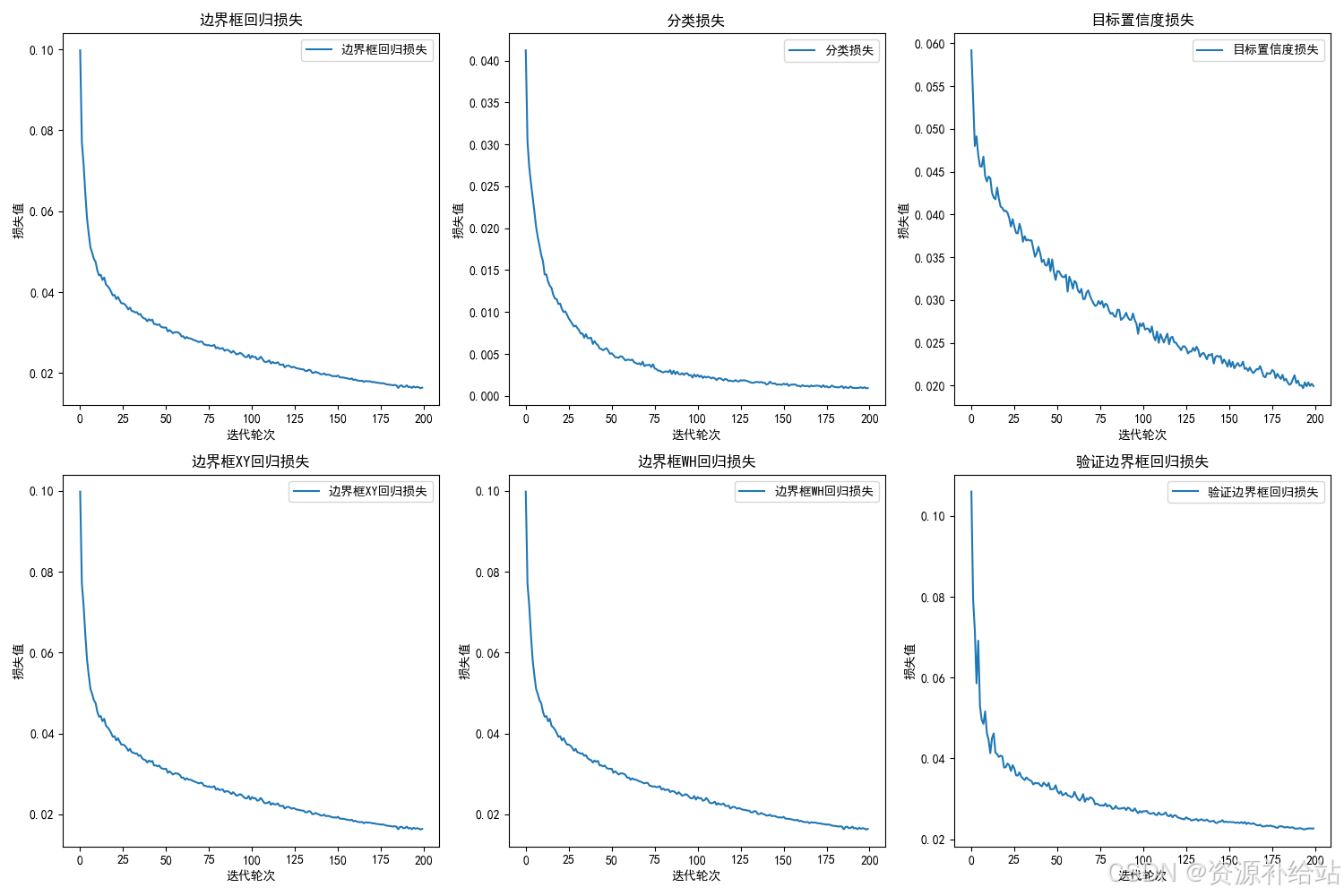
代码详解:运行此脚本后,它将读取 results.csv 文件中的数据,并根据指定的列名绘制损失曲线图,图表中的中文标签应该可以正常显示,并将图片保存为带有时间后缀的文件。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
# 设置matplotlib字体为宋体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为宋体
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
# 指定results的路径
results_path = r'D:\Users\19114\anaconda3\envs\yolo\Lib\site-packages\ultralytics\yolov5-7.0\yolov5-7.0\runs\train\exp38'
# 指定文件名
filename = 'results.csv'
# 构建完整的文件路径
file_path = os.path.join(results_path, filename)
# 读取CSV文件
data = pd.read_csv(file_path)
# 检查数据的前几行以确认内容
print(data.head())
# 获取当前时间用于文件名
current_time = datetime.now().strftime('%Y%m%d_%H%M%S')
plt.figure(figsize=(15, 10))
# 绘制边界框回归损失曲线
plt.subplot(2, 3, 1)
data['train/box_loss'] = data[' train/box_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/box_loss'] = data['train/box_loss'].fillna(data['train/box_loss'].interpolate())
plt.plot(data[' epoch'], data['train/box_loss'], label='边界框回归损失')
plt.xlabel('迭代轮次')
plt.ylabel('损失值')
plt.title('边界框回归损失')
plt.legend()
plt.subplot(2, 3, 2)
data['train/cls_loss'] = data[' train/cls_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/cls_loss'] = data['train/cls_loss'].fillna(data['train/cls_loss'].interpolate())
plt.plot(data[' epoch'], data['train/cls_loss'], label='分类损失')
plt.xlabel('迭代轮次')
plt.ylabel('损失值')
plt.title('分类损失')
plt.legend()
plt.subplot(2, 3, 3)
data['train/obj_loss'] = data[' train/obj_loss'].astype(np.float32).replace(np.inf, np.nan)
data['train/obj_loss'] = data['train/obj_loss'].fillna(data['train/obj_loss'].interpolate())
plt.plot(data[' epoch'], data['train/obj_loss'], label='目标置信度损失')
plt.xlabel('迭代轮次')
plt.ylabel('损失值')
plt.title('目标置信度损失')
plt.legend()
plt.tight_layout()
# 生成带有时间后缀的图片文件名
output_filename = f'yolov5s_loss_curve_{current_time}.png'
plt.savefig(os.path.join(results_path, output_filename))
print(f'{output_filename} save in {results_path}/{output_filename}')

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









