







 本文介绍了如何使用MapReduce在Hadoop集群中将HBase数据迁移到HDFS,以及从HDFS反向导入到HBase。通过详细步骤和代码示例,展示了业务流程和操作过程。
本文介绍了如何使用MapReduce在Hadoop集群中将HBase数据迁移到HDFS,以及从HDFS反向导入到HBase。通过详细步骤和代码示例,展示了业务流程和操作过程。
HBase 与 MapReduce(数据:HDFS <==> HBase)
1、业务流程
为什么需要用 MapReduce 去访问 HBase 的数据?
答:加快分析速度和扩展分析能力。
MapReduce 访问 HBase 数据作分析一定是在离线分析的场景下应用:

2、HBaseToHDFS
2.1、导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zc.hbase</groupId>
<artifactId>hbase-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<hadoop.version>2.7.5</hadoop.version>
<hbase.version>1.6.0</hbase.version>
</properties>
<dependencies>
<!-- <dependency>-->
<!-- <groupId>org.apache.hbase</groupId>-->
<!-- <artifactId>hbase-client</artifactId>-->
<!-- <version>${hbase.version}</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}-${project.version}</finalName>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.2、代码实现
package com.zc.hbase.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @作者: zc
* @时间: 2021/3/16 11:00
* @描述: hbase --> HDFS
*/
public class HbaseReader {
// 表名
static final String TABLE_NAME = "user_info";
// zookeeper集群链接地址
static final String ZK_CONNECT_STR = "hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181";
static class HdfsSinkMapper extends TableMapper<Text, NullWritable>{
Text resKey = new Text();
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
String rowkey = new String(key.copyBytes());
String username = new String(value.getValue("base_info".getBytes(),"name".getBytes()));
resKey.set(rowkey + "\t" + username);
context.write(resKey, NullWritable.get());
}
}
static class HdfsSinkReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
System.setProperty("HADOOP_USER_NAME", "hadoop");
conf.set("hbase.zookeeper.quorum", ZK_CONNECT_STR);
Job job = Job.getInstance(conf);
job.setJarByClass(HbaseReader.class);
Scan scan = new Scan();
TableMapReduceUtil.initTableMapperJob(TABLE_NAME, scan,
HdfsSinkMapper.class, Text.class, NullWritable.class, job);
job.setReducerClass(HdfsSinkReducer.class);
FileOutputFormat.setOutputPath(job, new Path("/hbase_test/output"));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
boolean statue = job.waitForCompletion(true);
System.exit(statue ? 0 : 1);
}
}
2.3、jar 包运行
(1)将项目打包上传 hadoop 集群:hbase-demo-1.0-SNAPSHOT.jar
(2)运行 jar 包:hadoop jar hbase-demo-1.0-SNAPSHOT.jar com.zc.hbase.mapreduce.HbaseReader
(3)运行 YARN:
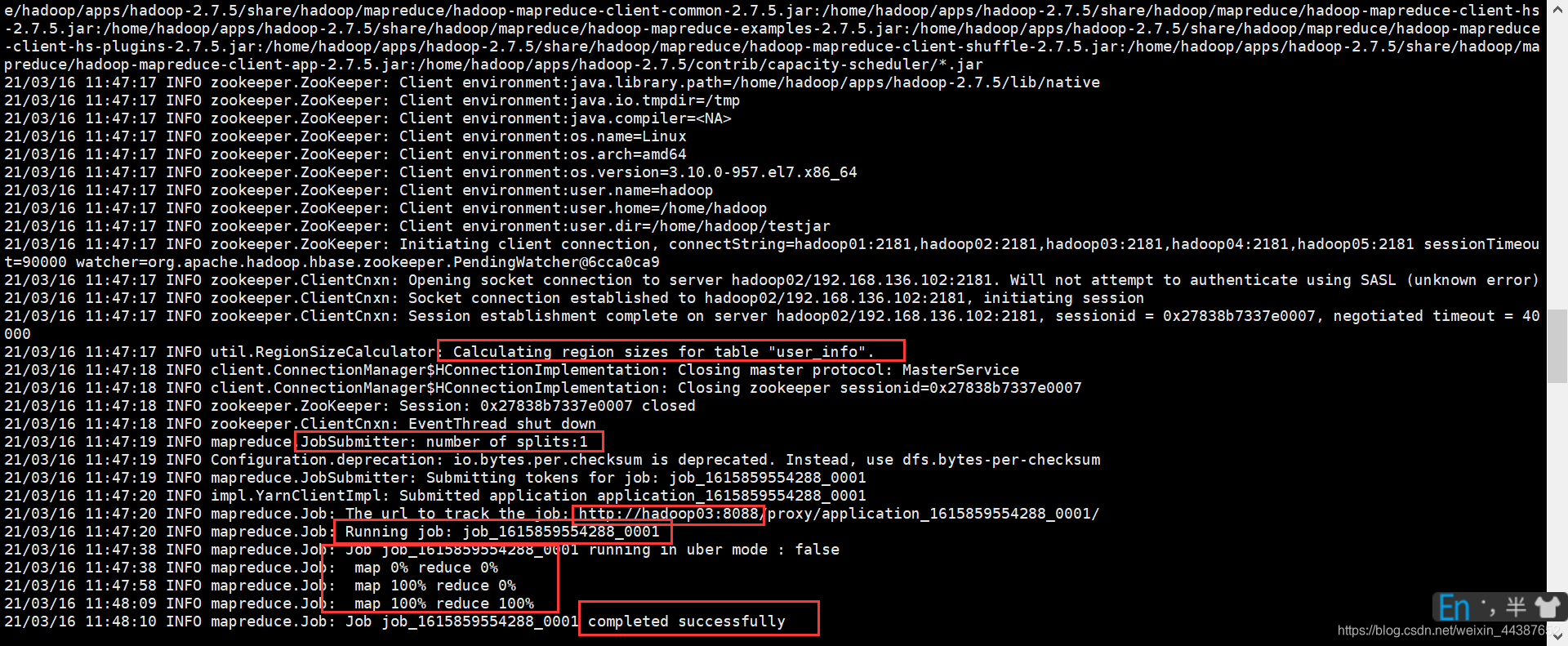
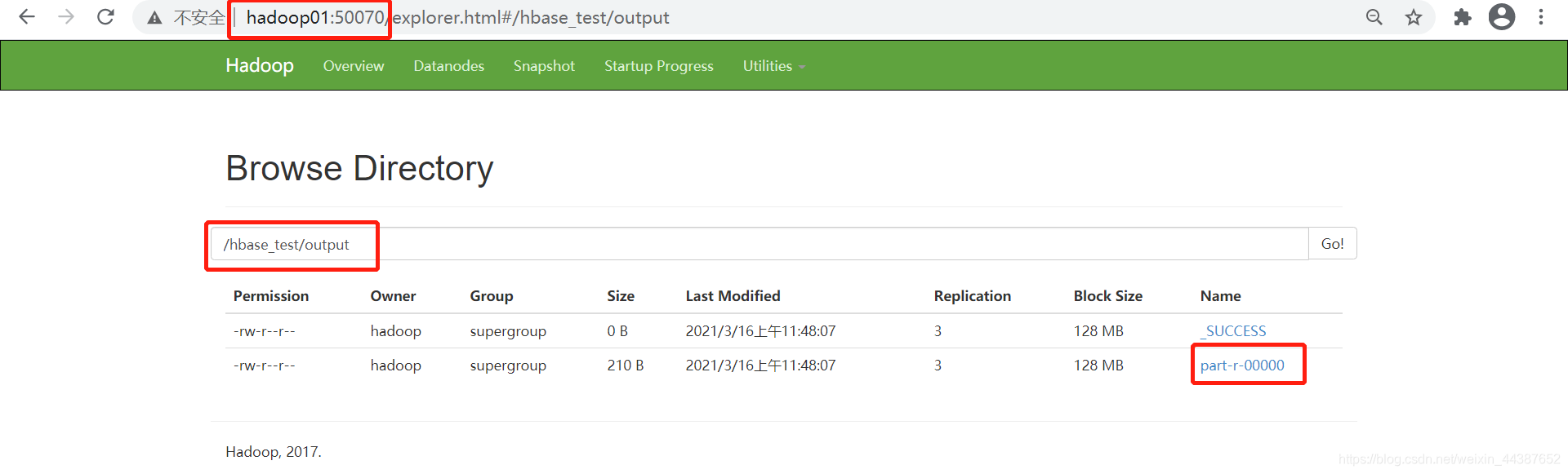
(4)查看结果:hadoop fs -cat /hbase_test/output/part-r-00000

3、HDFSToHBase
3.1、准备数据
user_info.txt
zhangsan_20201001_0001 18213456740 http://www.zhangsan_20201001_0000.cn
zhangsan_20201001_0001 18213456741 http://www.zhangsan_20201001_0001.cn
zhangsan_20201001_0002 18213456742 http://www.zhangsan_20201001_0002.cn
zhangsan_20201001_0003 18213456743 http://www.zhangsan_20201001_0003.cn
baiyc_20201001_0001 18213456731 http://www.baiyc_20201001_0001.cn
baiyc_20201001_0002 18213456732 http://www.baiyc_20201001_0002.cn
baiyc_20201001_0003 18213456733 http://www.baiyc_20201001_0003.cn
3.2、代码实现
package com.zc.hbase.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @作者: zc
* @时间: 2021/3/16 14:11
* @描述: HDFS --> Hbase
*/
public class HbaseSinkerTest {
// 表名
static final String TABLE_NAME = "user_info";
// zookeeper集群链接地址
static final String ZK_CONNECT_STR = "hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181";
static class HbaseSinkMrMapper extends Mapper<LongWritable, Text, Text, Text> {
Text textKey = new Text();
Text textValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String rowkey = fields[0];
String phone = fields[1];
String url = fields[2];
textKey.set(rowkey);
textValue.set(phone+"\t"+url);
context.write(textKey, textValue);
}
}
static class HbaseSinkMrReducer extends TableReducer<Text, Text, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Put put = new Put(key.getBytes());
for (Text value: values) {
String[] fields = value.toString().split("\t");
put.addColumn("base_info".getBytes(), "phone".getBytes(), fields[0].getBytes());
put.addColumn("base_info".getBytes(), "url".getBytes(), fields[1].getBytes());
}
context.write(new ImmutableBytesWritable(key.getBytes()), put);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", ZK_CONNECT_STR);
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 以下这段代码为创建表的代码,表名 flowbean, 列簇叫 f1, 列簇版本数 3
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
TableName tableName = TableName.valueOf(TABLE_NAME);
if (!admin.tableExists(tableName)){ // 如果表不存在,创建表
HTableDescriptor desc = new HTableDescriptor(tableName);
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("base_info".getBytes());
hColumnDescriptor.setValue("VERSIONS", "3");
desc.addFamily(hColumnDescriptor);
admin.createTable(desc);
}
// MR 执行任务
Job job = Job.getInstance(conf);
job.setJarByClass(HbaseSinkerTest.class);
job.setMapperClass(HbaseSinkMrMapper.class);
job.setReducerClass(HbaseSinkMrReducer.class);
TableMapReduceUtil.initTableReducerJob(TABLE_NAME, HbaseSinkMrReducer.class, job);
FileInputFormat.setInputPaths(job, new Path("/testfile/user_info.txt"));
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Mutation.class);
boolean statue = job.waitForCompletion(true);
System.exit(statue ? 0 : 1);
}
}
3.3、jar 包运行
导 jar 包运行与上同。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









