







 本文详细介绍了Apache Flume,一个用于高效、可靠、可用的数据收集系统的开源工具。Flume支持从多种数据源收集数据,通过其灵活的架构实现数据聚合和传输。文章涵盖了Flume的体系结构、核心组件、经典部署方案以及实战案例,展示了如何配置和使用Flume进行数据采集,包括从文件系统到HDFS的传输。此外,文章还提到了Flume与其他数据收集工具如Chukwa、Scribe、Fluentd和Logstash的对比。
本文详细介绍了Apache Flume,一个用于高效、可靠、可用的数据收集系统的开源工具。Flume支持从多种数据源收集数据,通过其灵活的架构实现数据聚合和传输。文章涵盖了Flume的体系结构、核心组件、经典部署方案以及实战案例,展示了如何配置和使用Flume进行数据采集,包括从文件系统到HDFS的传输。此外,文章还提到了Flume与其他数据收集工具如Chukwa、Scribe、Fluentd和Logstash的对比。
大数据辅助工具--Flume 数据采集组件
1、数据收集工具系统产生背景
(1)Hadoop 业务的整体开发流程:
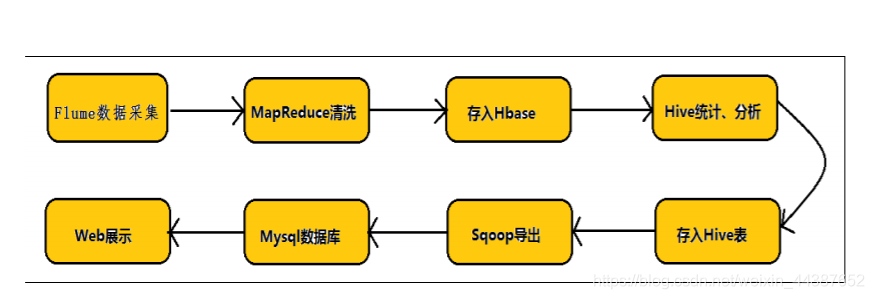
(2)任何完整的大数据平台,一般都会包括以下的基本处理过程:
① 数据采集;
② 数据 ETL;
③ 数据存储;
④ 数据计算/分析;
⑤ 数据展现。
⑥⑦⑧
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
① 数据源多种多样;
② 数据量大,变化快;
③ 如何保证数据采集的可靠性的性能;
④ 如何避免重复数据;
⑤ 如何保证数据的质量。
我们今天就来看看当前可用的一些数据采集的产品,重点关注一些它们是如何做到高可靠,高性能和高扩展。
2、专业的数据收集工具
2.1、Chukwa
Apache Chukwa 是 Apache 旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce 来构建(显而易见,它用 Java 来实现),提供扩展性和可靠性。Chukwa 同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 Github 的更新是差不多 10 年前左右了。可见该项目应该已经不活跃了。
官网:http://chukwa.apache.org/
2.2、Scribe
Scribe 是 Facebook 开源的日志收集系统,在 Facebook 内部已经得到的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是 NFS,HDFS,或者其他分布式文件系统等)上,以便于进行集中统计分析处理。
官网:https://www.scribesoft.com/
2.3、Fluentd
Fluentd 是另一个开源的数据收集框架。Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和很好的扩展性。
官网:https://www.fluentd.org/
2.4、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch,Logstash,Kibana)中的那个 L。几乎在大部分的情况下 ELK 作为一个栈是被同时使用的。所有当你的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。Logstash 用 JRuby 开发,所以运行时依赖 JVM。
官网:https://www.elastic.co/cn/products/logstash
2.5、Apache Flume
Flume 是 Apache 旗下,开源,高可靠,高扩展,容易管理,支持客户扩展的数据采集系统。Flume 使用 JRuby 来构建,所以依赖 Java 运行环境。Flume 最初是由 Cloudera 的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。
官网:http://flume.apache.org/
3、Flume 概述
3.1、Flume 概念
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
Flume 是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据,同时,Flume 提供对数据的简单处理,并写到各种数据接收方的能力。
(1)Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,和 Sqoop 同属于数据采集系统组件,但是 Sqoop 用来采集关系型数据库数据,而 Flume 用来采集流动型数据。
(2)Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数据的采集,它支持从很多数据源聚合数据到 HDFS。
(3)一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景。
(4)Flume 最初由 Cloudera 开发,在 2011 年贡献给了 Apache 基金会,2012 年变成了 Apache的顶级项目。Flume OG(Original Generation)是 Flume 最初版本,后升级换代成 Flume NG(Next/New Generation)。
(5)Flume 的优势:可横向扩展、延展性、可靠性。
3.2、Flume 版本介绍
Flume 在 0.9.x and 1.x 之间有较大的架构调整,1.x 版本之后的改称 Flume NG,0.9.x 的称为 Flume OG。

官网文档:http://flume.apache.org/FlumeUserGuide.html
4、Flume 体系结构/核心组件
4.1、概述
Flume 的数据流由事件(Event)贯穿始终。Event 是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获 Event 后会进行特定的格式化,然后 Source 会把 Event 推入(单个或多个) Channel 中。你可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或者把事件推向另一个 Source。
Flume 以 agent 为最小的独立运行单位。一个 agent 就是一个 JVM。单个 agent 由 Source、Sink 和 Channel 三大组件构成,如下图:
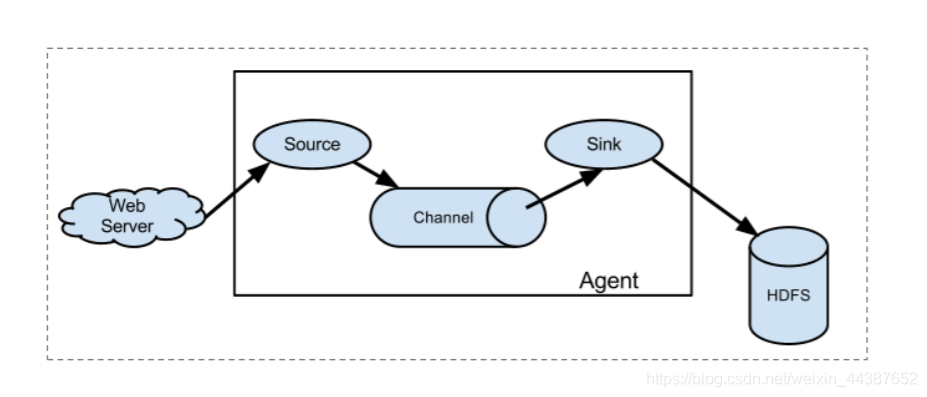
| 组件 | 功能 |
|---|---|
| Agent | 使用 JVM 运行 Flume。每台机器运行一个 agent,但是可以在一个 agent 中包含多个 sources 和 sinks。 |
| Client | 生产数据,运行在一个独立的线程。 |
| Source | 从 Client 收集数据,传递给 Channel。 |
| Sink | 从 Channel 收集数据,运行在一个独立线程。 |
| Channel | 连接 sources 和 sinks,这个有点像一个队列。 |
| Events | 可以是日志记录、avro 对象等。 |
4.2、Flume 核心组件
4.2.1、Event
Event(事件)是 Flume 数据传输的基本单元。Flume 以事件的形式将数据从源头传送到最终的目的。
Event 由可选的 header 和载有数据的一个 byte array 构成。
(1)载有的数据度 flume 是不透明的。
(2)Header 是容纳了 key-value 字符串对的无序集合,key 在集合内是唯一的。
(3)Header 可以在上下文路由中使用扩展。
4.2.2、Client
Client 是一个将原始 log 包装成 events 并且发送他们到一个或多个 agent 的实体。目的是从数据源系统中解耦 Flume,在 flume 的拓扑结构中不是必须的。
Client 实例:
(1)flume log4j Appender。
(2)可以使用 Client SDK(org.apache.flume.api)定制特定的 Client。
4.2.3、Agent
agent 是 flume 流的基础部分。一个 Agent 包含 source,channel,sink 和其他组件。它利用这些组件将 events 从一个节点传输到另一个节点或最终目的地。 flume 为这些组件提供了配置,声明周期管理,监控支持。
4.2.4、Source
Source 负责接收 event 或通过特殊机制产生 event,并将 events 批量的放到一个或多个 Channel,包含 event 驱动和轮询两种类型。
不同类型的 Source:
(1)与系统集成的 Source:Syslog、Netcat、监测目录池。
(2)自动生成事件的 Source:Exec。
(3)用于 Agent 和 Agent 之间通信的 IPC source:avro、thrift。
(4)source 必须至少和一个 channel 关联。
4.2.5、Agent 之 Channel
Channel 位于 Source 和 Sink 之间,用于缓存进来的 event。当 sink 成功的将 event 发送到下一个的 channel 或最终目的后, event 从 channel 删除。
不同的 channel 提供的持久化水平也是不一样的。
(1)Memory channel:volatile (不稳定的)。
(2)File Channel:基于 WAL(预写式日志 Write-Ahead logging)实现。
(3)JDBC channel:基于嵌入式 database 实现。
channel 支持事务,提供较弱的顺序保证,可以和任何数量的 source 和 sink 工作。
4.2.6、Agent 之 Sink
Silk 负责将 event 传输到下一跳或最终目的地,成功后将 event 从 channel 移除。
不同类型的 silk:
&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









