




 本文深入探讨了伪共享现象,解释了当多个线程试图同时访问不同变量但位于同一缓存行时,如何导致性能下降。通过三种访问数组的方法对比,展示了如何使用填充数据和JDK 1.8的@Contended注解来避免伪共享,显著提升访问速度。
本文深入探讨了伪共享现象,解释了当多个线程试图同时访问不同变量但位于同一缓存行时,如何导致性能下降。通过三种访问数组的方法对比,展示了如何使用填充数据和JDK 1.8的@Contended注解来避免伪共享,显著提升访问速度。
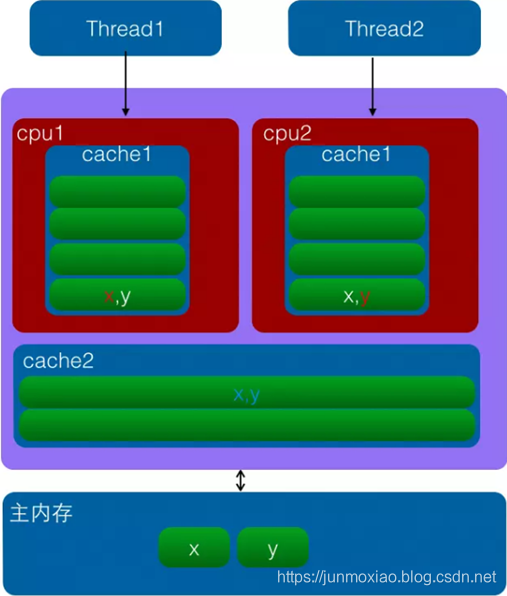
一图了解伪共享:
线程1在cpu1工作想改变数值x,线程2在cpu2工作想改变数值y。这时,系统调度的时候就不会让线程1和线程2同时运行,因为一行是cpu缓存修改的最小单位。这种情况就是伪共享。
下面示例分别用三种不同的方式进行访问数组并比较快慢:
第一种单纯地访问数据。
第二种在访问的值左右填满无用数据,使得它独占一行。
第三种使用jdk1.8的@sun.misc.Contended注解。
public class FalseSharing implements Runnable {
public final static int NUM_THREADS =
Runtime.getRuntime().availableProcessors();
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
public FalseSharing(final int arrayIndex){
this.arrayIndex = arrayIndex;
}
//用于比较访问数据的时间
public void run(){
long i = ITERATIONS + 1;
while (0 != --i){
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public volatile long value = 0L;
}
// long padding避免false sharing
// 按理说jdk7以后long padding应该被优化掉了,但是从测试结果看padding仍然起作用
public final static class VolatileLongPadding {
public volatile long p1, p2, p3, p4, p5, p6, p7;
public volatile long value = 0L;
public volatile long q1, q2, q3, q4, q5, q6, q7;
}
//jdk8新特性,Contended注解避免false sharing
@sun.misc.Contended
public final static class VolatileLongAnno {
public volatile long value = 0L;
}
//数组里存放的是类
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
// private static VolatileLongPadding[] longs = new VolatileLongPadding[NUM_THREADS];
// private static VolatileLongAnno[] longs = new VolatileLongAnno[NUM_THREADS];
static{
/*将数组初始化*/
for (int i = 0; i < longs.length; i++){
longs[i] = new VolatileLong();
// longs[i] = new VolatileLongPadding();
// longs[i] = new VolatileLongAnno();
}
}
public static void main(final String[] args) throws Exception{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++){
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads){
t.start();
}
//等待所有线程执行完成,避免主线程在其它线程前结束
for (Thread t : threads){
t.join();
}
}
}
结果:
第一种:
duration = 26205176237
第二种:
duration = 7477267155
第三种:
duration = 7589874226
可以看到第二种和第三种在访问速度上有数量级上的提升。
点击这里,查看更多关于伪共享的知识。


















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









