




JDK 内置并发队列
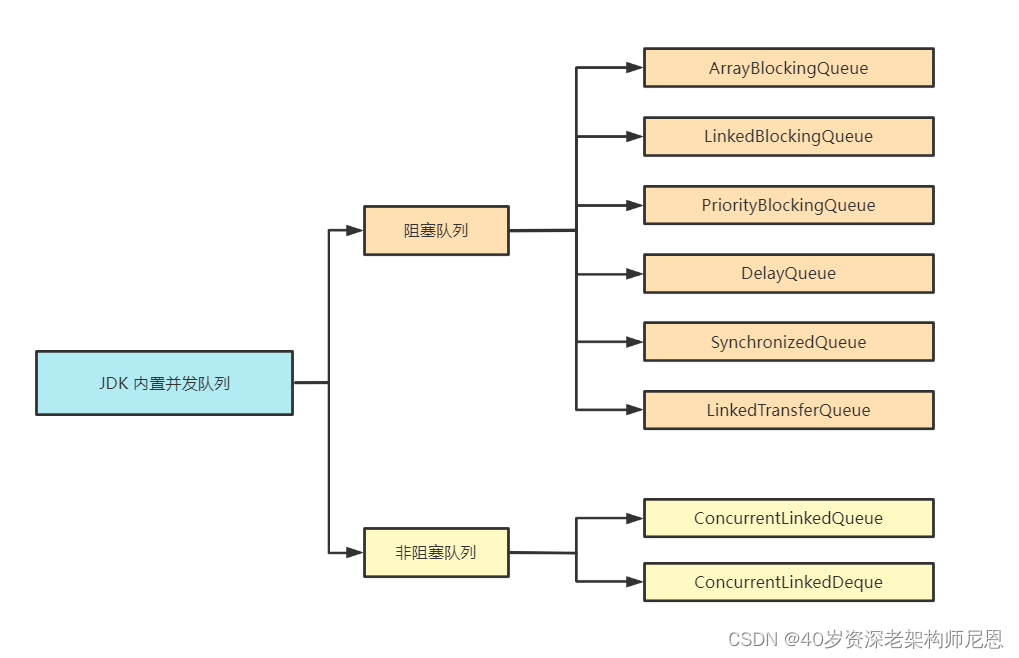
JDK 内置并发队列按照实现方式可以分为阻塞队列和非阻塞队列两种类型,阻塞队列是基于锁实现的,非阻塞队列是基于 CAS 操作实现的。JDK 中包含多种阻塞和非阻塞的队列实现,如下图所示。
队列是一种 FIFO(先进先出)的数据结构,JDK 中定义了 java.util.Queue 的队列接口,与 List、Set 接口类似,java.util.Queue 也继承于 Collection 集合接口。
此外,JDK 还提供了一种双端队列接口 java.util.Deque,我们最常用的 LinkedList 就是实现了 Deque 接口。
下面我们简单说说上图中的每个队列的特点,并给出一些对比和总结。
阻塞队列
阻塞队列在队列为空或者队列满时,都会发生阻塞。阻塞队列自身是线程安全的,使用者无需关心线程安全问题,降低了多线程开发难度。
阻塞队列主要分为以下几种:
-
ArrayBlockingQueue:
最基础且开发中最常用的阻塞队列,底层采用数组实现的有界队列,初始化需要指定队列的容量。ArrayBlockingQueue 是如何保证线程安全的呢?
它内部是使用了一个重入锁 ReentrantLock,并搭配 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。
从队列读取数据时,如果队列为空,那么会阻塞等待,直到队列有数据了才会被唤醒。
如果队列已经满了,也同样会进入阻塞状态,直到队列有空闲才会被唤醒。
-
LinkedBlockingQueue:
内部采用的数据结构是链表,队列的长度可以是有界或者无界的,初始化不需要指定队列长度,默认是 Integer.MAX_VALUE。
LinkedBlockingQueue 内部使用了 takeLock、putLock两个重入锁 ReentrantLock,以及 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。
采用读锁和写锁的好处是可以避免读写时相互竞争锁的现象,所以相比于 ArrayBlockingQueue,LinkedBlockingQueue 的性能要更好。
-
PriorityBlockingQueue:
采用最小堆实现的优先级队列,队列中的元素按照优先级进行排列,每次出队都是返回优先级最高的元素。PriorityBlockingQueue 内部是使用了一个 ReentrantLock 以及一个条件变量 Condition notEmpty 来控制并发访问,
因为 PriorityBlockingQueue 是无界队列,所以不需要 notFull ,每次 put 都不会发生阻塞。PriorityBlockingQueue 底层的最小堆是采用数组实现的,当元素个数大于等于最大容量时会触发扩容,
在扩容时会先释放锁,保证其他元素可以正常出队,然后使用 CAS 操作确保只有一个线程可以执行扩容逻辑。
-
DelayQueue,
一种支持延迟获取元素的阻塞队列,常用于缓存、定时任务调度等场景。
DelayQueue 内部是采用优先级队列 PriorityQueue 存储对象。
DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法。向队列中存放元素的时候必须指定延迟时间,只有延迟时间已满的元素才能从队列中取出。
-
SynchronizedQueue,
又称无缓冲队列。
比较特别的是 SynchronizedQueue 内部不会存储元素。与 ArrayBlockingQueue、LinkedBlockingQueue 不同,SynchronizedQueue 直接使用 CAS 操作控制线程的安全访问。
其中 put 和 take 操作都是阻塞的,每一个 put 操作都必须阻塞等待一个 take 操作,反之亦然。
所以 SynchronizedQueue 可以理解为生产者和消费者配对的场景,双方必须互相等待,直至配对成功。
在 JDK 的线程池 Executors.newCachedThreadPool 中就存在 SynchronousQueue 的运用,对于新提交的任务,如果有空闲线程,将重复利用空闲线程处理任务,否则将新建线程进行处理。
-
LinkedTransferQueue
一种特殊的无界阻塞队列,可以看作 LinkedBlockingQueues、SynchronousQueue(公平模式)、ConcurrentLinkedQueue 的合体。
与 SynchronousQueue 不同的是,LinkedTransferQueue 内部可以存储实际的数据,当执行 put 操作时,如果有等待线程,那么直接将数据交给对方,否则放入队列中。与 LinkedBlockingQueues 相比,LinkedTransferQueue 使用 CAS 无锁操作进一步提升了性能。
非阻塞队列
说完阻塞队列,我们再来看下非阻塞队列。非阻塞队列不需要通过加锁的方式对线程阻塞,并发性能更好。
JDK 中常用的非阻塞队列有以下几种:
-
ConcurrentLinkedQueue,
它是一个采用双向链表实现的无界并发非阻塞队列,它属于 LinkedQueue 的安全版本。ConcurrentLinkedQueue 内部采用 CAS 操作保证线程安全,这是非阻塞队列实现的基础,
相比 ArrayBlockingQueue、LinkedBlockingQueue 具备较高的性能。
-
ConcurrentLinkedDeque,
也是一种采用双向链表结构的无界并发非阻塞队列。
与 ConcurrentLinkedQueue 不同的是,ConcurrentLinkedDeque 属于双端队列,
它同时支持 FIFO 和 FILO 两种模式,可以从队列的头部插入和删除数据,也可以从队列尾部插入和删除数据,适用于多生产者和多消费者的场景。
BlockingQueue阻塞队列超级接口
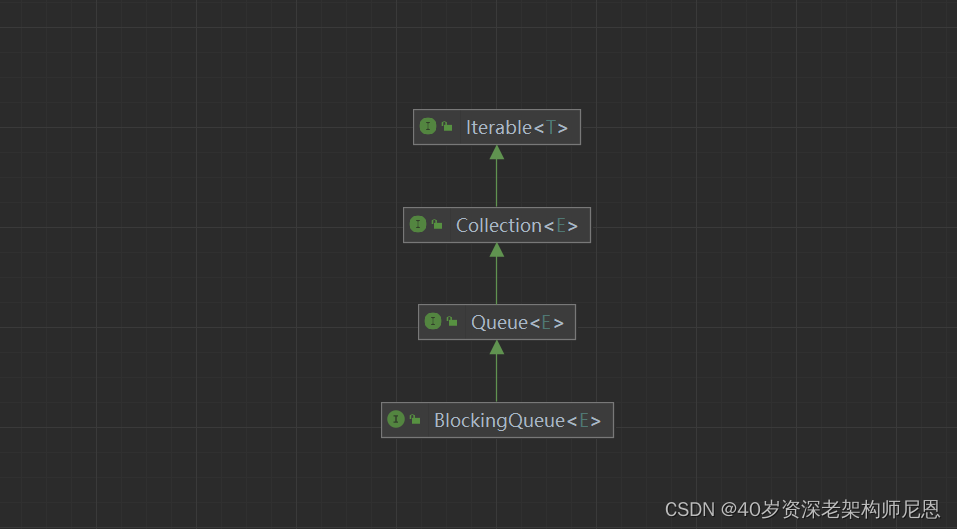
平时开发中使用频率最高的是 BlockingQueue。实现一个阻塞队列需要具备哪些基本功能呢?
下面看 BlockingQueue 的接口继承关系,如下图所示。
下面看 BlockingQueue 的接口的各种实现子类,如下图所示。

BlockingQueue 实现子类太多,图里放不下,还请大家通过IDEA工具,自行查看。
下面看 BlockingQueue 的接口的 抽象方法,如下图所示。
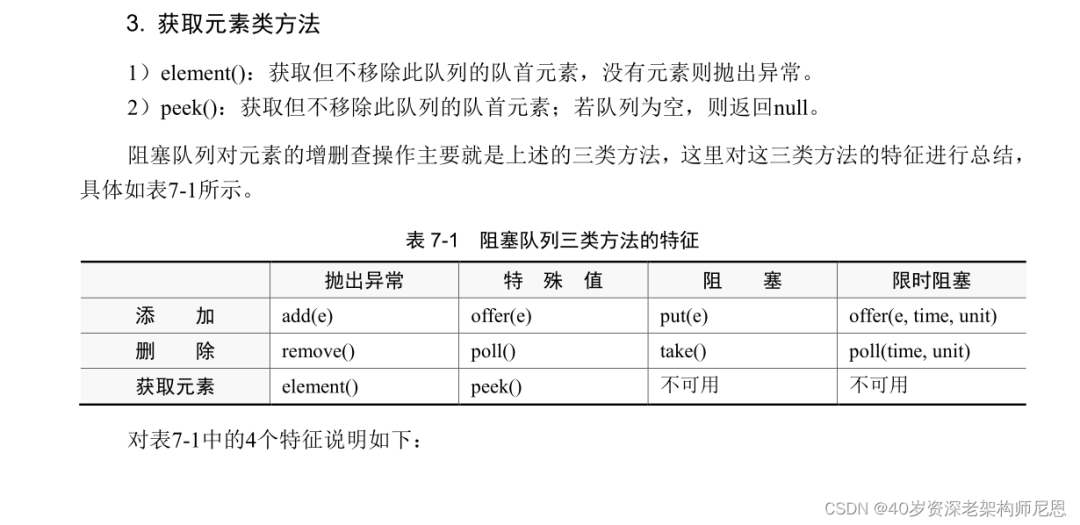
我们可以通过下面一张表格,对上述 BlockingQueue 接口的具体行为进行归类。
Java内置队列的问题
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded | 加锁 | arraylist |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedlist |
| ConcurrentLinkedQueue | unbounded | 无锁 | linkedlist |
| LinkedTransferQueue | unbounded | 无锁 | linkedlist |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









