






写论文的逻辑:
introduction
引出通用处理器的弊端和数据流结构,
然后指出数据流结构处理器的性能和传输效率有关系,传输效率高,就能够让ALU不空闲。
在NoC中,数据包的传输有有特点:多终点、高喷射率、性能对延迟敏感。
所以支持组播和输出缓冲区(output buffer structure)和数据包不分片(non-flit packet format)。
作者的意思是,输出缓冲区可以缓存暂时没有办法马上输出的数据包,然后每个方向的输出都会有一个自己的输出缓冲区,这样在输出的部分缓存数据包,能够提供高带宽和低延迟,对数据流结构Noc很有吸引力。
但是这样会导致数据包复制之后再发往输出缓冲区,而每个数据包不同的只有目的地址,造成浪费。
buffer的有效利用还和数据包的大小有关。1、buffer的位宽是固定的,如果超出了位宽,那么就得存到下一个地址;2、在传输过程中,由于分片(例如说MTU不支持等情况),也会导致带宽利用率越来越小。
作者提出解决方案:1、当组播数据包要被发送到不同端口的时候,会先发送到shared buffer,它只存原包,节省了buffer空间。2、shared buffer同时存放了几个bit的有效位,包括:组播包去往的目标地址的有效位,改表项在shared buffer的索引。
好处:1、在网络负载不均衡的情况下,原包在shared buffer存着,这样输入端口如果堵住(原因:某个输出端口堵住了,输入端口不能接收数据包,如果输入端口还接收数据包,又没有buffer兜住,就会导致丢包)了,依旧可以进行组播的复制,复制到别的输出端口,从而不会浪费带宽。2、输入的数据包如果能够合并,也会在shared buffer合并,减少buffer的利用率。
Section 2 background of dataflow architecture
引出了dataflow process unit (DPU)数据流处理单元的概念。画了一张图讲了DPU架构的典型实现。
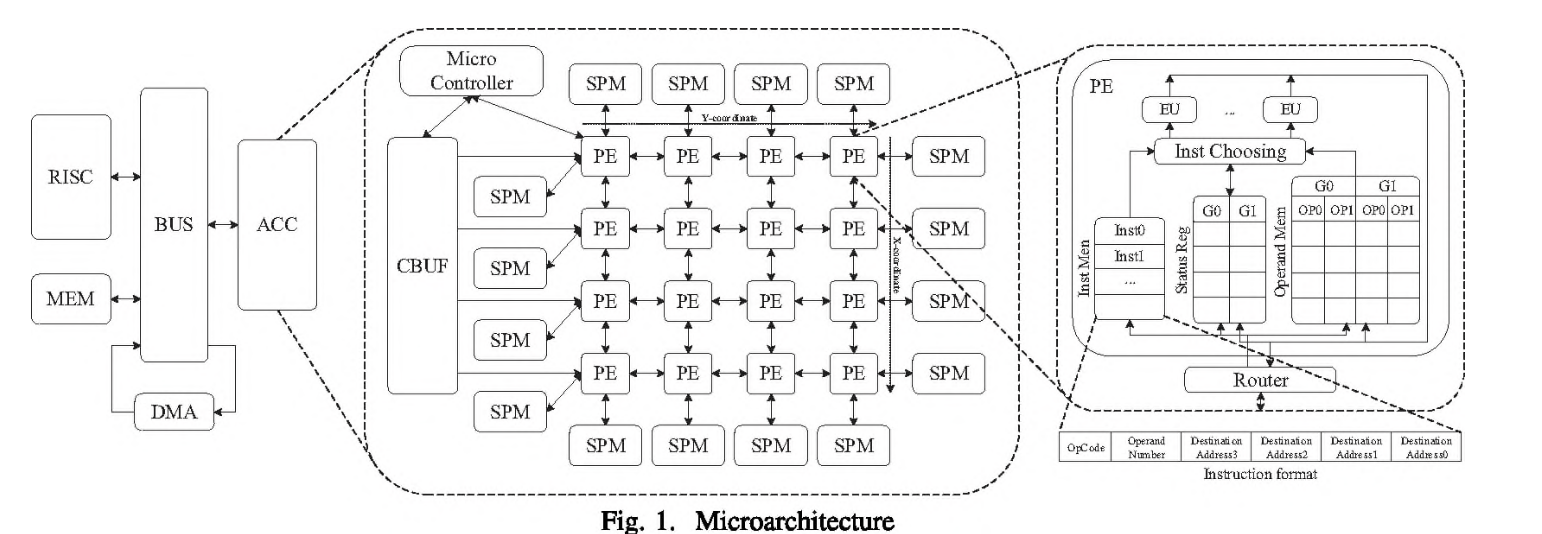
目的是为了表明,论文设计的架构是基于DPU router的架构做的优化。并在这个基础上增加了output buffer和不用对组播数据包进行拆分的设计(只存一个原包),从而实现增加吞吐量和最小化传输延迟。
然后对比了输入缓冲和输出缓冲,指出输出缓冲,能够很好的解决输入缓冲区的队头阻塞问题,不会因为某个输出端口堵了,然后就造成整个输入缓冲区全部都堵住的情况。
section 3 motivation
按照平常的数据包拆分方式,会把整个数据包都复制一份,然后发送到输出缓冲区,但是每个数据包的区别,仅仅是目标地址。网络数据包拆分的越多,输出buffer的资源就会被浪费的越多。然后剩余的buffer的量,又和路由器的性能和效率息息相关,所以buffer空间的浪费,减少了“采用输出缓冲区的路由器”的效率。
所以作者的解决方案是数据共享。具体是:1、低利用率的buffer可以分享空间给高利用率的buffer;2、同一个目的地址,只存原包,只是目的地址不一样。
section 4 MRSB:MULTICAST ROUTER USING SHARED-BUFFER
本章讲的是
参考文献
Li Y, Wu M, Li W, et al. An efficient multicast router using shared-buffer with packet merging for dataflow architecture[C]//2020 14th IEEE/ACM International Symposium on Networks-on-Chip (NOCS). IEEE, 2020: 1-8.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









