







 本文探讨seq2seq模型在机器翻译中的应用,通过将输入序列编码并用解码器生成输出序列。介绍如何使用RNN作为encoder和decoder,并讨论贪心搜索与beam search的区别。此外,文章还深入解释了注意力模型的原理,以解决长文本序列信息丢失的问题,允许解码器根据自身状态选择性地关注encoder的输出,提高翻译质量。
本文探讨seq2seq模型在机器翻译中的应用,通过将输入序列编码并用解码器生成输出序列。介绍如何使用RNN作为encoder和decoder,并讨论贪心搜索与beam search的区别。此外,文章还深入解释了注意力模型的原理,以解决长文本序列信息丢失的问题,允许解码器根据自身状态选择性地关注encoder的输出,提高翻译质量。
seq2seq
seq2seq在机器翻译等领域十分好用。
我们将模型分成两部分,首先构造一个RNN充当encoder,将汉语句子依次作为输入,生成一个中间状态。
然后构造另一个RNN充当decoder。初始输入x是0,初始状态是encoder的输入。接下来每一次的输入x都是上次的输出,直到输出终止符算法停止,得到翻译出来的语句。

我们假设最终得到y1y2y3y4…yn这个翻译结果。我们希望得到在原文X的前提下。P(y1y2y3y4…yn|X)最大。即我们的输出拥有最大的概率。decoder第一次的输出可以得到P(y1|X), 第二次输出得到的是P(y2|Xy1),这二者的乘积是P(y1y2|X)。因此可以看出,P(y1y2y3y4…yn|X)就等于每一次decoder输出的累积,我们希望这个累积最大。
我们直到如果直接选择贪心的方式,每次直接生成最大概率的单词,组合起来的结果可能不是最优的(因为后面的概率不一定大),因此往往采用beam search的方式进行搜索。
beam search本质上是一个近似搜索算法,我们规定一个beam width = 10。decoder第一次的输出中,我保留前10个最大的作为备选序列。在第二次输出中,我会得到10 * 字典总数个输出,在这些输出里我再挑最大的10个作为备选序列。我们相当于每次搜索只维护10个当前可能最大的序列,最终得到相对更优答案。
注意力模型
由于RNN本身不能记住太长的内容,因此用简单的seq2seq,当文本过长时,我们的encoder提供的初始值就记不了太多的东西。翻译效果就会打折扣。
这时候我们想到,之前的decoder是自产自销型,encoder只能提供一个初始状态,那如果我们把encoder的所有时间的激活函数都提供给decoder,让decoder跟据当前状态自由选择去利用哪些信息,不就可以解决文本过长的问题了吗。这就产生了注意力模型。
模型的主要新思想就是要建立注意力的计算方式,从而确定每次decoder的输入到底和谁有关。
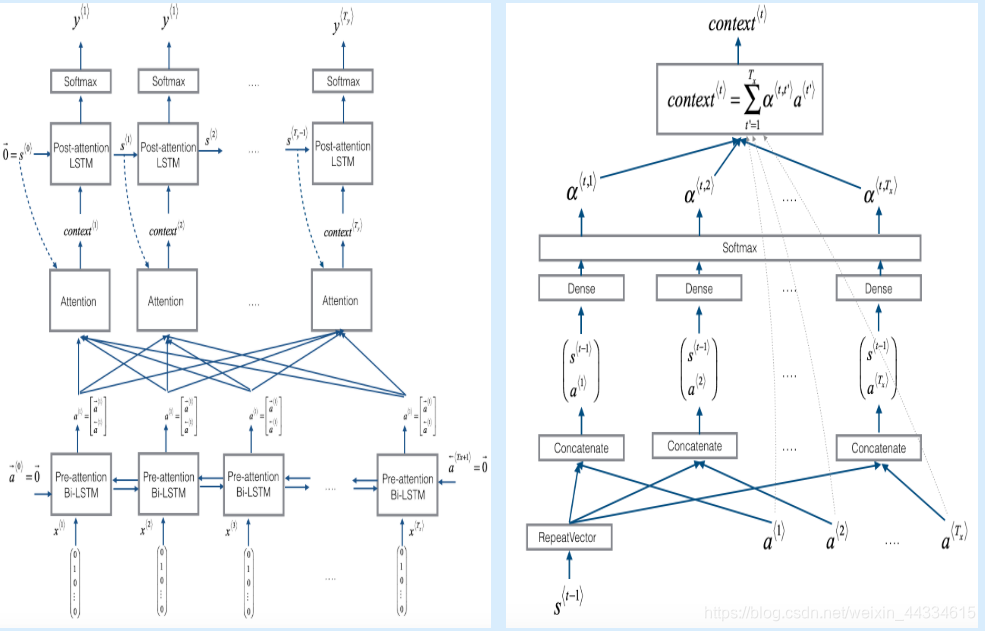
左面的图是整个模型的结构。最底下的是一层双向RNN,相当于之前的encoder,他给出所有时间节点的输出A。随后在decoder的计算中,每一次的输入X都和所有的encoder输出有关。
右面描述了如何确定注意力。可以看到,每一次注意力的计算和decoder的状态S和encoder的输出A有关系。(这符合道理,decoder的注意力应该由自己当前的状态决定)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









