







 本文探讨了word embedding的概念,它解决了one-hot表示的局限性,通过将单词映射到低维特征空间,使具有相似含义的词靠近。介绍了word2vec的skip gram模型以及解决softmax计算成本高的负采样技术,并提到了GloVe方法,该方法利用全局共现矩阵优化词向量的损失函数,以增强词与词之间的相关性表示。
本文探讨了word embedding的概念,它解决了one-hot表示的局限性,通过将单词映射到低维特征空间,使具有相似含义的词靠近。介绍了word2vec的skip gram模型以及解决softmax计算成本高的负采样技术,并提到了GloVe方法,该方法利用全局共现矩阵优化词向量的损失函数,以增强词与词之间的相关性表示。
word embedding
之前我们一直用one-hot的形式来表示每一个词。但是随着单词集的扩充,one-hot的维度会越来越大,而且这样表示不能体现出词的关系。所以这里提出word embedding
word embedding本质上是抓取每个词的各种特征。相当于将m维的one-hot空间的单词映射到n维的特征空间中的值。特征空间满足:具有相似特征(例如水果)的词会聚在一起。具有相同关系的词会呈现出平行四边形的性质(男人、女人;国王、皇后的embedding向量偏差大致相同)
训练得到word embedding
word2vec : skip gram
如下构建一个假任务:
输入:单词w
输出:对于所有的单词表,每个单词出现在w上下文的概率
如下构建模型:
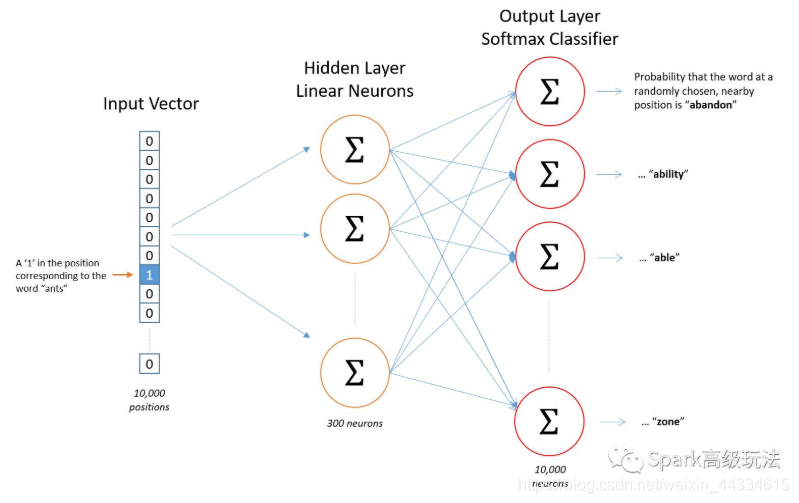
首先由w的one-hot向量生成中间的embedding向量,然后利用softmax,算出每一个单词出现在上下文的概率。
第一步的embedding权重和第二步的softmax权重都需要训练,然而我们只想要embedding的权重。
在训练的过程中,我们如下构建训练集:找到一句话,取出一个单词w,在w的左右某个范围内找到单词c,w作为输入,c作为目标输出,利用交叉熵进行梯度下降。
这个方法最大的问题在于,softmax的计算代价过大。
负采样:
为了解决skip gram softmax计算代价过大的问题,我们采用负采样的方法进行优化。
对于每一组训练集数据,我们如下构造:首先按照之前的方法选取一对正例(w,c)代表w的上下文存在c。接着我们在字符集中随机选择k个单词b,每一对(w,b)是一对反例,代表w的上下文不存在b。区别于之前的softmax函数,我们对字典中的每一个单词构建一个自己sigmoid函数。这样一来,我们每一次训练只需要影响(k+1)个sigmoid函数的权重,而不需要计算更新整个softmax的权重
选取k个单词b时,有一定的技巧,通常我们统计每一个单词在语料中出现的频率f,利用f计算如下概率:
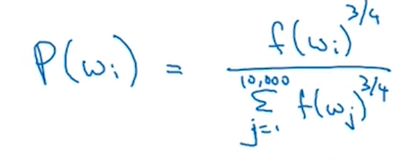
利用这个概率值挑选k个单词b作为反例
GloVe
首先构造共现矩阵X
Xij代表第i个单词和第j个单词在整个语料中互为上下文的次数
利用X,我们试图构建embedding矩阵w,希望优化满足下面的损失函数使之最小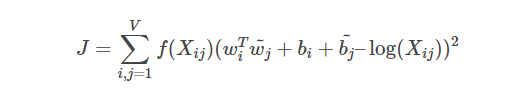
我们可以看到,这个损失函数的本质是希望当Xij比较大时,Wi 和 Wj 的内积也要大。
这个方法相对于上面的方法的好处在于:对于skip gram,我们每次只能着眼于某个单词的上下文。但是对于GloVe,我的X里面统计的可是全局信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









