




 博客介绍了深度学习相关内容,包括pooling的两种方式、language model的matrix factorization和NN方法、spatial transformer layer的插值法等。还提及注意力模型、Neural Turiing Machine,以及解决注意力模型问题的方法,如sampling、beam search等,最后介绍了pointer network及其应用。
博客介绍了深度学习相关内容,包括pooling的两种方式、language model的matrix factorization和NN方法、spatial transformer layer的插值法等。还提及注意力模型、Neural Turiing Machine,以及解决注意力模型问题的方法,如sampling、beam search等,最后介绍了pointer network及其应用。
- pooling 有两种方式,一种是把同一感受野的输出pooling,起到的是maxout network的作用,即把同一感受野通过不同filter的结果进行max out以使模型能辨别多样性输入;另一种是把同一filter 的输出pooling,起到的是down sampling的作用
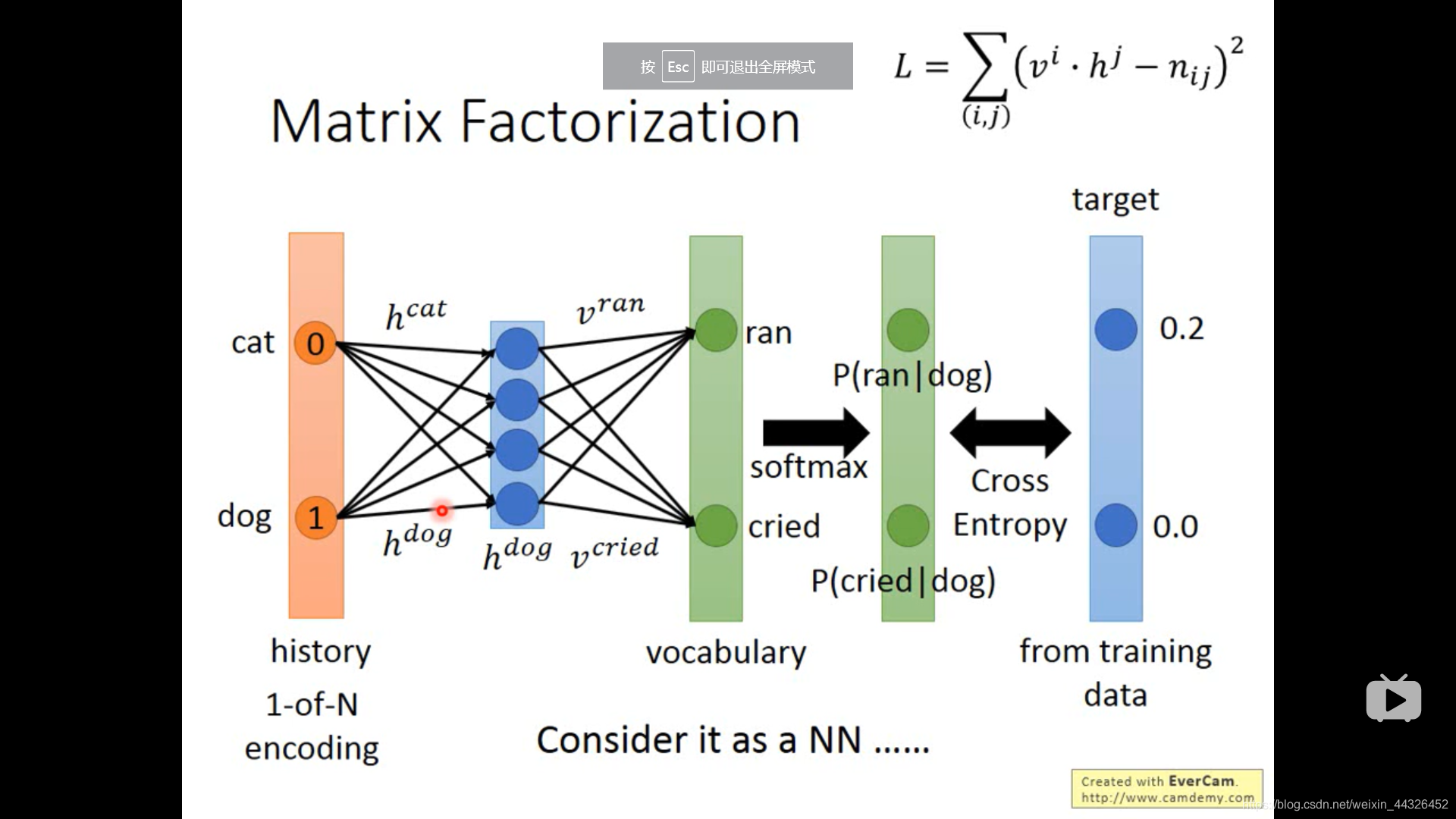
- language model 中的matrix factorization 和 NN 方法
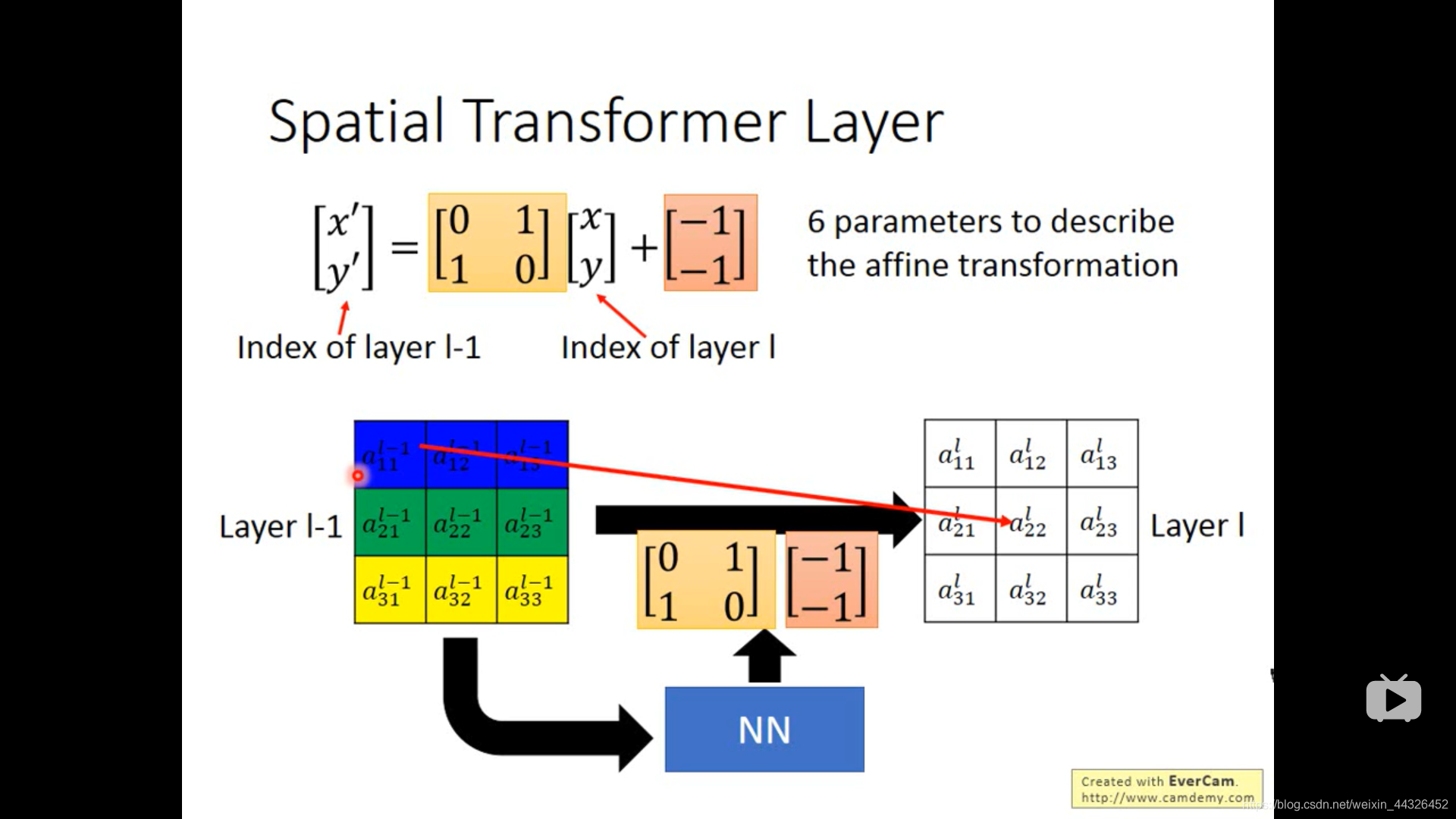
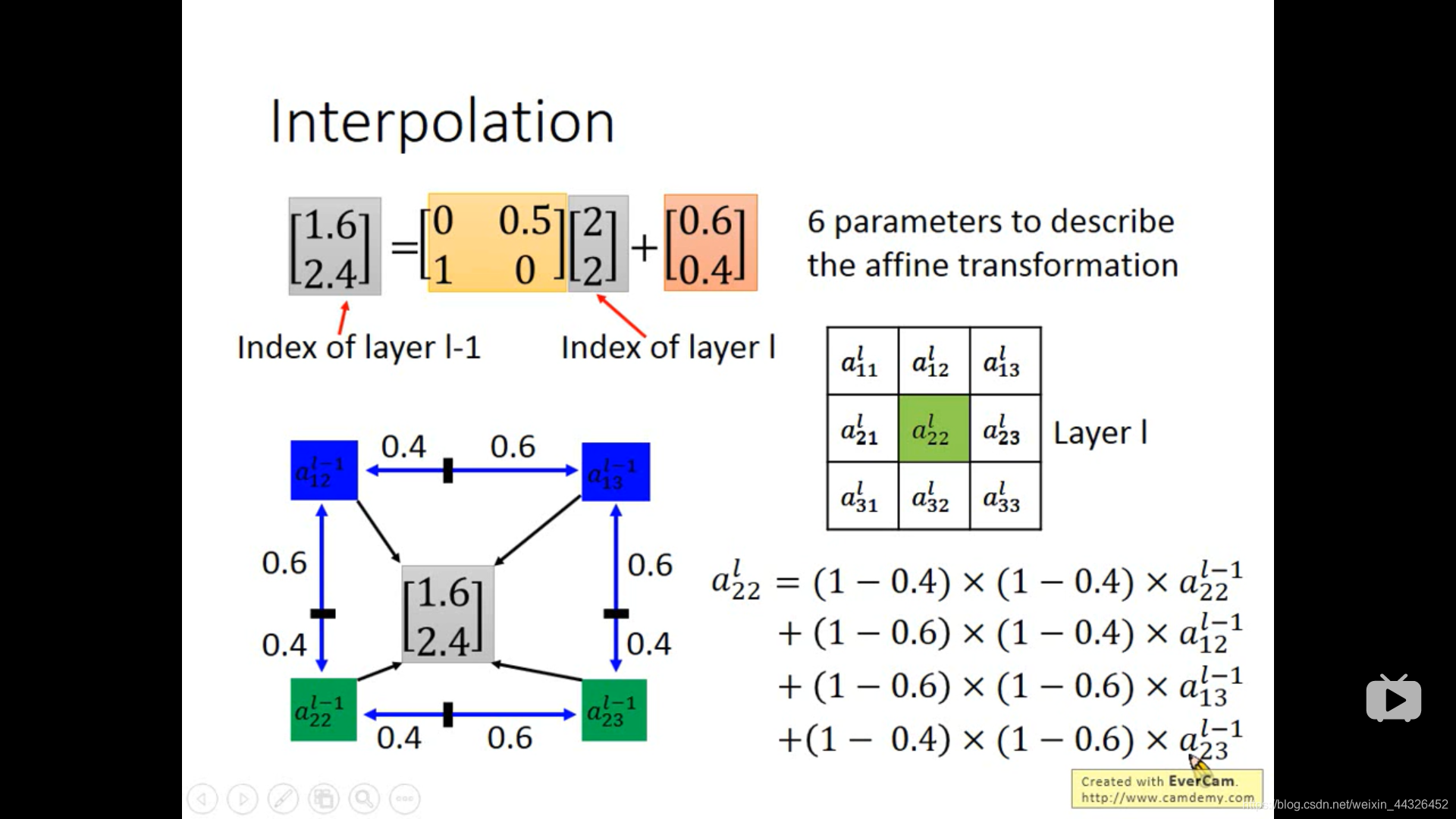
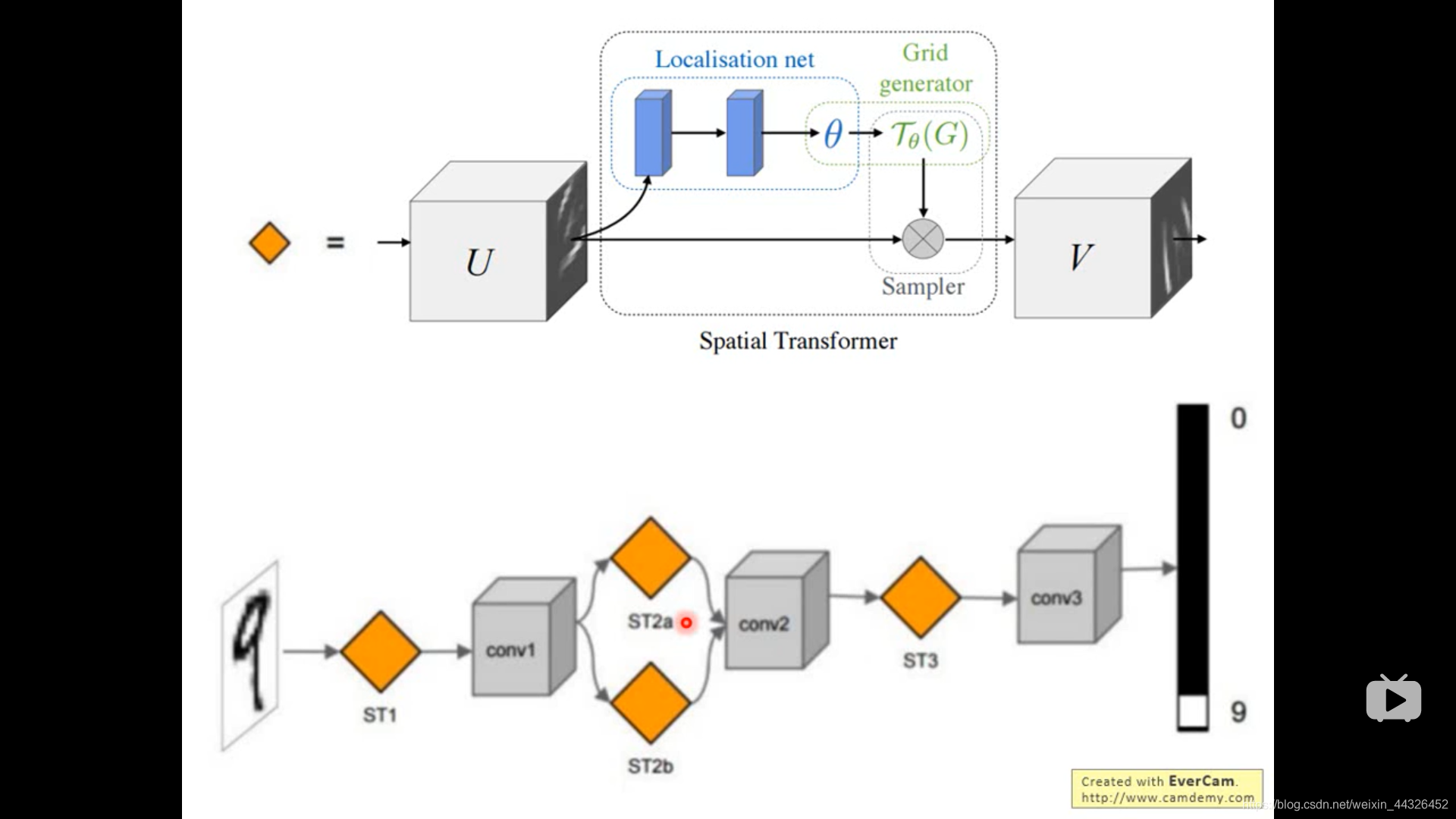
- spatial transformer layer ,计算结果出现小数,用插值法
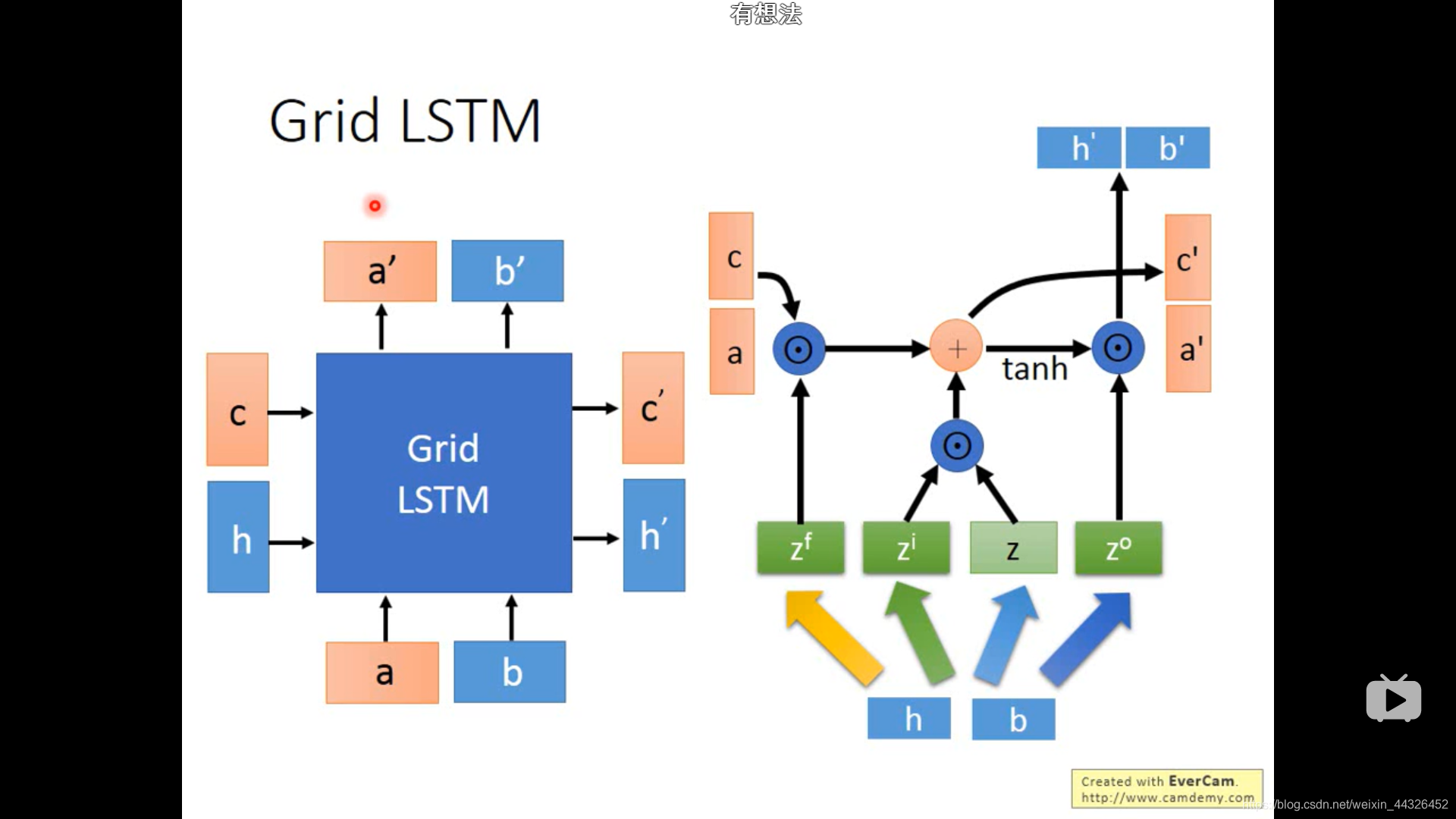
- Grid LSTM
- Recursive network
-
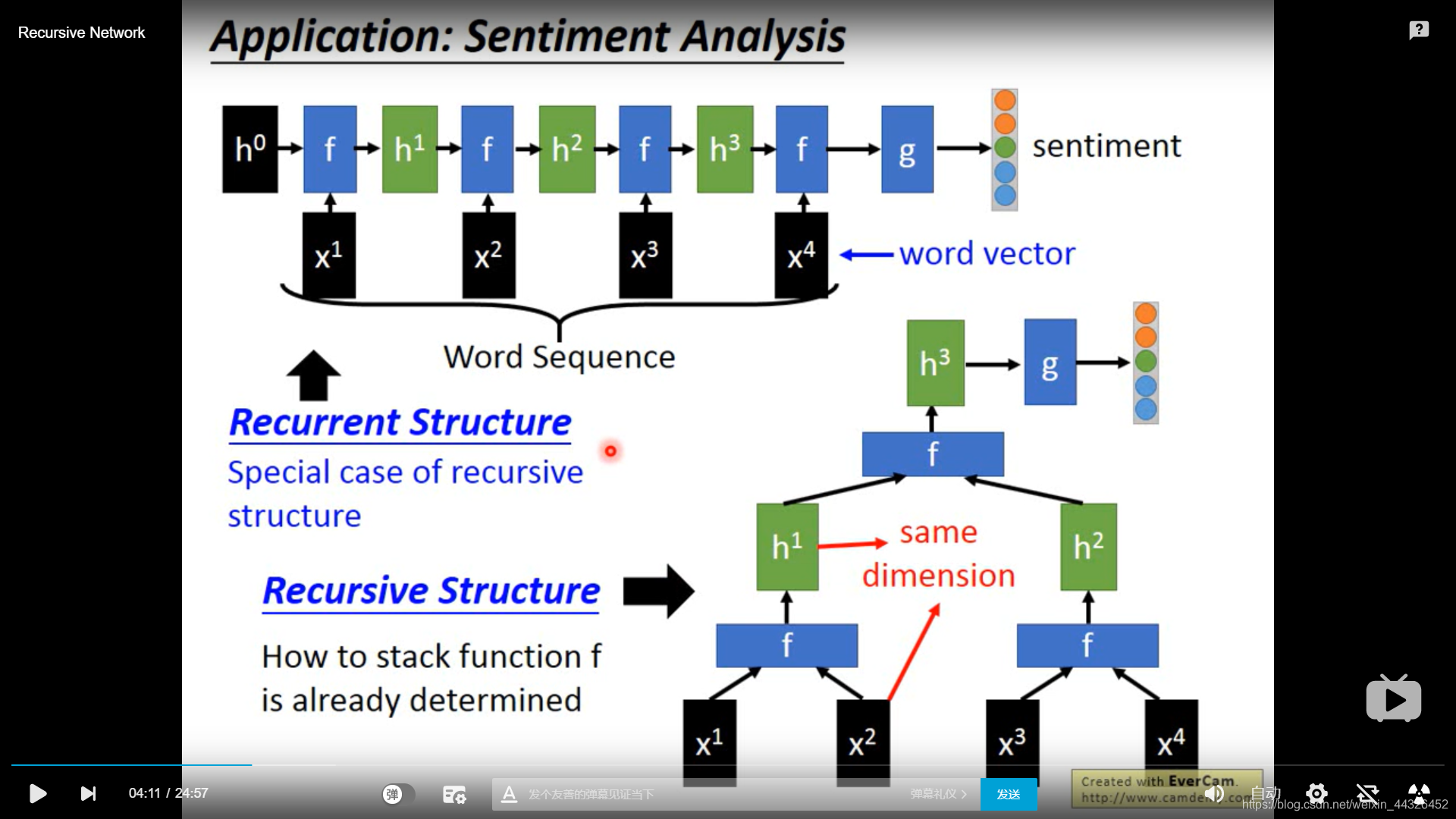
具有递归的结构 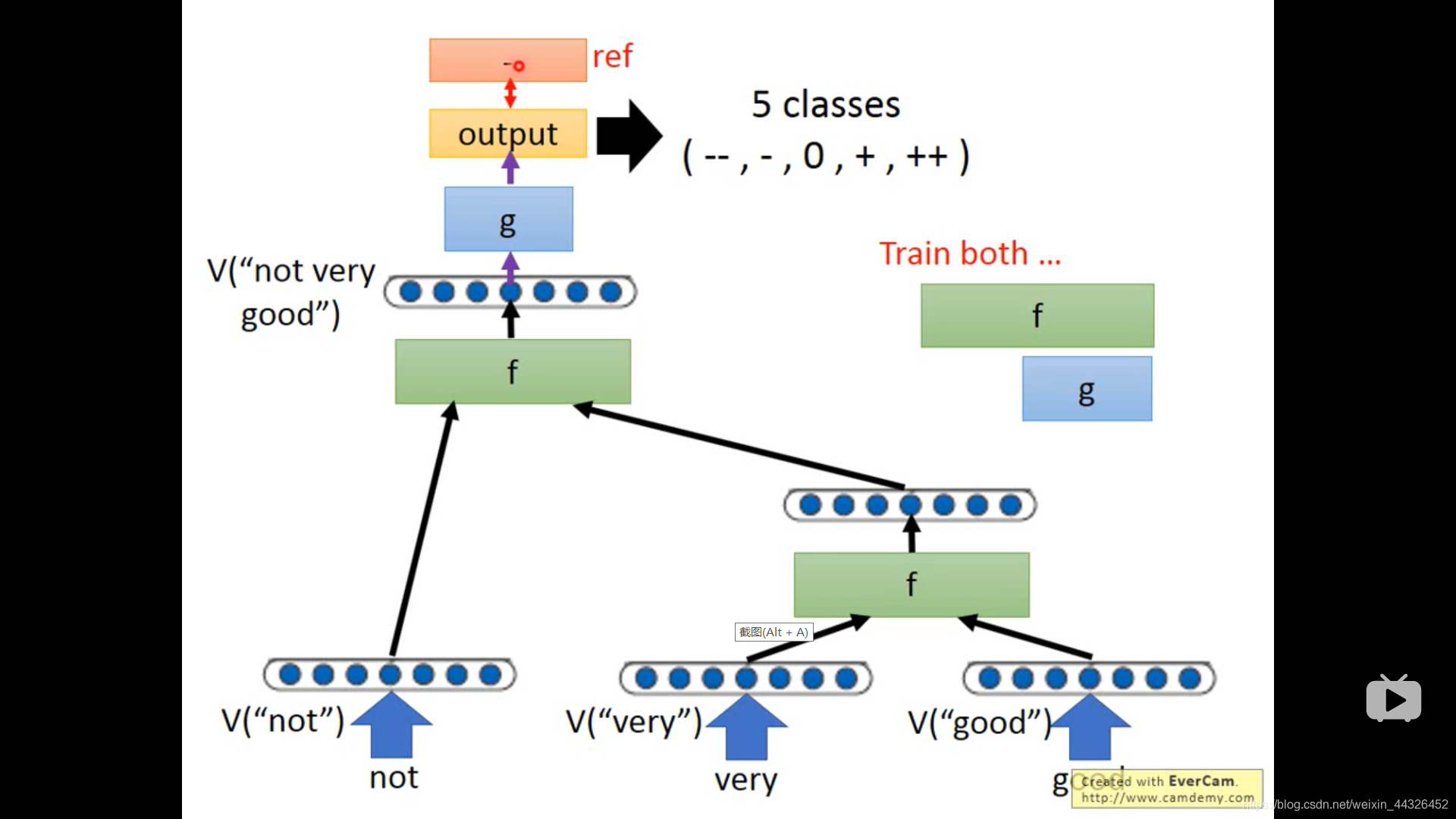
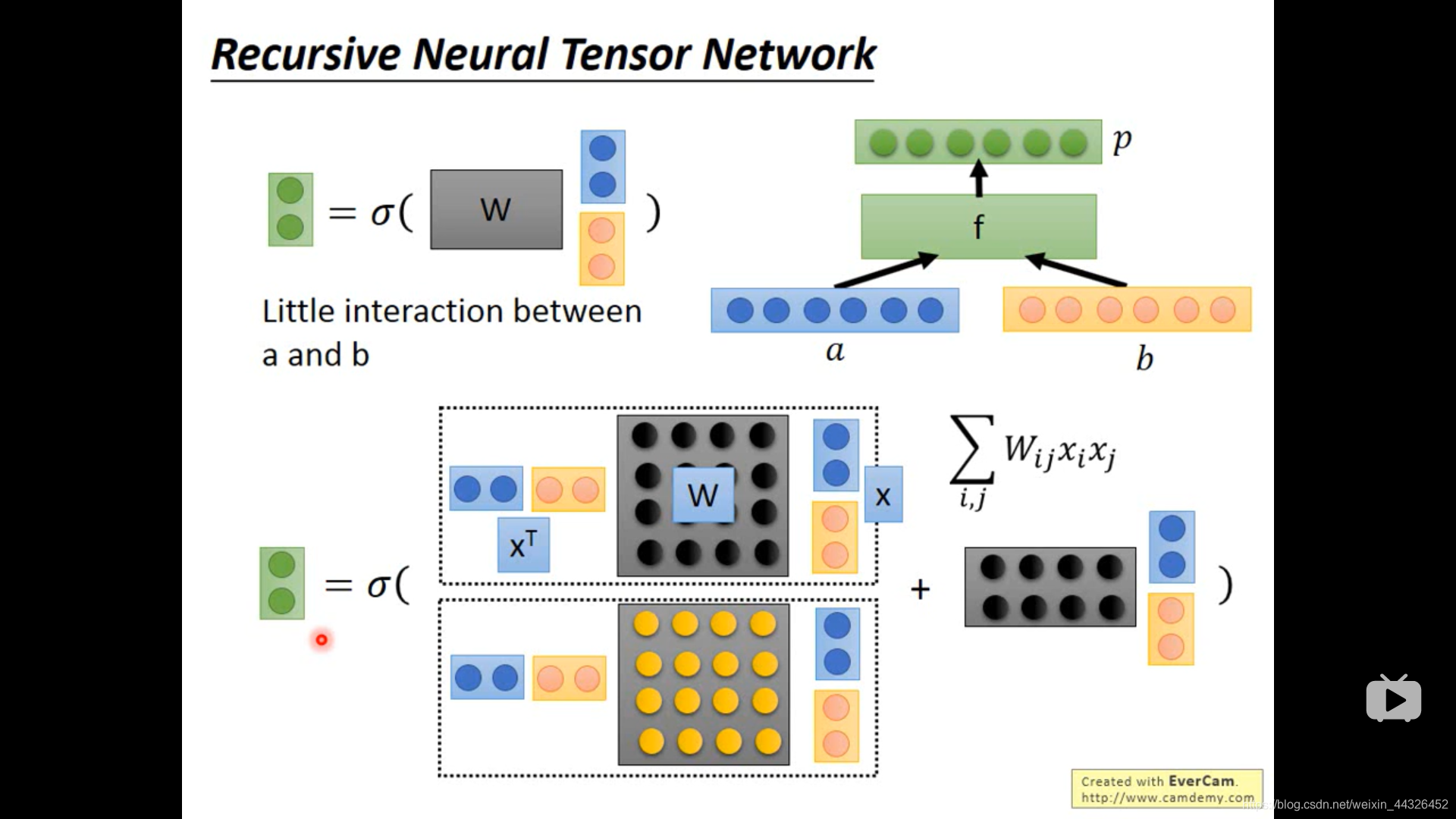
f 的其中一种设计方法
-
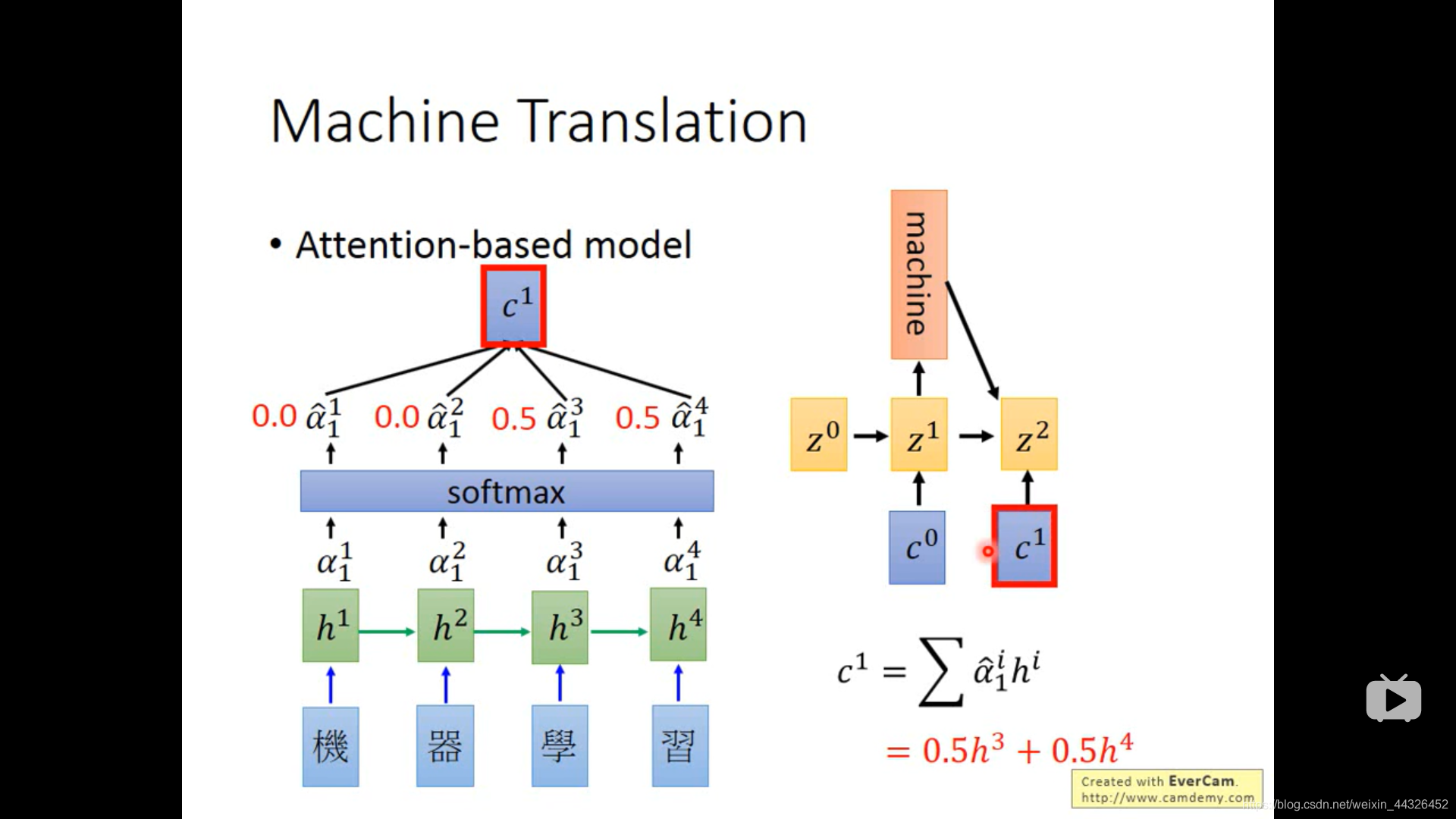
- 注意力模型:
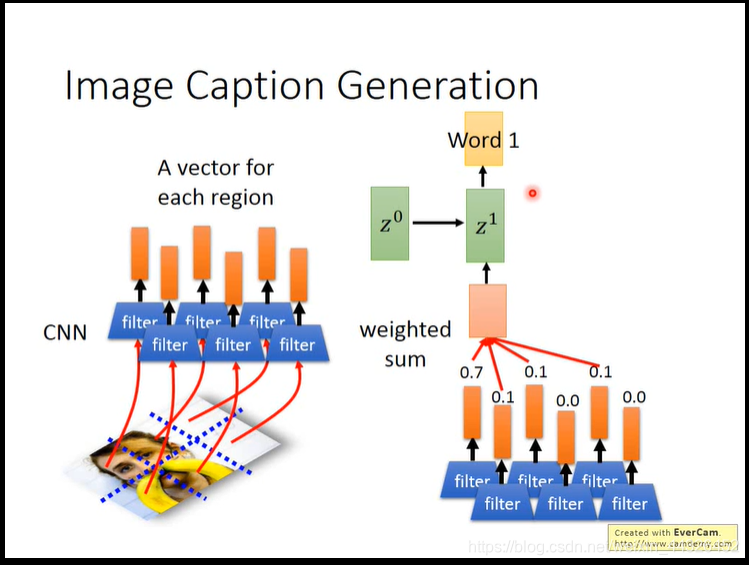
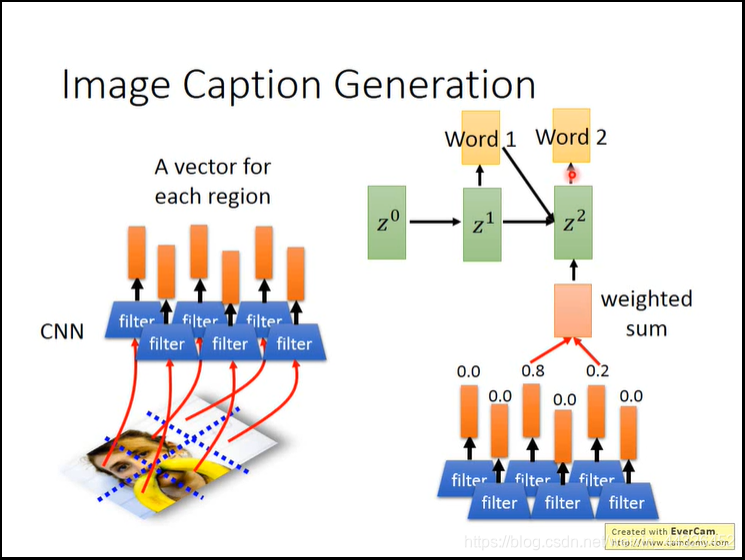
其中,z0可以作为参数来学习出来,其实就是,有一个神经网络(可能只有一层,或者是个复杂的函数,之类的),输入h1可以得到h1的attention,输入h2可以得到h2的attention,由attention加权h1到h4来算得c0,这个神经网络的参数是z,一开始是z0,z1由RNN网络从z0和c0得到。再用z1去得到h1和h2等的attention,由attention加权h算得c1,由z1和c1得到z2;其中,得到z的RNN同时输出sequence,从而得到sequence2sequence的注意力模型
-
- 用query 的vector来match每个句子的vector x1到xn,
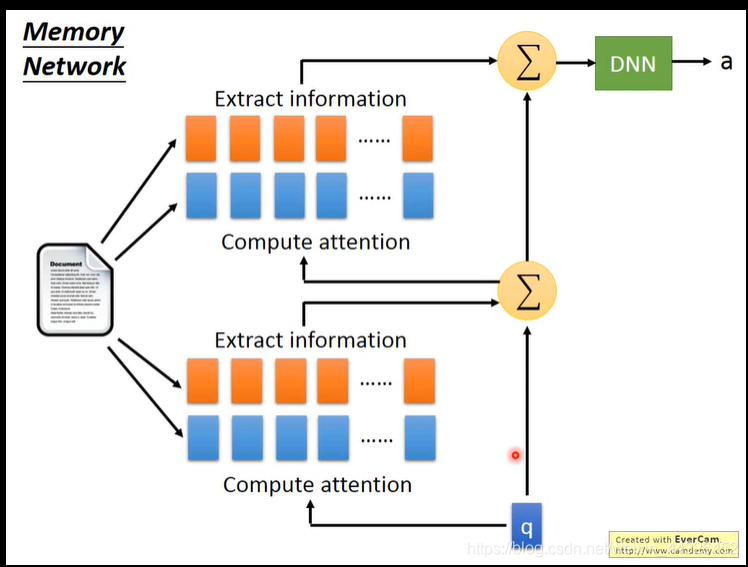
产生a1到an的相关度,然后利用相关度来压缩整个document,展开图如下所示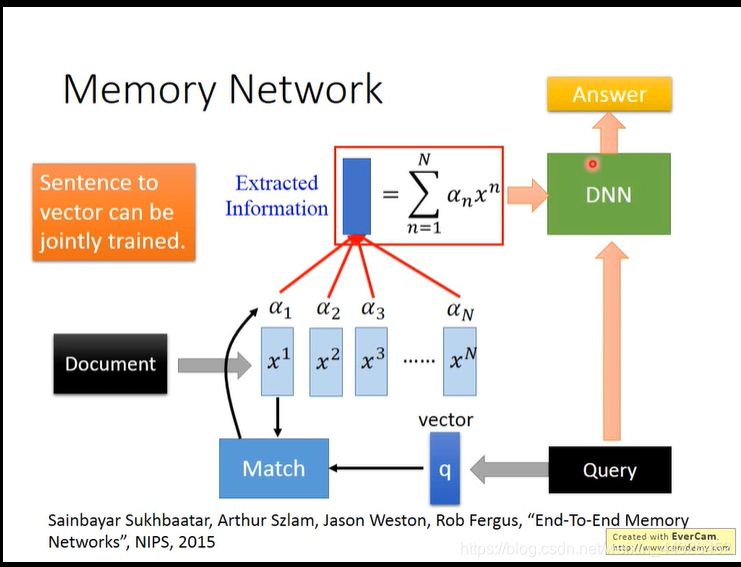
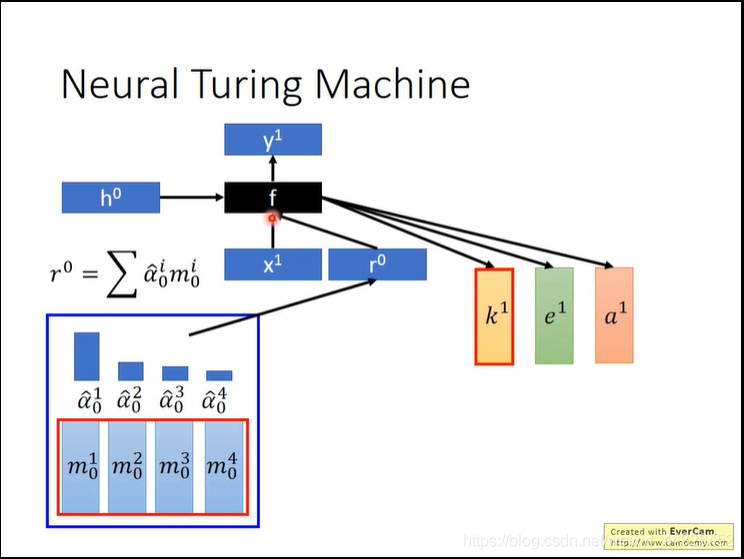
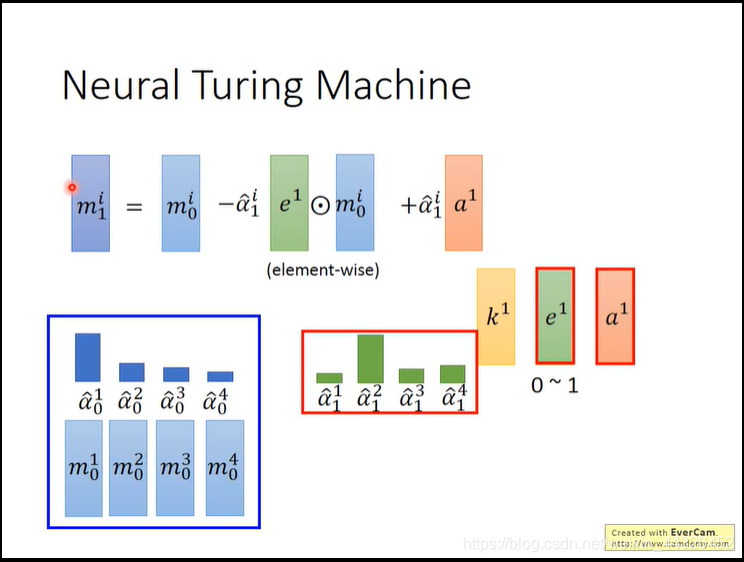
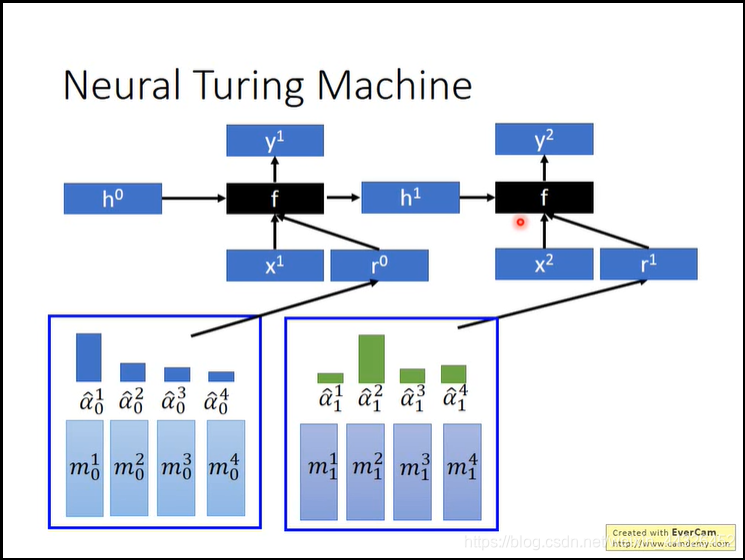
- Neural Turiing Machine
-
-


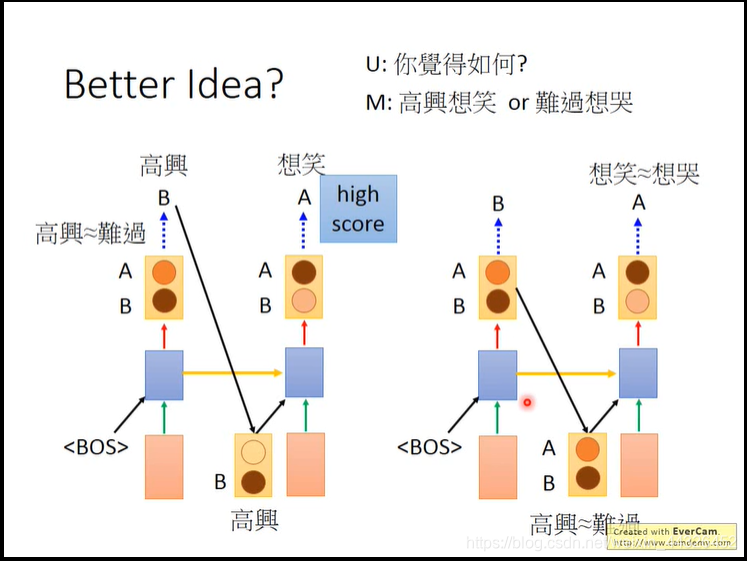
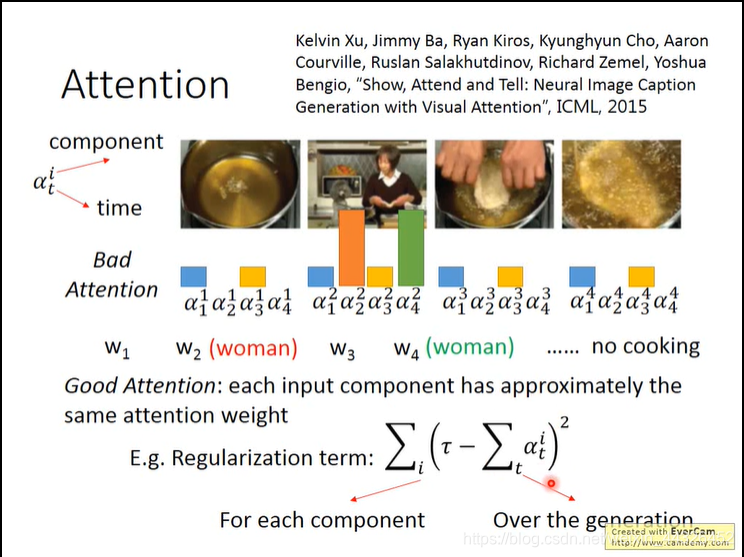
- 用正则化来防止注意力模型的重复注意:
- 若train 的时候,generate模型 input 的序列是 reference的序列而不是自己产生的序列,
而test的时候把自己generate的时间点output input到自己来产生一个序列,此时要input的是处理过后的output,即取distribution的max-one-hot的结果,会产生train和test mismatch 的结果,即test一步错步步错;
若train的时候像test的时候一样把自己的output作为input,会train不起来,因为reference的input和train的input有可能不一样,你不能期望不一样的input还继续产生reference的output。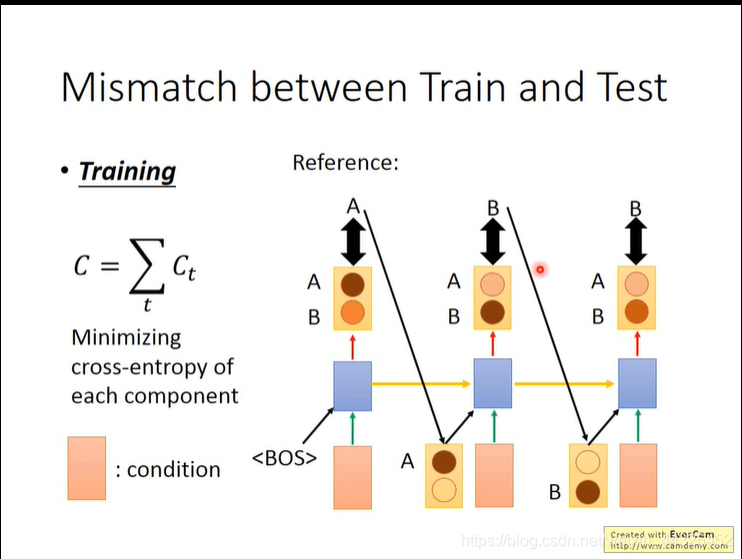
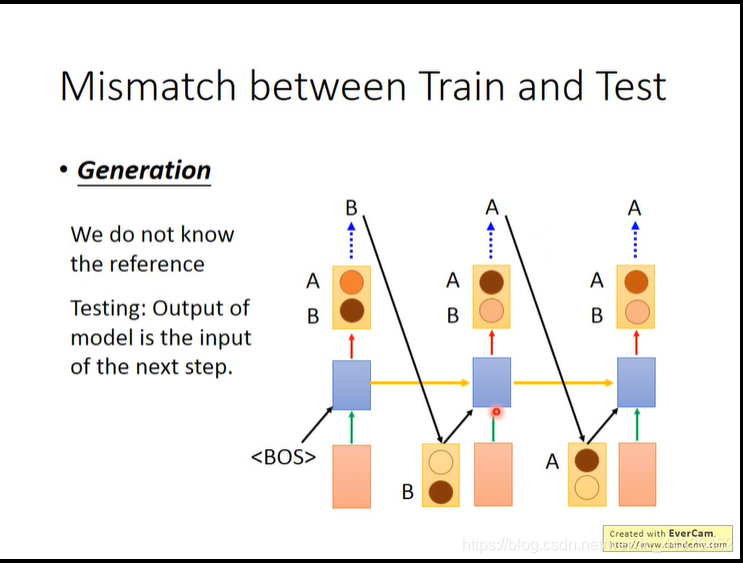
解决的办法是sampling ,取reference的几率随训练步数减小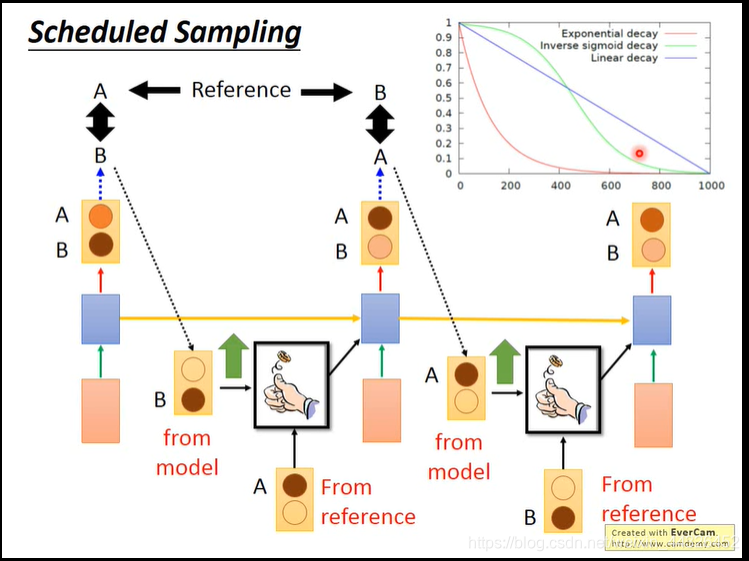
此外还要注意,取的是one-hot而不是distribute,原因如下图: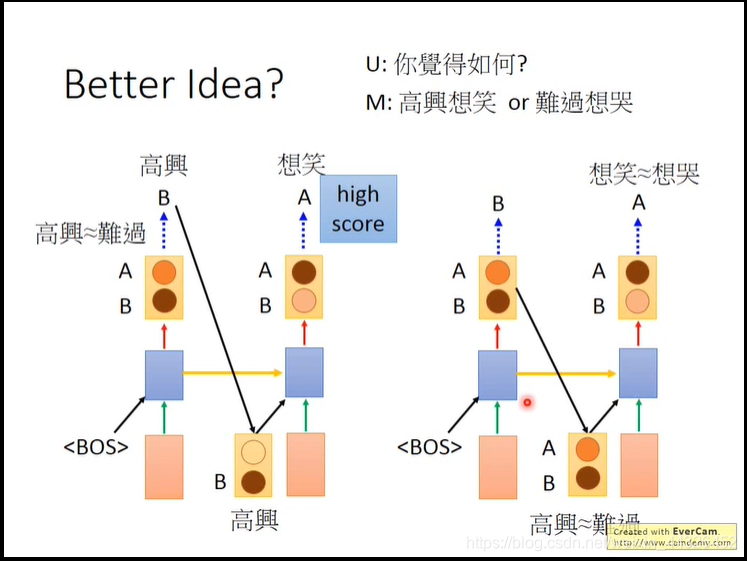
- 采用beam search来寻找最佳路径
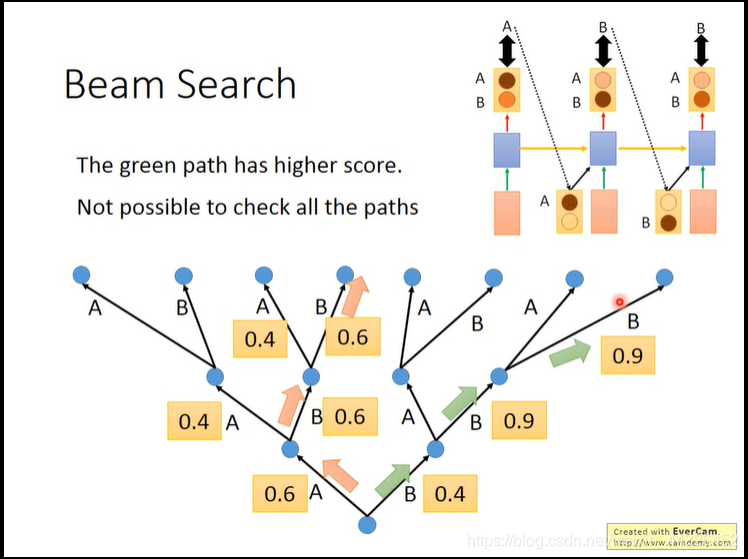
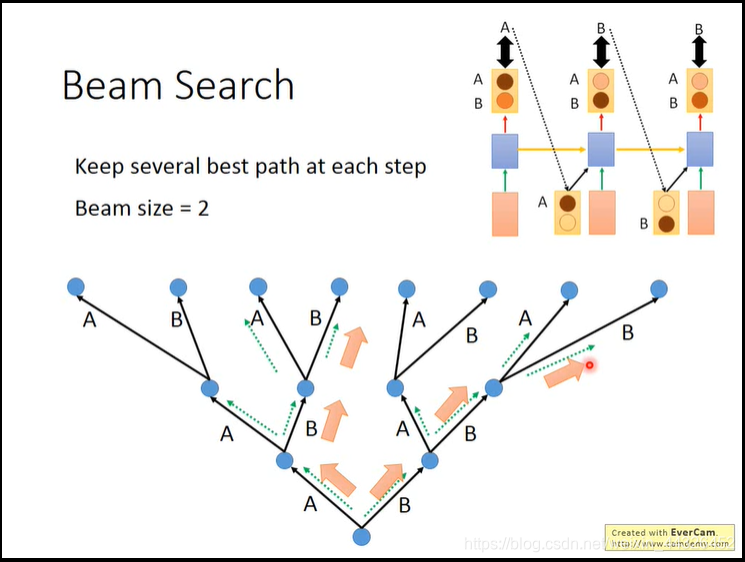
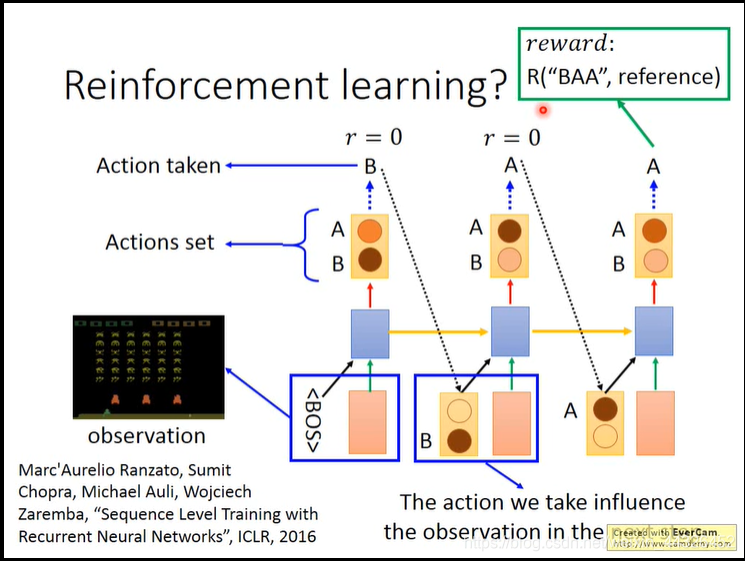
- 此外,training的过程中,越往后,由于是各个单词做交叉熵计算损失,所以可能出现句子个别单词错误时loss不大,导致后面很难train下去,视频介绍了用强化学习的方法来train,以下是大致过程,具体R是什么函数看reference原论文
- pointer network是在attention的模型上发展的,区别在于,输入decoder的不再是attention加权h,而是argmax的h
模型是为了找出一组点集的一个子集,使这个子集连线把整个点集包含在里面: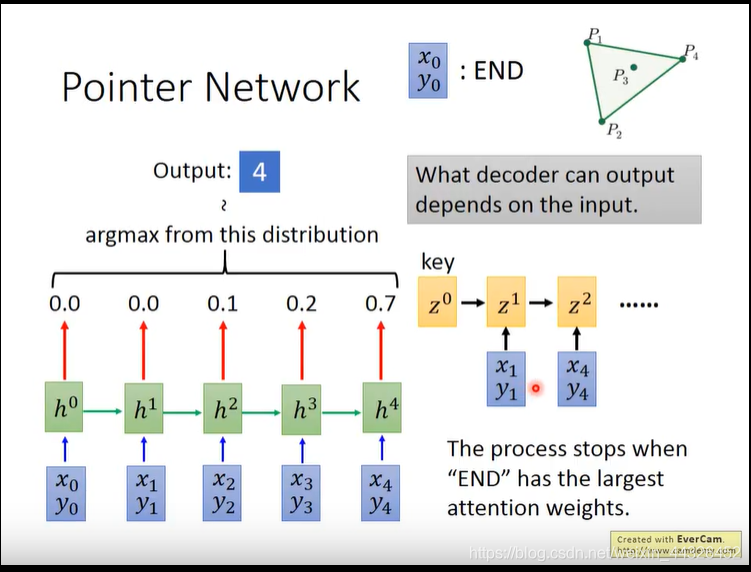
该模型可以用来做summarization的工作(即从一篇document中提取关键word或者总结句)
区别在于,summarization有几率采用pointer network的路径,也有几率采用普通attention的路径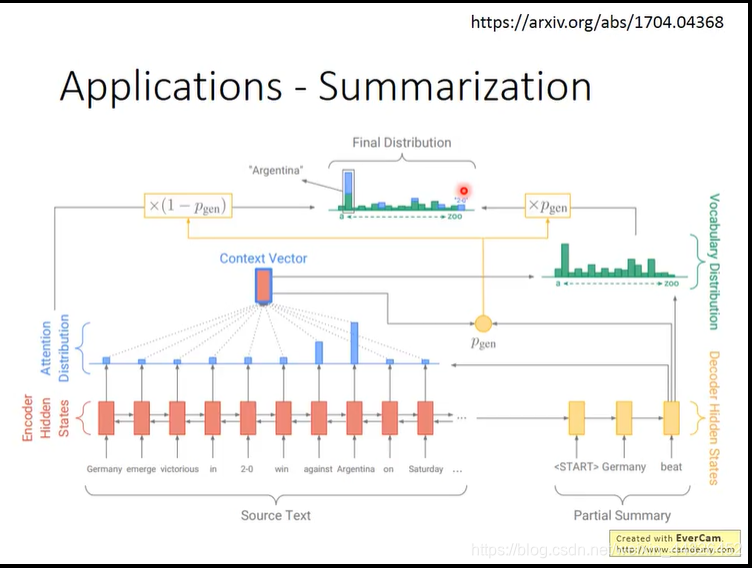
除此之外,翻译中对于人名地名的copy翻译和chatbot也可以用该模型实现: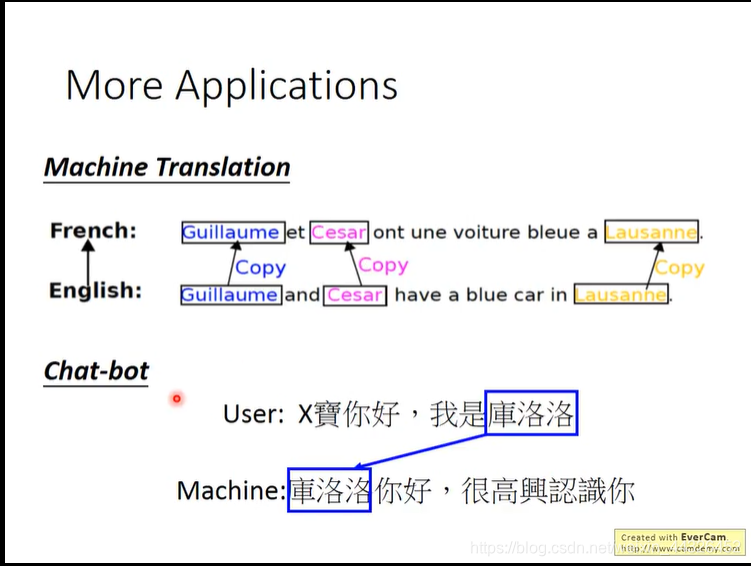
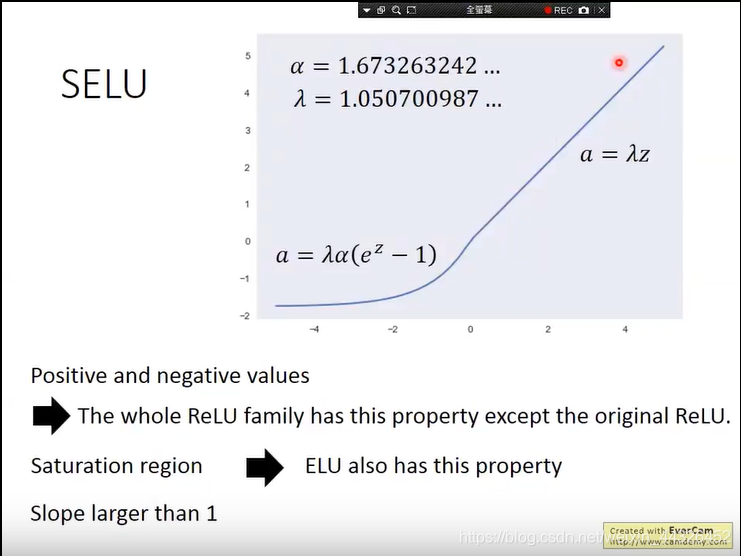
- SELU加上batch-normalization加上权重初始化为0mean1variance,可以得到很好的效果

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









