







滴滴会提供技术文档
https://dinone.kf5.com/hc/kb/article/1344589/
我下载的代码是1.0分支的
https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
参考文献
https://www.mscto.com/python/507195.html
https://www.cnblogs.com/wind-chaser/p/11359521.html
https://blog.youkuaiyun.com/woshicao11/article/details/82055449
1.搭环境
参考这篇博客,按照和他一样的环境来训练faster r-cnn
https://www.cnblogs.com/wind-chaser/p/11359521.html
python3.6+cuda10.1+Ubuntu16.04+Pytorch1.2
编译步骤主要参考下面的博客
https://www.mscto.com/python/507195.html
conda create -n faster python=3.6
source activate faster
下面安装pytorch=1.2,显示的是会安装对应的cudatoolkit=10.0.130,以及cudnn=7.6.5,前两次下载cudatoolkit包特别慢,多试几次就好了
conda install pytorch=1.2
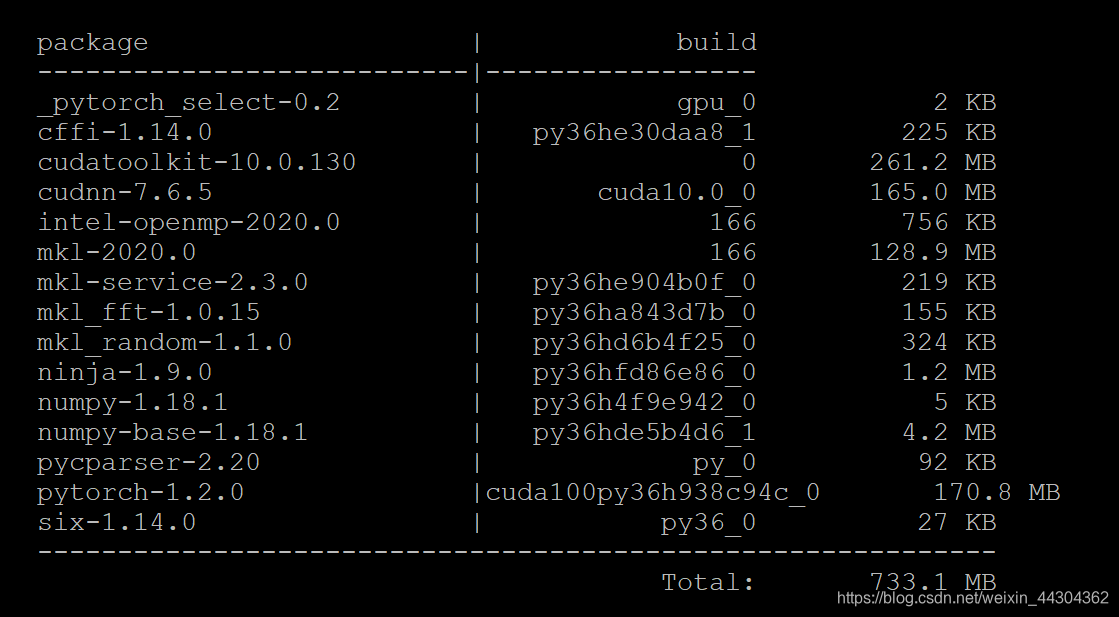
conda install torchvision
安装requirements包
pip install -r requirements.txt
1.1 编译cuda依赖项
切换到代码根目录下的lib文件夹(faster-rcnn.pytorch-pytorch-1.0\lib)下,编译Cuda依赖项。
cd lib
python setup.py build develop
顺利的话一步到位编译完成,报错需要看具体的报错信息。成功编译显示如下
Installed /home/dc2-user/faster/lib
Processing dependencies for faster-rcnn==0.1
Finished processing dependencies for faster-rcnn==0.1
https://blog.youkuaiyun.com/qq_20226441/article/details/104545689
1.2 创建data文件夹+准备自己的数据集
在代码根目录下创建data文件夹
https://www.mscto.com/python/507195.html
1.3 预训练模型
https://blog.youkuaiyun.com/woshicao11/article/details/82055449
这篇文章给了预训练模型
https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-base-models/vgg16_caffe.pth
这里下载vgg16的预训练模型
把下载好的vgg_caffe.pth放到data/pretrained_model文件夹下面
2. 修改源代码
2.1 第一处voc改为自己的类别
lib/datasets/pascal_voc.py中,self._classes修改为自己的类别。
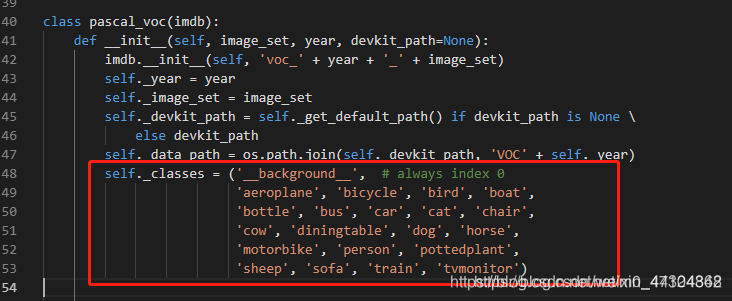
self._classes = ('__background__', # always index 0
'mask', 'face')
3.训练
python trainval_net.py --dataset pascal_voc --net vgg16 --bs 4 --nw 6 --epochs 20 --lr_decay_step 10 --cuda
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 3 --checkpoint 10021 --cuda
- enpochs 我设置的是跑100个,后面也可能停止
- “–dataset”指代你跑得数据集名称,我们就以pascal-voc为例。
- “–net”指代你的backbone网络是啥,我们以vgg16为例。 "–bs"指的batch size。
- “–nw”指的是worker number,取决于你的Gpu能力,我用的是P100 16GB,所以选择6。稍微差一些的gpu可以选小一点的值。后期也会调成
- “–cuda”指的是使用gpu。

训好的model会存到models文件夹底下,此处暂时使用默认的训练参数。
下面是对训练代码权重的解释和defalut的修改
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--dataset', dest='dataset',
help='training dataset',
default='pascal_voc', type=str)
parser.add_argument('--net', dest='net',
help='vgg16, res101',
default='vgg16', type=str) # 我使用的是vgg16,所以默认为vgg16
parser.add_argument('--start_epoch', dest='start_epoch',
help='starting epoch',
default=1, type=int) # 训练的时候epoch从哪开始
parser.add_argument('--epochs', dest='max_epochs',
help='number of epochs to train',
default=100, type=int) # 迭代多少次,这里我选择迭代100次
parser.add_argument('--disp_interval', dest='disp_interval',
help='number of iterations to display',
default=10, type=int) # 在一个迭代中间隔多少个batch显示,我这里改为10
parser.add_argument('--checkpoint_interval', dest='checkpoint_interval',
help='number of iterations to display',
default=20, type=int) # 每多少个迭代显示 我这里改为每20iteration显示一次
parser.add_argument('--save_dir', dest='save_dir',
help='directory to save models', default="models",
type=str) # 默认将训练出来的模型保存到models下面
parser.add_argument('--nw', dest='num_workers',
help='number of worker to load data',
default=0, type=int) # 加载数据要多少个worker,这里默认不改
parser.add_argument('--cuda', dest='cuda',
help='whether use CUDA',
default=True,
action='store_true') # 是否使用cuda GPU,当然
parser.add_argument('--ls', dest='large_scale',
help='whether use large imag scale',
action='store_true') # 是否使用大的图片跨度,就是学习率
parser.add_argument('--mGPUs', dest='mGPUs',
help='whether use multiple GPUs',
action='store_true') # 是否使用多GPU
parser.add_argument('--bs', dest='batch_size',
help='batch_size',
default=16, type=int) # 批处理大小,默认是1,到gpu上默认为16,一会可能需要改大小
parser.add_argument('--cag', dest='class_agnostic',
help='whether perform class_agnostic bbox regression',
action='store_true') # 是否执行类无关的bbox回归
# config optimization
parser.add_argument('--o', dest='optimizer',
help='training optimizer',
default="sgd", type=str) # 优化算法
parser.add_argument('--lr', dest='lr',
help='starting learning rate',
default=0.001, type=float) # 初始学习率
parser.add_argument('--lr_decay_step', dest='lr_decay_step',
help='step to do learning rate decay, unit is epoch',
default=5, type=int) # 没有理解错的话,学习率是要从0.001开始,每5经过5个epoch下降0.1
parser.add_argument('--lr_decay_gamma', dest='lr_decay_gamma',
help='learning rate decay ratio',
default=0.1, type=float) # 学习率下降率
# set training session 设置训练会话
parser.add_argument('--s', dest='session',
help='training session',
default=1, type=int) # 这个是针对多GPU的默认只有一个不考虑
# resume trained model 使用已经训练好的模型
parser.add_argument('--r', dest='resume',
help='resume checkpoint or not', # 恢复checckpoint
default=False, type=bool)
parser.add_argument('--checksession', dest='checksession',
help='checksession to load model',
default=1, type=int)
parser.add_argument('--checkepoch', dest='checkepoch',
help='checkepoch to load model',
default=1, type=int)
parser.add_argument('--checkpoint', dest='checkpoint',
help='checkpoint to load model',
default=0, type=int)
# log and diaplay
parser.add_argument('--use_tfb', dest='use_tfboard',
help='whether use tensorboard',
action='store_true',
default=False, type=bool)
args = parser.parse_args()
return args
3.1 错误1 ImportError: cannot import name ‘_mask’
https://blog.youkuaiyun.com/weixin_42279610/article/details/103086379
File "/home/dc2-user/faster/lib/datasets/factory.py", line 15, in <module>
from datasets.coco import coco
File "/home/dc2-user/faster/lib/datasets/coco.py", line 23, in <module>
from pycocotools.coco import COCO
File "/home/dc2-user/faster/lib/pycocotools/coco.py", line 60, in <module>
from . import mask
File "/home/dc2-user/faster/lib/pycocotools/mask.py", line 3, in <module>
from . import _mask
ImportError: cannot import name '_mask'
参考https://github.com/cocodataset/cocoapi/issues/59#issuecomment-469859646,是这里的coco不work
-For Python, run "make" under coco/PythonAPI
首先下载最新的cocoapi并make
经过一番胡乱的摸索我找到了这个语句https://blog.youkuaiyun.com/qq_22182835,貌似是make成功了
make -f Makefile
之后又在网上找到了make的解释
When you run make under the PythonAPI folder, actually you run the command python setup.py build_ext --inplace, within which your default python(mostly python2) is called. So, just run the command in the PythonAPI folder for python3
python3 setup.py build_ext --inplace
删掉faster-rcnn.pytorch/lib里面的pycocotool文件夹。替换为刚下载并编译成功的cocoapi/PythonAPI/pycocotools内的内容
faster-rcnn.pytorch/lib$ rm -rf pycocotools/
faster-rcnn.pytorch/lib$ mv <PATH_TO_FRESH_GIT_CLONE>/cocoapi/PythonAPI/pycocotools
(rm -rf * 删除当前目录下的所有文件,这个命令很危险,应避免使用。
所删除的文件,一般都不能恢复!)这是人家给出的代码,我们手动操作就可以
重新运行,faster-rcnn就运行起来了
3.2 错误2解决ImportError: cannot import name ‘imread’ from ‘scipy.misc’
https://blog.youkuaiyun.com/celina0321/article/details/94617813
安装低版本的scipy
pip install scipy==1.2.0
3.3 错误3
https://github.com/jwyang/faster-rcnn.pytorch/issues/599
ValueError: operands could not be broadcast together with shapes (441,786,4) (1,1,3) (441,786,4) #599
im = im.astype(np.float32, copy=False)
if im.shape[2] == 4:
# in the event you have an image with alpha channels, drop it for now
im = im[:, :, 1:4]
im -= pixel_means
3.4开始训练
'DOUBLE_BIAS': True,
'FG_FRACTION': 0.25,
'FG_THRESH': 0.5,
'GAMMA': 0.1,
'HAS_RPN': True,
'IMS_PER_BATCH': 1,
'LEARNING_RATE': 0.01,
'MAX_SIZE': 1000,
'MOMENTUM': 0.9,
'PROPOSAL_METHOD': 'gt',
'RPN_BATCHSIZE': 256,
'RPN_BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0],
'RPN_CLOBBER_POSITIVES': False,
'RPN_FG_FRACTION': 0.5,
'RPN_MIN_SIZE': 8,
'RPN_NEGATIVE_OVERLAP': 0.3,
'RPN_NMS_THRESH': 0.7,
'RPN_POSITIVE_OVERLAP': 0.7,
'RPN_POSITIVE_WEIGHT': -1.0,
'RPN_POST_NMS_TOP_N': 2000,
'RPN_PRE_NMS_TOP_N': 12000,
'SCALES': [600],
'SNAPSHOT_ITERS': 5000,
'SNAPSHOT_KEPT': 3,
'SNAPSHOT_PREFIX': 'res101_faster_rcnn',
'STEPSIZE': [30000],
'SUMMARY_INTERVAL': 180,
'TRIM_HEIGHT': 600,
'TRIM_WIDTH': 600,
'TRUNCATED': False,
'USE_ALL_GT': True,
'USE_FLIPPED': True,
'USE_GT': False,
'WEIGHT_DECAY': 0.0005},
'USE_GPU_NMS': True}
Loaded dataset `voc_2007_trainval` for training
Set proposal method: gt
Appending horizontally-flipped training examples...
voc_2007_trainval gt roidb loaded from /home/dc2-user/faster/data/cache/voc_2007_trainval_gt_roidb.pkl
done
Preparing training data...
done
before filtering, there are 51258 images...
after filtering, there are 51258 images...
51258 roidb entries
Loading pretrained weights from data/pretrained_model/vgg16_caffe.pth
[session 1][epoch 1][iter 0/3203] loss: 3.0121, lr: 1.00e-03
fg/bg=(143/3953), time cost: 4.482066
rpn_cls: 0.7265, rpn_box: 1.0936, rcnn_cls: 1.1774, rcnn_box 0.0146
[session 1][epoch 1][iter 10/3203] loss: 1.2623, lr: 1.00e-03
fg/bg=(261/3835), time cost: 14.478861
rpn_cls: 0.4469, rpn_box: 0.2452, rcnn_cls: 0.5012, rcnn_box 0.1579
bs=8
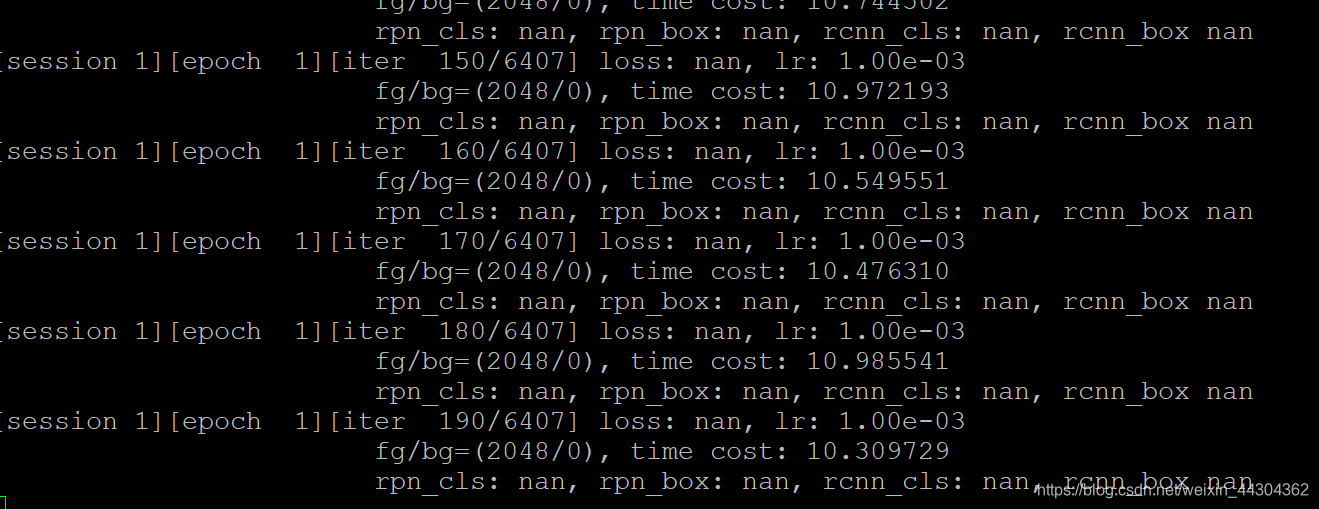
[session 1][epoch 1][iter 120/3203] loss: nan, lr: 1.00e-03
fg/bg=(4096/0), time cost: 19.060250
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 130/3203] loss: nan, lr: 1.00e-03
fg/bg=(3840/256), time cost: 18.118199
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
bs=4,
[session 1][epoch 1][iter 40/12814] loss: 0.6756, lr: 1.00e-03
fg/bg=(32/992), time cost: 4.678066
rpn_cls: 0.0886, rpn_box: 0.2489, rcnn_cls: 0.0742, rcnn_box 0.0472
[session 1][epoch 1][iter 50/12814] loss: nan, lr: 1.00e-03
fg/bg=(1024/0), time cost: 5.245597
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 60/12814] loss: nan, lr: 1.00e-03
fg/bg=(1024/0), time cost: 5.357770
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 70/12814] loss: nan, lr: 1.00e-03
fg/bg=(1024/0), time cost: 5.623735
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 80/12814] loss: nan, lr: 1.00e-03
fg/bg=(1024/0), time cost: 5.544974
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 90/12814] loss: nan, lr: 1.00e-03
fg/bg=(1024/0), time cost: 5.454026
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
(base) dc2-user@10-255-0-254:~$ screen
'BG_THRESH_LO': 0.0,
'BIAS_DECAY': False,
'BN_TRAIN': False,
'DISPLAY': 10,
'DOUBLE_BIAS': True,
'FG_FRACTION': 0.25,
'FG_THRESH': 0.5,
'GAMMA': 0.1,
'HAS_RPN': True,
'IMS_PER_BATCH': 1,
'LEARNING_RATE': 0.0001,
'MAX_SIZE': 1000,
'MOMENTUM': 0.9,
'PROPOSAL_METHOD': 'gt',
'RPN_BATCHSIZE': 4,
'RPN_BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0],
'RPN_CLOBBER_POSITIVES': False,
'RPN_FG_FRACTION': 0.5,
'RPN_MIN_SIZE': 8,
'RPN_NEGATIVE_OVERLAP': 0.3,
'RPN_NMS_THRESH': 0.7,
'RPN_POSITIVE_OVERLAP': 0.7,
'RPN_POSITIVE_WEIGHT': -1.0,
'RPN_POST_NMS_TOP_N': 2000,
'RPN_PRE_NMS_TOP_N': 12000,
'SCALES': [600],
'SNAPSHOT_ITERS': 5000,
'SNAPSHOT_KEPT': 3,
'SNAPSHOT_PREFIX': 'res101_faster_rcnn',
'STEPSIZE': [30000],
'SUMMARY_INTERVAL': 180,
'TRIM_HEIGHT': 600,
'TRIM_WIDTH': 600,
'TRUNCATED': False,
'USE_ALL_GT': True,
'USE_FLIPPED': True,
'USE_GT': False,
'WEIGHT_DECAY': 0.0005},
'USE_GPU_NMS': True}
Loaded dataset `voc_2007_trainval` for training
Set proposal method: gt
Appending horizontally-flipped training examples...
3.5错误4 loss=nan
主要参考https://blog.youkuaiyun.com/ksws0292756/article/details/80702704
https://blog.youkuaiyun.com/qq_14839543/article/details/72900863
https://blog.youkuaiyun.com/zhangyingna667/article/details/101480831
从面的训练过程可以看到,当我把bs从16改为8之后再改为4,出现了loss=nan说明模型发散,此时应该停止训练,不然得到的模型也不能检测出物体。(我花了2天的时间训练了20个epoch啊,浪费金钱,果然还是训练完一个epoch出来马上就测试demo的)
这种方法无效
打开./lib/setup.py文件,找到第130行,将gpu的arch设置成与自己电脑相匹配的算力,这里举个例子,如果你用的是GTX1080,那么你的算力就是6.1,此时就需要将-arch=sm_52改成-arch=sm_61。
可以看到我的型号是Tesla P100 PCIe 16GB
https://blog.youkuaiyun.com/weixin_30827565
(faster) dc2-user@10-255-0-254:~/faster$ lspci
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.1 IDE interface: Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II]
00:01.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 03)
00:02.0 VGA compatible controller: Cirrus Logic GD 5446
00:03.0 Ethernet controller: Red Hat, Inc. Virtio network device
00:04.0 SCSI storage controller: Red Hat, Inc. Virtio SCSI
00:05.0 SCSI storage controller: Red Hat, Inc. Virtio block device
00:06.0 3D controller: NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] (rev a1)
00:07.0 Unclassified device [00ff]: Red Hat, Inc. Virtio memory balloon
https://developer.nvidia.com/cuda-gpus 在这个网站查看对应的算力,我用的这个服务器是的计算能力是6.0

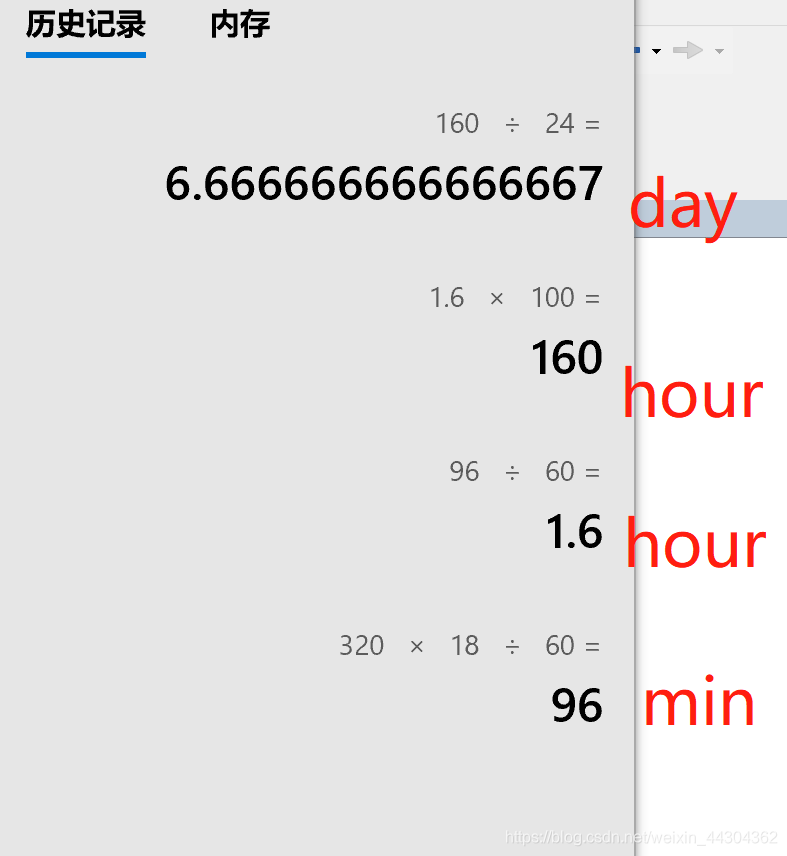
3.5.1 计算时间(bs=16)1.6h epoch
计算一下时间,3203/10=320个.100个enpoch要6.6天,1.6hour训练一个epoch,那么20个要32hour一天多。
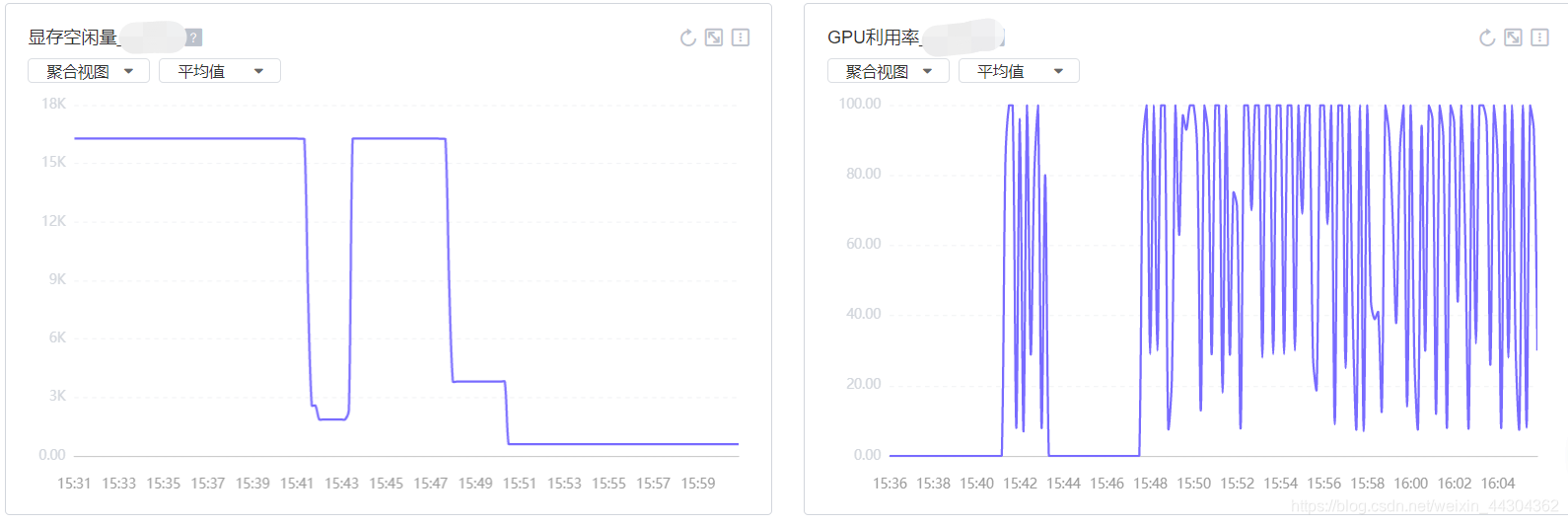
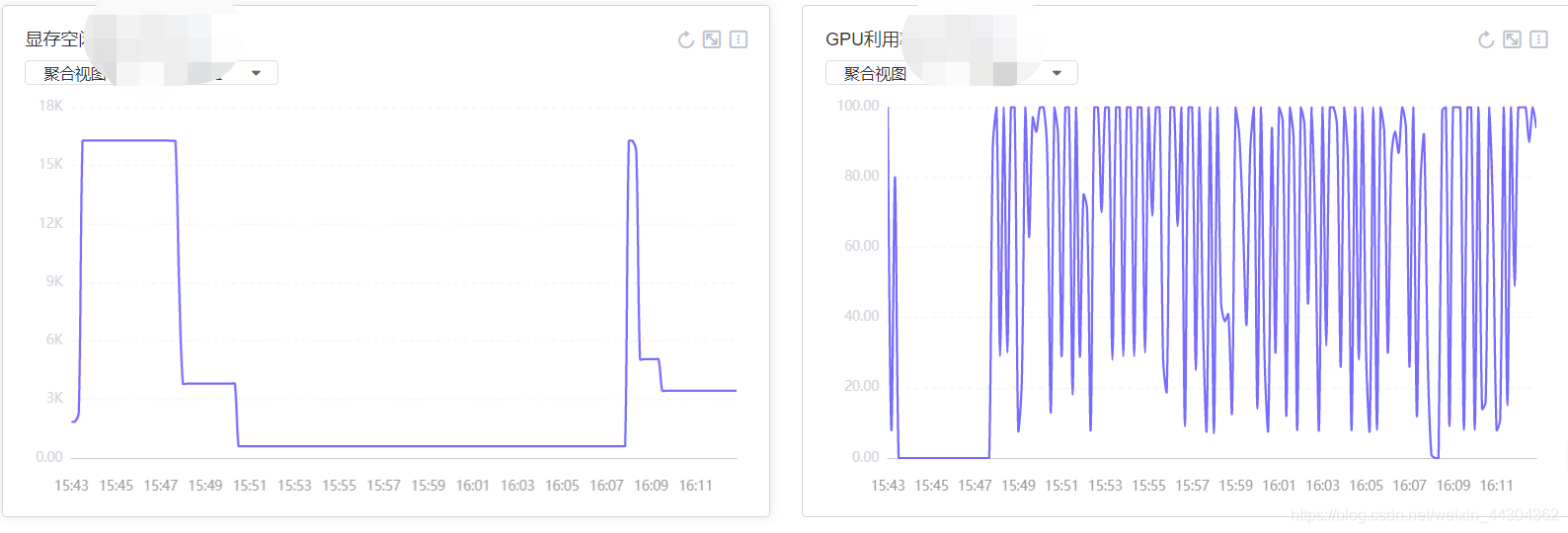
3.5.2 计算时间(bs=8)1.9小时/epoch
 10个iter的时间缩小了不到一半(bs由16-8之后)
10个iter的时间缩小了不到一半(bs由16-8之后)
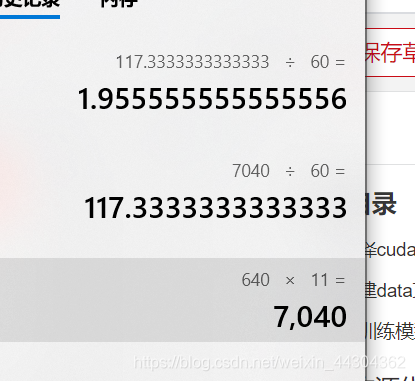
4.test_net.py
训练好的模型目录models/vgg16/pascal_voc/faster_rcnn_1_8_6406.pth
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 8 --checkpoint 6406 --cuda
注意,这里的三个check参数,是定义了训好的检测模型名称,我训好的名称为faster_rcnn_1_8_6406.pth,,代表了checksession = 1,checkepoch = 8, checkpoint = 6406,这样才可以读到模型“faster_rcnn_1_8_6406”。训练中,我设置的epoch为20,但训练到第8批就停了,所以checkepoch选择8,也就是选择最后那轮训好的模型,理论上应该是效果最好的。当然着也得看loss。
4 demo.py
https://github.com/ShourenWang/Faster-RCNN-pytorch
参考文献里的博主改了新的demo.py可以用来测试mAP,同样记得修改类为自己的数据集需要的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









