




 本文全面综述了基于联邦学习的隐私保护推荐算法,探讨了其在保护用户隐私的同时,如何通过联合多个参与方学习无损的全局模型。文章详细介绍了基础联邦推荐算法、效率增强、个性化、性能增强和隐私增强等方面的进展,并对未来的研究方向进行了展望,包括推荐系统的激励机制、冷启动、异质性和实时性挑战。
本文全面综述了基于联邦学习的隐私保护推荐算法,探讨了其在保护用户隐私的同时,如何通过联合多个参与方学习无损的全局模型。文章详细介绍了基础联邦推荐算法、效率增强、个性化、性能增强和隐私增强等方面的进展,并对未来的研究方向进行了展望,包括推荐系统的激励机制、冷启动、异质性和实时性挑战。
嘿,记得给“机器学习与推荐算法”添加星标
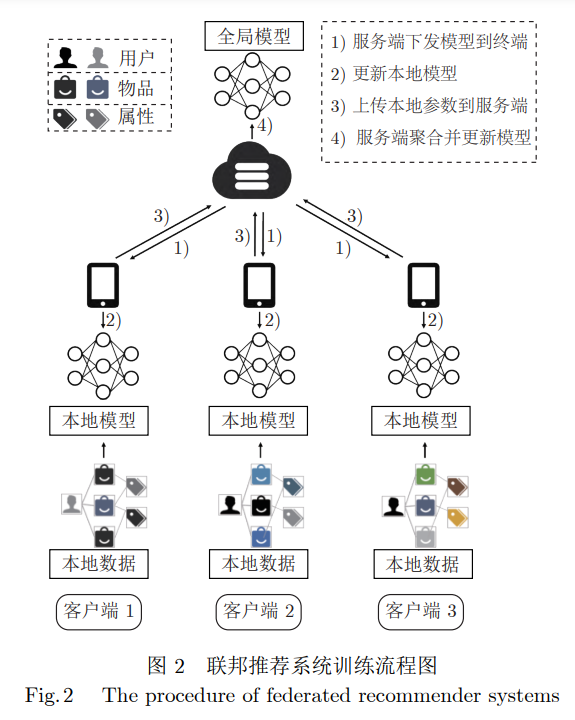
推荐系统通过集中式的存储与训练用户对物品的海量行为信息以及内容特征,旨在为用户提供个性化的信息服务与决策支持.然而,海量数据背后存在大量的用户个人信息以及敏感数据,因此如何在保证用户隐私与数据安全的前提下分析用户行为模式成为了近年来研究的热点.联邦学习作为新兴的隐私保护范式,能够协调多个参与方通过模型参数或者梯度等信息共同学习无损的全局共享模型,同时保证所有的原始数据保存在用户的终端设备,较之于传统的集中式存储与训练模式,实现了从根源上保护用户隐私的目的,因此得到了众多推荐系统领域研究学者们的广泛关注.
论文下载地址:
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c211189
基于此,本文对近年来基于联邦学习范式的隐私保护推荐算法进行全面综述、系统分类与深度分析.具体的,首先综述经典的推荐算法以及所面临的问题,然后介绍基于隐私保护的推荐系统与目前存在的挑战,随后从多个维度综述结合联邦学习技术的推荐算法, 即基础联邦推荐算法、基于效率增强的联邦推荐算法、缓解异质性的个性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









