







 探讨自然语言处理中词向量的多种表示方法,包括One-hot Representation、Distributed Representation,及其在文本相似度计算、词频统计、深度学习模型中的应用。
探讨自然语言处理中词向量的多种表示方法,包括One-hot Representation、Distributed Representation,及其在文本相似度计算、词频统计、深度学习模型中的应用。
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
One-hot Representation文本表示
1、Word Representation
举个例子:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。

2、Sentence Representation(boolean)

不管出现几次,都标记为1,1代表出现。
基于词袋模型建立向量:
def build_en_word_dict():
'''
根据所有出现的文本建立字典
'''
word_set_en = set()
with open('english_all.txt', 'r', encoding='utf8') as f:
data = f.readlines()
for s in data:
s = english_clean(s)
word_set_en = word_set_en.union(set(s))
# print(word_set_en)
#用字典保存两篇文章中出现的所有词并编上号
en_word_dict = dict()
i = 0
for word in word_set_en:
en_word_dict[word] = i
i += 1
return en_word_dict
def english_clean(s):
rule = re.compile(u"[^a-zA-Z, ]")
s = re.sub(r'_', ' ', s)
s = rule.sub('',s)
s = s.strip()
s_cut = nltk.word_tokenize(s)
return s_cut
def build_vector_en(s1, word_dict):
'''
input:英文字段s1,词典en_word_dict
output:基于词袋模型构建好的向量
'''
s1_cut = english_clean(s1)# 数据预处理
#根据词袋模型统计词在每篇文档中出现的次数,形成向量
s1_cut_code = [0]*len(word_dict)
for word in s1_cut:
s1_cut_code[word_dict[word]]+=1
return s1_cut_code3、Sentence Representation(count)

4、Sentence Similarity(文本相似度)
1)欧式距离:d = |s1 - s2|
s1:10110000
s2:00000111
s3:02210101
d(s1,s2) = √6
d(s1,s3) = √8
d(s2,s3) = √10
2)余弦相似度(cosine similarity):d = (s1·s2) / (|s1|*|s2|),内积/模的乘积

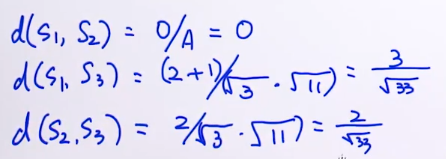
Python计算余弦相似度及向量范数 https://blog.youkuaiyun.com/weixin_44285715/article/details/108463889
3)缺点:

还有:
- 不能表示语义相似度:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
- sparsity(稀疏性)
5、Tf-idf Representation
# Equivalent to CountVectorizer followed by TfidfVectorizer
# tf: term frequency 词频
# idf: inverse documents frequency逆文本频率指数tfidf(w) = tf(d,w) * idf(w)
tf(d,w):文档d中w的词频
idf(w):log(N/(N(w))),
其中,N:语料库中的文档总数,N(w):词语w出现在多少个文档中?

Distributed Representation
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation。Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。

向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角(余弦相似度)来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
- 后文提到的所有“词向量”都是指用 Distributed Representation 表示的词向量。
- 如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。
- 同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
- 相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
question:
100维的one-hot表示法最多可以表达多少个不同的单词?
100个单词。
100维的Distributed representation表示法最多可以表达多少个不同的单词?
2^100个单词。(理论上+∞ 个)
learn word embeddings 学习词向量
sentence embedding:Averaging法则:
将所有词向量求和取平均值,即得到包含这些词的句子向量。
层次过滤:
问题——>过滤——>相似度匹配——>返回相似度最高的
Inverted Index 倒排表
- 创建词典
- 统计词典里某个单词出现在了哪些文章里。
- 如果用户输入一个词,则包含这些词的文章被列为候选对象,对这些候选文章进行排序,然后返回给用户。
- 如果用户输入两个词,则返回包含这两个词的交集文章,如果没有,就返回并集文章,对这些候选文章再进行排序,然后返回给用户。
深度学习模型:
Skip-Gram
Glone
CBOW
RNN/LSTM
MF
Gaussian Embedding

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









