







摘要
本文主要是对这一篇论文(TopoTag:A Robust and Scalable Topological Fiducial Marker System)的学习整理。包含的内容分为两个部分,在前面对文章的主要内容进行了翻译,在后面部分是自己对TopoTag的理解。
摘要
本文主要是对这一篇论文(TopoTag:A Robust and Scalable Topological Fiducial Marker System)的学习整理。包含的内容分为两个部分,在前面对文章的主要内容进行了翻译,在后面部分是自己对TopoTag的理解。
原文部分翻译
TopoTag,是一个健壮的,可拓展的拓扑基准标签系统,标签系统使用拓扑和集合信息来实现比较高的鲁棒性,其中,拓扑信息用来检测二维的标记,集合信息用于身份的解码。和以往的标签系统不同,TopoTag可以在不牺牲位来获得更高的召回率和精确度的情况下,使用完整位进行ID编解码。TopoTag支持数以万计的唯一ID,可以轻松扩展到数百万唯一标签,从而实现巨大的可拓展性。论文作者还收集了一个很大的测试数据集,一共有169713张图像用于评估,涉及面内和面外选装,图像模糊,不同距离和不同背景,TopoTag在检测精度,顶点抖动,姿态抖动和精确度等指标上显著优于之前的基准标记系统,此外,TopoTag支持遮挡,只要主要的标签拓扑结构是保持和允许灵活的形状涉及,用户就可以自定义内部和外部的标记形状。论文作者github
1.介绍
TopoTag主要通过在标签设计中增加拓扑信息来提高鲁棒性。结果显示TopoTag在定点抖动,姿态误差和姿态抖动方面表现最佳。同时在拓扑主结构不变的情况下,还支持灵活的外形设计。
下面的图片给出了现有的一些视觉基准标签。

图片中的视觉标签主要可以分为以下几类
圆形模式
在最早的相关工作中,Gatrell等人提出使用同心对比圆 (CCC)作为视觉基准标签设计的一种方式。随后这一种设计方式被其他人改进,对同心对比圆增加了颜色和多种尺度的信息。在这之后,为了能够增加标签的辨识度,在圆的周围开始加上了特定的环形数据带。再之后, Sattar等人22] and Xu 等人提出了使用频率图像作为特征的FourierTag。在RuneTag,和PiTag中,他们提出了使用点环来提高对遮挡的鲁棒性,并且为姿态的估计提供更多的点。CCTag,Prasad等人的工作使用了多个环来增加模糊鲁棒性和编码环的宽度。 圆形模式像RuneTag等,为大多数身份身份认定提供了最先进的技术,但是由于需要找到足够数量的可信椭圆,跟踪的距离是很有限的。相比之下,TopoTag可以提供更多的身份并且能够提供更大的跟踪范围。
方形模式
为了能够更好的定位,很多的基准系统在设计的时候都会采用一个厚的方形边界。Matix,CyberCode,和VisualCode是最早提出来的也是最简单的设计建议方式。ARTag和ARToolkitplus改进了二进制编码模式的识别技术,此外他们还加入了纠错机制来提高标签系统的鲁棒性。BinARyID提出了一种试图避免旋转模糊的标记生成方法。Schweiger等人提出了一中专门为SIFT和SUFT探测器设计的SIFT和SUFT滤波器。Tateno等人建议使用嵌套标记来提高不同距离下的性能。也有一些研究通过在棋盘中使用多个基准标记来改进相机的校准,并且通过进一步添加颜色来减少透视的模糊度。Apriltag是在ARTag之上的一种改进,在速度上更快并且具有更好的鲁棒性表现。 Garrido-Jurado提出了ArUco,这类标签使用混合整数规划来生成标记。ChromaTag使用比在Apriltag上叠加颜色来提高标签的检测速度。正方形模式由于在检测鲁棒性强,跟踪范围大等优点,在实际应用中最受欢迎。然而必须要保留一些编码为来处理旋转模糊并结合汉明距离的策略。与之相对比,TopoTag可以通过编码完整位提供更加丰富的身份,同时实现最先进的健壮性和跟踪范围。此外,常见的四边形标签使用四个角点来对姿态进行估计(可以做到避免位姿估计二义性的最少的数量),而在TopoTag中,使用了所有的标签编码位的顶点来进行位姿的估计。
值得注意的是,在文章10中,减少了旋转模糊的可能性,通过增加颜色信息增加了丰富的身份,并且通过使用更多的内部角点来实现更好的位姿精度。但是它也还是需要保留一些位用于错误检测和矫正,相比之下,由于独特的基线节点设计,TopoTag在不使用颜色的情况下提供了更加丰富的id,并且可以利用更多的特征对应点来获得更好的位姿估计效果。
拓扑模式
D-touch是最早在标签设计中使用拓扑结构的。它的标签的检测是基于区域邻接树的信息的。D-touch对集合中的所有标记使用单一的拓扑,并且不提供计算位置和方向的特定方法。ReacTIVision改进了D-touch,并且通过构建区域邻接图的左重深度序列提供了要给纯拓扑结构的唯一恒等式。BullsEye是由一个中心百点加上一个或者多个数据环组成,中心白点由黑环包围,一个或者多个数据环又由实心白环包围,实心白环内部有三个白色的螺柱。拓扑模式整明了利用拓扑信息提高鲁棒性的能力。然而由于缺乏足够的匹配特征点,他们只能恢复二维的位置和方向,相比之下,TopoTag还提供了精准的三维姿态估计和最先进的鲁棒性。
机器学习
克劳斯等人[41],[42]使用训练过的分类器,以提高在照明不足和快速相机造成的模糊情况下的检测运动。随机化森林也被用来学习和检测平面物体[43],[44]。机器学习方法显示了检测自然物体的潜力。然而,在实践中,这些算法并没有达到与专门为标记检测设计的检测算法相同的检测精度[1]。相比之下,TopoTag实现了最先进的检测精度超过机器学习和其他以前类型的模式。
2.标签设计
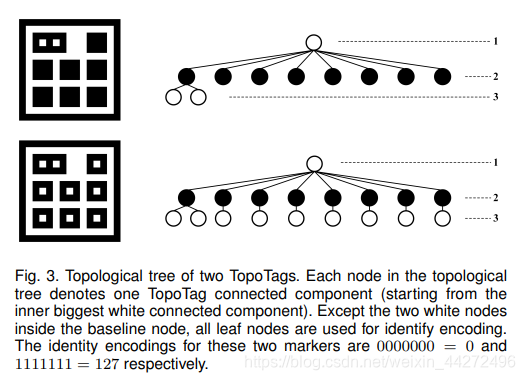
TopoTag在标签设计中使用了拓扑结构的信息。已经证实的是,通过采用这样的方法,能够在光照变化的情况下增加检测的鲁棒性并且能够减少误检的概率。现有的基准标签系统,特别是方形模式下的标签系统,在解码的过程中通过牺牲编码位的方式来处理旋转模糊。为了能够提高抑制误报的概率,还会保留额外的比特位用于配合汉明距离策略的应用。拓扑设计的强大鲁棒性有助于节省用于编码的位数。为了避免旋转模糊,TopoTag在拓扑结构中引入了基线节点,基线节点经过特殊的设计,和标记中的其他节点不一样。TopoTag使用内部有两个白色子节点的黑色节点作为基准节点,其他的黑色节点(最多一个白色子节点)作为普通的节点。注意,基线节点可以用其他的形式定义。比如,它可以根据不同的需要被定义为三个或者更多的白色子节点。基线节点定义了整个标签的搜索起始位置,这样就可以避免去检查旋转之间的混淆。所有的普通节点都可以用来作为身份的编码,例如0表示没有子节点,1表示有子节点。
在位姿测量中,其余的方形模式的标签往往只使用四个角点,TopoTag使用更多的点的信息,从而可以实现更加精准的位姿测量。基线节点(更准确的说是他们的两个子节点)和所有的普通节点都是特征点,这样就实现了更加准确的位姿测量。
值得注意的是,TopoTag的设计是基于拓扑信息的,它对标签的形状并没有特殊的限定。在拓扑结构保持不变的前提下,内部和外部的形状都可以由用户自定义进行设计。
3.TopoTag的检测

图四列出了TopoTag检测方法的主要步骤。拓扑信息被广泛的应用于二维标记检测,而相应的集合信息则被用于身份解码。三维姿态估计是通过所有的拓扑标记的顶点来实现的。
3.1 2D标签检测
阈值图像估计
和自适应阈值的想法类似,我们通过分析每一个像素的相邻像素的信息来确定该个像素的阈值。这个分析可以建立在原始图像上进行,然而为了处理在实际应用中的图像噪声和模糊,通过分析下采样图像(向量S1)能够更加准确,同时它也能够带来速度上的提升。为了去除掉图像中太黑的像素点,我们把图像中灰度小于α的像素值提高到α。在下采样图像中计算局部区域(窗口大小为w)的平均值。为了进一步处理图像噪声。下采样之后的平均图可以再次被下采样,最后的阈值图像时通过将两个下采样图像s1*s2并使用双线性插值法进行上采样得到的。图四b中所示。
二值化
通过比较输入图像和阈值图像之间像素值的大小进行二值化。设置最小亮度(β)以过滤过小的区域(如果像素值小于β,那么久设置为黑色),关于二值化结果的示例,参加上图c。
拓扑过滤
在完成二值化之后,我们通过来连接二值化区域来构建拓扑树。为了找到候选标签,我们设置两个条件去搜索树:
1).子节点的数量应该在[ζmin-τ,ζmax+τ],其中ζmin是标签ID=0的时候,除了基线节点之外,所有节点都是黑的的时候的节点数量。ζmax是标签最大id的时候也就是没有黑色节点的时候。τ是允许的公差水平。
2).树的最大深度应正好是3.
在下图中给出了一个示例说明了在9位的拓扑标签中ζmin,ζmin的情况。
差错矫正
标签内部错误的节点的出现是我们无法避免的,其原因可能是噪声等意外,比如上图4d就有一个例子,在这个图像中,在基线节点附近就有一个错误的节点,实际上那边是因为有一个蚂蚁在那里导致。为了能够对错误的节点进行矫正,我们首先计算基线节点的面积,然后对对于小于θ1%基线节点面积的地方进行过滤。图4e中显示了错误矫正之后的结果。
3.2 ID编码
为了进行编码,我们需要指定节点的序列并且需要把他们映射到一个二进制的编码序列。下面,我们以一个16位的拓扑标签为例: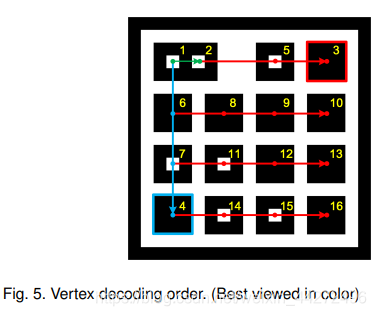
首先,我们先找到基线节点,然后通过可以容忍的角度方向上是否有节点。在这个方向上,我们找到最长的距离的节点,比如p3。对于剩下的节点,我们先找到和基线方向有最大角的节点,然后是这个方向上的最大的节点,p4。p5在p1->p3上,p6,p7在p1->p4上。剩下的节点通过相似的方式按顺序检测。找到各个节点之后,我们就可以根据每一个节点是否包含一个白色的子节点来把他们映射为0,1,然后把这个解码成一个二进制序列。例如图四中,它的二进制编码是10000011000110,解码id就是8390。值得注意的是,为了提高方向搜索的鲁棒性,在去除透视失真之后对图像进行id解码,这样图像中的直线就依然可以是无失真的直线。
3.3 3D位姿估计
对于每一个节点,我们通过计算他的所在区域的质心来估计顶点。所在区域可以是二值化掩膜或者它的扩充区域(扩张尺寸为δ)。质心可以通过图像距来确定。
对于姿态估计,需要二维图像特征和相关模型特征之间的精确对应(特征对应)。为了恢复平面明确的位姿估计,至少需要有四个点。和以往只使用四个角点的工作不同,TopoTag的所有的编码位上的角点都用于更好的姿态估计。正如文献45中说的,对于不同的PnP方法来水哦,大量的特征对应都可以降低误差,更好的估计噪声的姿态,我们参考文献46相似分析了一阶微扰理论下单应估计的稳定性。对于16位标签,使用了16个顶点的对应关系,其中包括2个基线白色点和14个普通的黑色节点。通过求解PnP问题和基于这些特征对应的LevenbergMarquardt 算法,实现了六自由度的姿态估计。
4 结果和讨论
算法设置
在整个实验中,我们使用s1=4,s2=8,w=5α=45,β=50进行分割,τ=0,θ1=30,θ2=0.1 rad进行解码,δ = max{2,l/10}进行顶点估计,其中l是二维掩模区域的段长度。
所有的实验都在一台典型的笔记本上进行的,这台电脑配备了英特尔酷睿i7
-7700HQ处理器(8核@2.8Ghz)和8GB内存。
4.1 标签比较
以前的工作像5,7中提到的,主要集中在评估合成图像的性能。尽管一些工作评估了更加真实的场景中的部分性能,例如ARToolKitPlus[31]评估了几个手持设备上的速度,AprilTag[5],[6]评估了LabelMe[49]数据集上的假阳性,该数据集是为一般的目标检测和识别研究而设计的,但仍然没有统一的基准数据集标记评估。这使得很难再现结果并与其他结果进行比较。最近,在ChromaTag[1]的工作中,他们收集了一个数据集,将他们的工作与AprilTag[5]、CCTag[14]和RuneTag[7]进行比较。然而,不同的标记在其数据集收集期间并排放置,因此不适合进行比较,特别是当从大角度查看标记时,因为不同的标记将具有不同的距离和朝向相机的角度。
在这项工作中,我们试图通过收集一个大的数据集来填补这一空白,包括总共169713幅图像,其中包括平面内和平面外旋转、图像模糊、各种距离和杂乱的背景等。有关我们数据集变化的详细信息,请参阅补充资料。
我们使用的工业相机具有全局快门,分辨率为1280×960,每秒38.8帧,视场为98°。曝光时间被固定为10ms。使用相对长的曝光保证捕获图像的足够亮度,这同时针对更具挑战性的用例引入图像模糊现象(参见图7中的第一图像的示例)。摄像机固定在机器人手臂上以确保不同标签的轨迹相同。图6显示了数据集收集设置。每个标签将收集三个序列,每个序列的轨迹如图8所示。在所有这三个序列中,如图8的第一个图像所示,照相机保持朝向前面。在序列1中,摄像机以恒定的速度沿着几条线移动,每条线的平面外旋转不同,包括0°,30°,60°。在序列2中,相机向后移动,同时在0-180度范围内以恒定的速度在平面内来回旋转。

















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









