






求最大值
greatest()求的是某几列的最大值,横向求最大;
max()通常用于返回列中的最大值,纵向求最大。
TRUNC函数用于对值进行截断。
用法有两种:TRUNC(NUMBER)表示截断数字,TRUNC(date)表示截断日期。
(1)截断数字:
格式:TRUNC(n1,n2),n1表示被截断的数字,n2表示要截断到那一位。n2可以是负数,表示截断小数点前。注意,TRUNC截断不是四舍五入。
SQL> select TRUNC(15.79) from dual;
TRUNC(15.79) ------------ 15
SQL> select TRUNC(15.79,1) from dual;
TRUNC(15.79,1) -------------- 15.7
SQL> select trunc(15.79,-1) from dual;
TRUNC(15.79,-1) --------------- 10
(2)截断日期:
先执行命令:alter session set nls_date_format='yyyy-mm-dd hh24:mi:hh';
1、截取今天:
SQL> select sysdate,trunc(sysdate,'dd') from dual;
SYSDATE TRUNC(SYSDATE,‘DD’) ------------------- 2009-03-24 21:31:17 2009-03-24 00:00:00
2、截取本周第一天:
SQL> select sysdate,trunc(sysdate,'d') from dual;
SYSDATE TRUNC(SYSDATE,‘D’) ------------------- 2009-03-24 21:29:32 2009-03-22 00:00:00
3、截取本月第一天:
SQL> select sysdate,trunc(sysdate,'mm') from dual;
SYSDATE TRUNC(SYSDATE,‘MM’)------------------- 2009-03-24 21:30:30 2009-03-01 00:00:00
4、截取本年第一天:
SQL> select sysdate,trunc(sysdate,'y') from dual;
SYSDATE TRUNC(SYSDATE,‘Y’)------------------- 2009-03-24 21:31:57 2009-01-01 00:00:00
5、截取到小时:
SQL> select sysdate,trunc(sysdate,'hh') from dual;
SYSDATE TRUNC(SYSDATE,‘HH’) ------------------- 2009-03-24 21:32:59 2009-03-24 21:00:00
6、截取到分钟:
SQL> select sysdate,trunc(sysdate,'mi') from dual;
SYSDATE TRUNC(SYSDATE,‘MI’) ------------------- 2009-03-24 21:33:32 2009-03-24 21:33:00
7、获取上月第一天:
SQL> select TRUNC(add_months(SYSDATE,-1),'MM') from dual
MERGE INTO
语法
MERGE INTO语句的基本语法如下:
MERGE INTO target_table [alias]
USING source_table [alias]
ON (join_condition)
WHEN MATCHED THEN
UPDATE SET column1 = value1, column2 = value2, ...
[DELETE WHERE (delete_condition)]
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...) VALUES (value1, value2, ...)
其中:
target_table:目标表的名称或别名。source_table:源表的名称或别名。join_condition:连接条件,用于将目标表和源表进行关联。WHEN MATCHED THEN:当目标表和源表的行匹配时,执行更新操作。UPDATE SET:指定需要更新的目标表的列和对应的值。DELETE WHERE:在更新之前,可选择性地删除目标表的行。WHEN NOT MATCHED THEN:当目标表和源表的行不匹配时,执行插入操作。INSERT:指定需要插入目标表的列和对应的值。
需要注意的是,MERGE INTO语句必须在目标表和源表有相同的列名和数据类型时才能执行成功。此外,还可以使用其他选项和子句来进行更复杂的合并操作。
减一天
ADD_MONTHS(E.RE_DATE, 12) - INTERVAL '1' DAY
自增序列
创建(CREATE)Sequence
创建(CREATE)Sequence
CREATE SEQUENCE [schema_name.]{sequence_name} -- schema_name为将存储序列的模式名,sequence_name 为自定义名称;
START WITH n -- n 为序列的初始值,默认为1;
INCREMENT BY n -- n 为序列步长(序列增加的幅度),默认为1,如果是负则按此步长递减;
[MINVALUE n | NOMINVALUE ] -- 如果序列递减,定义序列生成器能产生的最小值,默认为1
[MAXVALUE n | NOMAXVALUE ] -- 定义序列生成器能产生的最大值,默认无限制(1e28 - 1)
[CACHE n | NOCACHE] -- value 是存放序列的内存块大小,默认20。对序列进行内存缓存可以改善序列性能。
[ORDER | NOORDER] -- 表示序列号是按照请求的顺序生成的。如果使用时间戳的序列号会有用。
[CYCLE | NOCYCLE] -- 值达到限制值后是否循环,如果不循环,达到限制值后,继续产生新值会发生错误 ;Oracle 索引
创建Btree索引(B树索引)
create index OBJECT_ID_idx on table_index(OBJECT_ID);创建bitmap索引(位图索引)
create bitmap index OBJECT_TYPE_idx on table_index(OBJECT_TYPE);bitmap应用场景:
重复率很高的键值;位图索引由于只存储键值的起止Rowid和位图,占用的空间非常少,且在bitmap index中一个dml操作,影响的是一个位图段(同一键值)。严重影响频繁的DML(极其容易造成会话hang住),造成死锁。
函数的索引
CREATE INDEX EMP_SUM_IDX ON hr.EMPLOYEES (SUBSTR(PHONE_NUMBER, 0, 3));创建索引
create index BBS_IDX_ACCOUNTCENTER_CODE on BBS_ENTITY (ENTITY_CODE)
tablespace IFRSUSER --指定索引存储的表空间
pctfree 10 --意味着当往索引数据块中插入新的索引条目时,每个数据块会预留 10% 的空间
不被初始填满,以便后续对该数据块中的索引条目进行更新
initrans 2 --这里设置为 2,表示每个索引数据块在创建时会预留 2 个入口供并发事务访问
该数据块中的索引数据,以适应一定程度的并发操作场景,确保在多个事务同时
访问该索引数据块时能够正常进行处理。
maxtrans 255 --设置为 255,表示一个索引数据块最多可以同时处理 255 个并发事务对其中的
索引数据进行访问、更新等操作。
storage --这部分主要用于详细规定索引数据存储的一些参数
(
initial 64K --指定了索引在创建时最初分配的存储空间大小为 64K 字节
next 1M --表示当最初分配的 64K 存储空间用完后,后续每次为索引扩展存储空间时增加
的大小为 1M 字节
minextents 1 --MINEXTENTS 规定了索引所占用的最小存储扩展数量。这里设置为 1,表示索引
至少会占用一次初始分配的存储空间(即前面提到的 64K),并且后续扩展存储
时也至少会有一次扩展操作(按照 NEXT 参数指定的大小)。
maxextents unlimited --MAXEXTENTS 用于设定索引所能占用的最大存储扩展数量。设置为 UNLIMITED
意味着索引在存储增长方面没有上限限制,只要数据库所在的存储设备有足够
的空间,索引可以不断地按照 NEXT 参数指定的方式扩展存储空间以适应数据
量的增加和索引自身的增长。
);创建表
-- Create/Recreate primary, unique and foreign key constraints
alter table BBS_ENTITY
add constraint PK_BPL_CONFIGCENTER_ID primary key (ENTITY_ID)
using index
tablespace IFRSUSER
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
LISTAGG()
LISTAGG 函数介绍
listagg 函数是 Oracle 11.2 推出的新特性。
其主要功能类似于 wmsys.wm_concat 函数, 即将数据分组后, 把指定列的数据再通过指定符号合并。
LISTAGG 使用
listagg 函数有两个参数:
1、 要合并的列名
2、 自定义连接符号
☆LISTAGG 函数既是分析函数,也是聚合函数
所以,它有两种用法:
1、分析函数,如: row_number()、rank()、dense_rank() 等,用法相似
listagg(合并字段, 连接符) within group(order by 合并的字段的排序) over(partition by 分组字段)
2、聚合函数,如:sum()、count()、avg()等,用法相似
listagg(合并字段, 连接符) within group(order by 合并字段排序) --后面跟 group by 语句
一部分聚合函数其实也可以写成分析函数的形式。
分析函数和聚合函数本质上都是对数据进行分组,二者最大的不同便是:
对数据进行分组分组之后,
聚合函数只会每组返回一条数据,
而分析函数会针对每条记录都返回,
一部分分析函数还会对同一组中的数据进行一些处理(比如:rank() 函数对每组中的数据进行编号);
还有一部分分析函数不会对同一组中的数据进行处理(比如:sum()、listagg()),这种情况下,分析函数返回的数据会有重复的,distinct 处理之后的结果与对应的聚合函数返回的结果一致。
分析(窗口)函数:NTH_VALUE
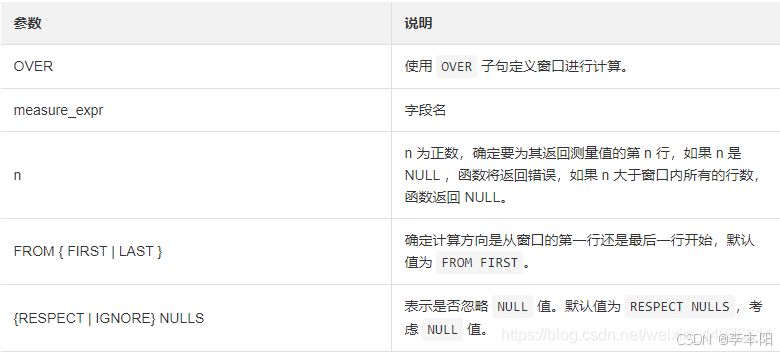
NTH_VALUE 返回 analytic_clause 定义的窗口中第 n 行的 measure_expr 值。返回的值具有 measure_expr 的数据类型。
NTH_VALUE (measure_expr, n) [ FROM { FIRST | LAST } ][ { RESPECT | IGNORE } NULLS ]
OVER (analytic_clause)
SELECT deptno
,ename
,sal
,nth_value(sal, 3)OVER (PARTITION BY deptno ORDER BY sal DESC
rows BETWEEN unbounded preceding AND unbounded following) AS third_most_sal
FROM emp_msg ORDER BY deptno,sal DESC;-- 默认为当前行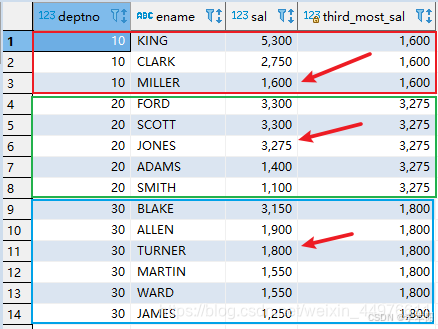

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









