







前言
亲爱的家人们,创作很不容易,若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力,谢谢大家!有问题请私信或联系邮箱:fn_kobe@163.com。
1、二叉树
定义:一种非线性数据结构,代表“祖先”与“后代”之间派生关系,体现“一分为二”分治逻辑。基本单元是节点,每个节点包含值、左子节点引用和右子节点引用。
/* 二叉树节点类 */
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点引用
TreeNode right; // 右子节点引用
TreeNode(int x) { val = x; }
}
详细描述:每个节点有两个引用(指针),分别指向左子节点和右子节点,该节点被称为这两个子节点父节点。当给定一个二叉树节点时,将该节点的左子节点及其以下节点形成的树称为该节点的左子树,同理可得右子树。在二叉树中,除叶节点外,其他所有节点都包含子节点和非空子树。
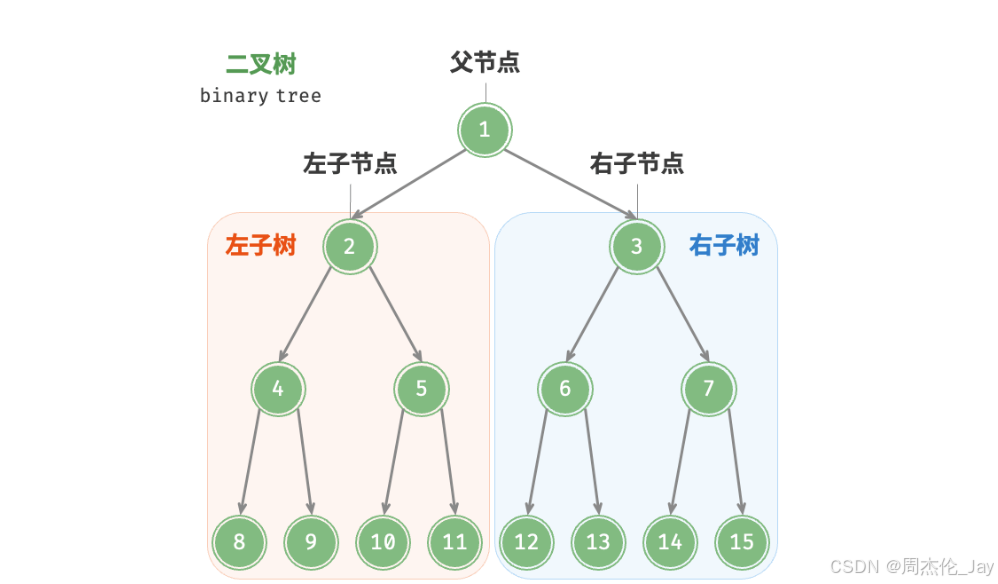
1.1、二叉树基本术语
根节点:位于二叉树顶层的节点,没有父节点。
叶节点:没有子节点的节点,其两个指针均指向 None 。
边:连接两个节点的线段,即节点引用(指针)。
节点所在层:从顶至底递增,根节点所在层为 1 。
节点度:节点的子节点的数量。在二叉树中,度的取值范围是 0、1、2 。
二叉树高度:从根节点到最远叶节点所经过的边的数量。
节点深度:从根节点到该节点所经过的边的数量。
节点高度:从距离该节点最远的叶节点到该节点所经过的边的数量。
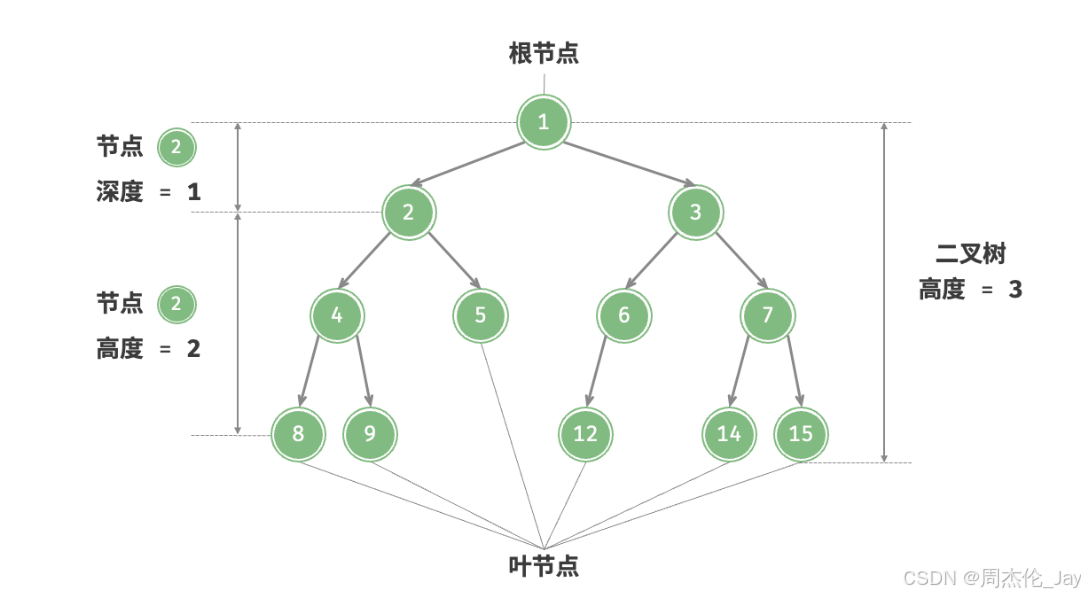
1.2、二叉树基本操作
1.2.1、初始化二叉树
// 初始化节点
TreeNode n1 = new TreeNode(1);
TreeNode n2 = new TreeNode(2);
TreeNode n3 = new TreeNode(3);
TreeNode n4 = new TreeNode(4);
TreeNode n5 = new TreeNode(5);
// 构建节点之间的引用(指针)
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;
1.2.2、插入与删除节点
通过修改指针来实现。
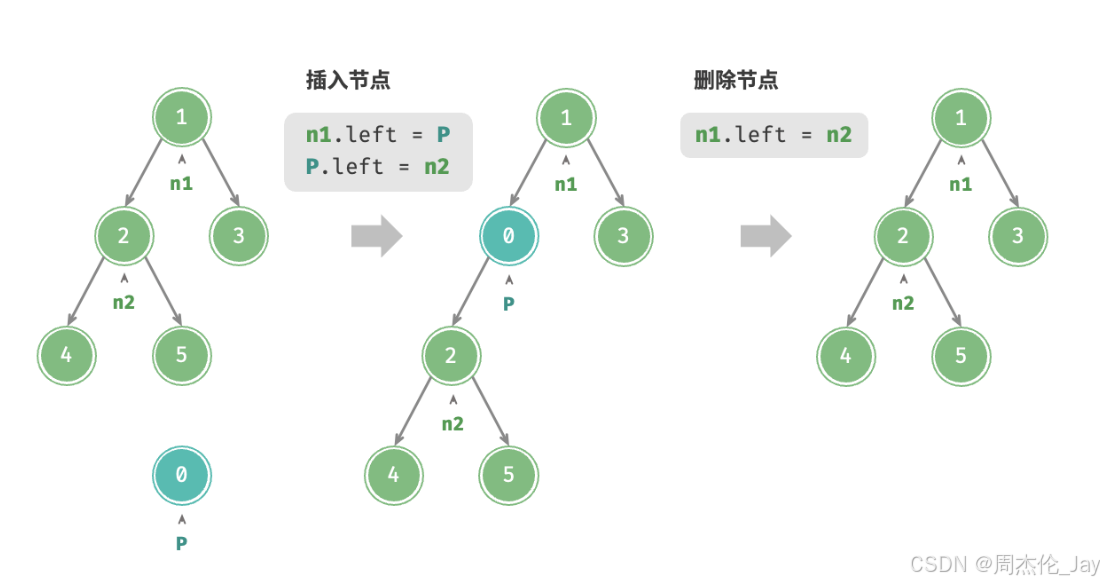
TreeNode P = new TreeNode(0);
// 在 n1 -> n2 中间插入节点 P
n1.left = P;
P.left = n2;
// 删除节点 P
n1.left = n2;
1.3、常见二叉树类型
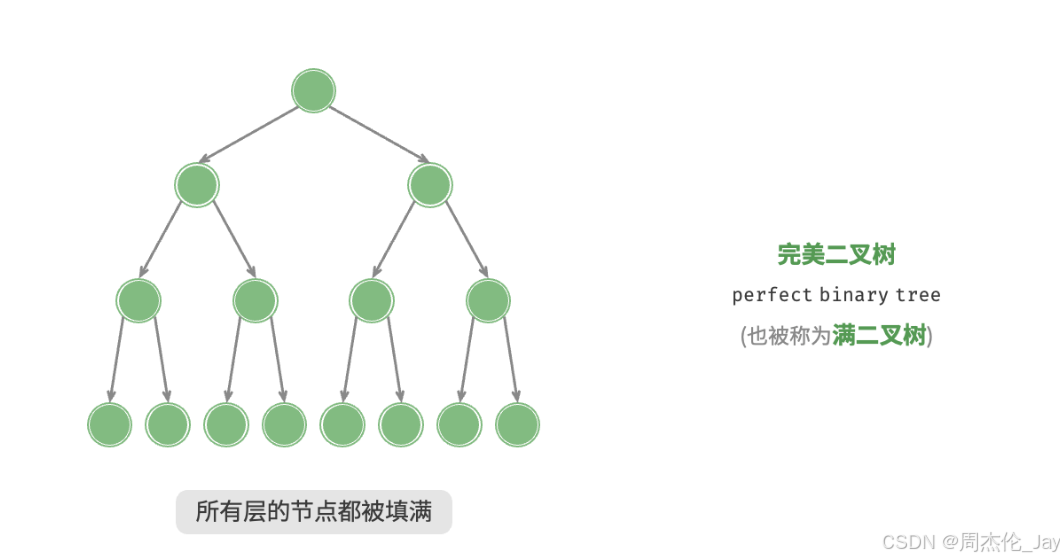
1.3.1、满二叉树
所有层的节点都被完全填满。在完美二叉树中,叶节点的度为0,其余所有节点度都为 2;若树的高度为 h,则节点总数为2的(h+1)次方 - 1,呈现标准的指数级关系。
1.3.2、完全二叉树
只有最底层节点未被填满,且最底层节点尽量靠左填充。完美二叉树也是一棵完全二叉树。
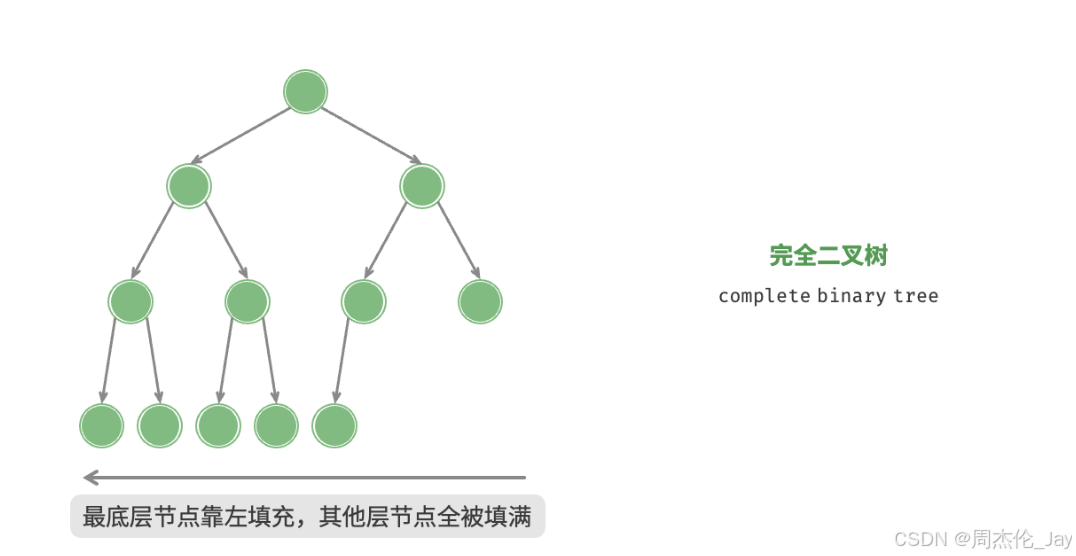
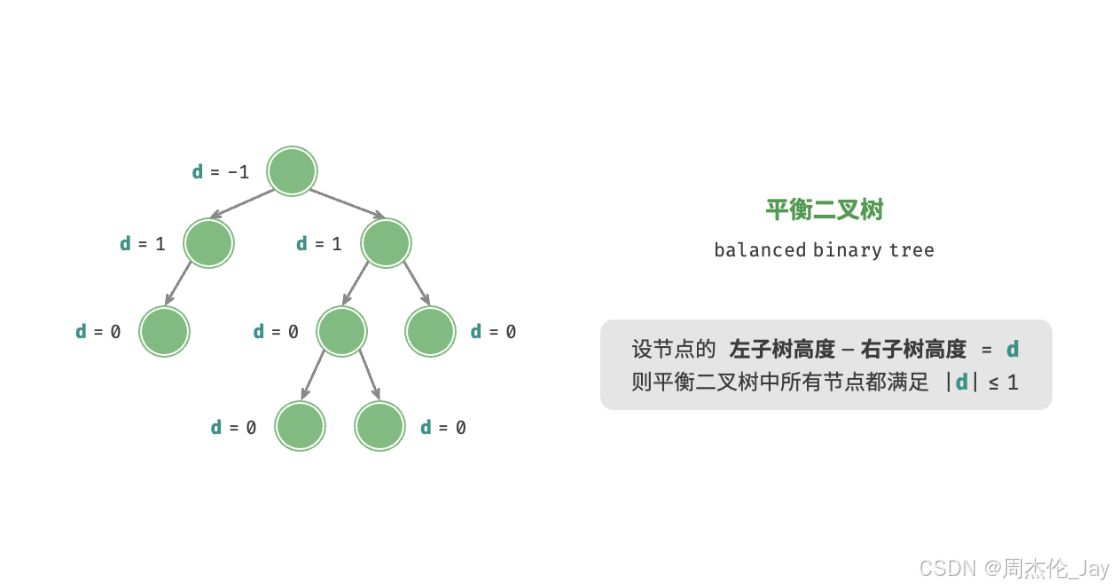
1.3.3、平衡二叉树
任意节点的左子树和右子树的高度之差的绝对值不超过 1 。
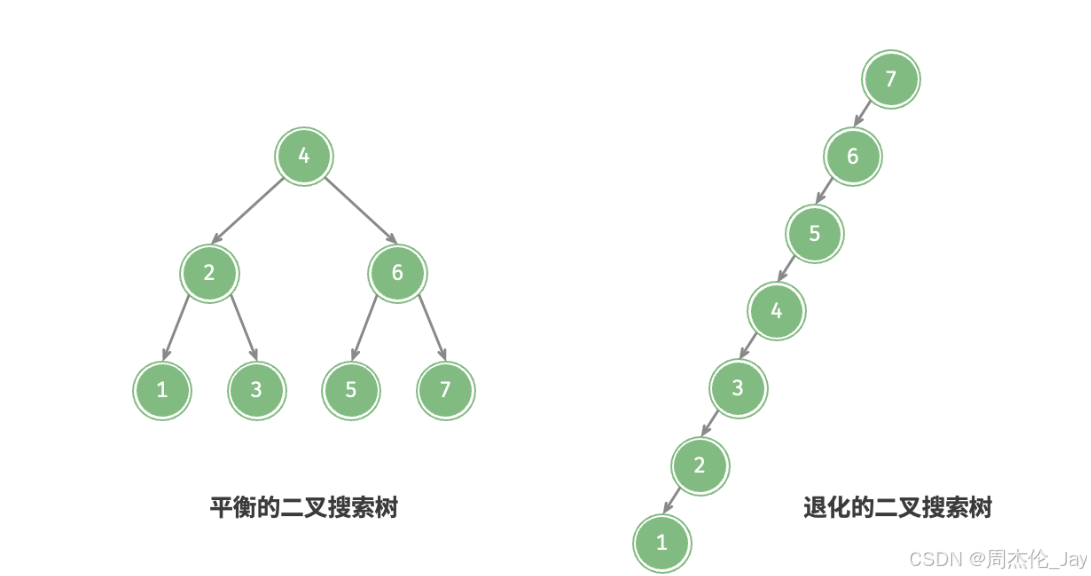
1.4、二叉树退化
当二叉树每层节点都被填满时,达到“满二叉树”;而当所有节点都偏向一侧时,二叉树退化为“链表”。
完美二叉树是理想情况,充分发挥二叉树“分治”优势。链表则是另一个极端,各项操作都变为线性操作,时间复杂度退化至O(n)。
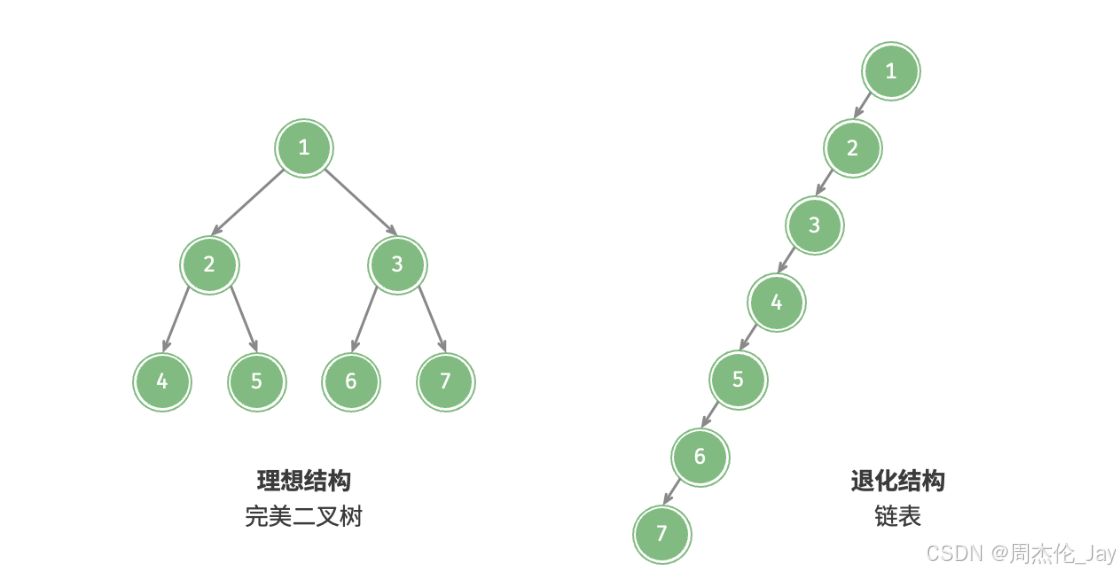
结构对比:最佳结构和最差结构下,二叉树的叶节点数量、节点总数、高度等达到极大值或极小值。

2、二叉树遍历
物理结构:树是一种基于链表数据结构,其遍历方式是通过指针逐个访问节点。然而,树是一种非线性数据结构,遍历树比遍历链表更加复杂,需要借助搜索算法来实现。
常见遍历方式:层序遍历、前序遍历、中序遍历和后序遍历。
2.1、层序遍历
2.1.1、过程描述
从顶部到底部逐层遍历二叉树,并在每一层按照从左到右顺序访问节点。层序遍历本质属于广度优先遍历(BFS),体现一种“一圈一圈向外扩展”的逐层遍历方式。
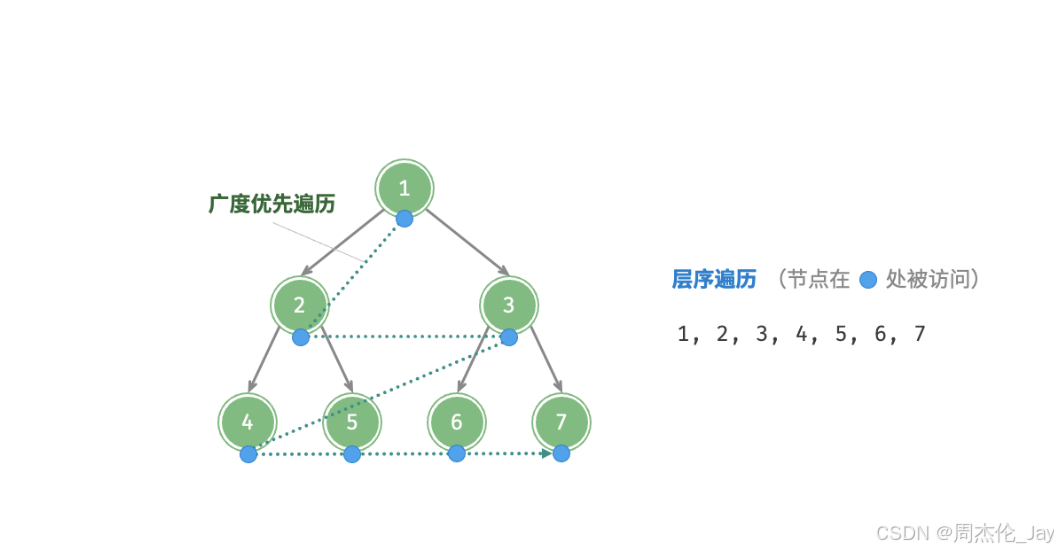
2.1.2、代码实现
/* 层序遍历 */
List<Integer> levelOrder(TreeNode root) {
// 初始化队列,加入根节点
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
// 初始化一个列表,用于保存遍历序列
List<Integer> list = new ArrayList<>();
while (!queue.isEmpty()) {
TreeNode node = queue.poll(); // 队列出队
list.add(node.val); // 保存节点值
if (node.left != null)
queue.offer(node.left); // 左子节点入队
if (node.right != null)
queue.offer(node.right); // 右子节点入队
}
return list;
}
2.1.3、复杂度分析
时间复杂度为 O(n):所有节点被访问一次,使用 O(n)时间,其中n为节点数量。
空间复杂度为 O(n):在最差情况下,即满二叉树时,遍历到最底层之前,队列中最多同时存在( n+1)/2个节点,占用 O(n)空间。
2.2、前序、中序、后序遍历
2.2.1、过程描述
前序、中序和后序遍历都属于深度优先遍历(DFS),体现一种“先走到尽头,再回溯继续”遍历方式。
深度优先遍历绕着整棵二叉树的外围“走”一圈,在每个节点都会遇到三个位置,分别对应前序遍历、中序遍历和后序遍历。
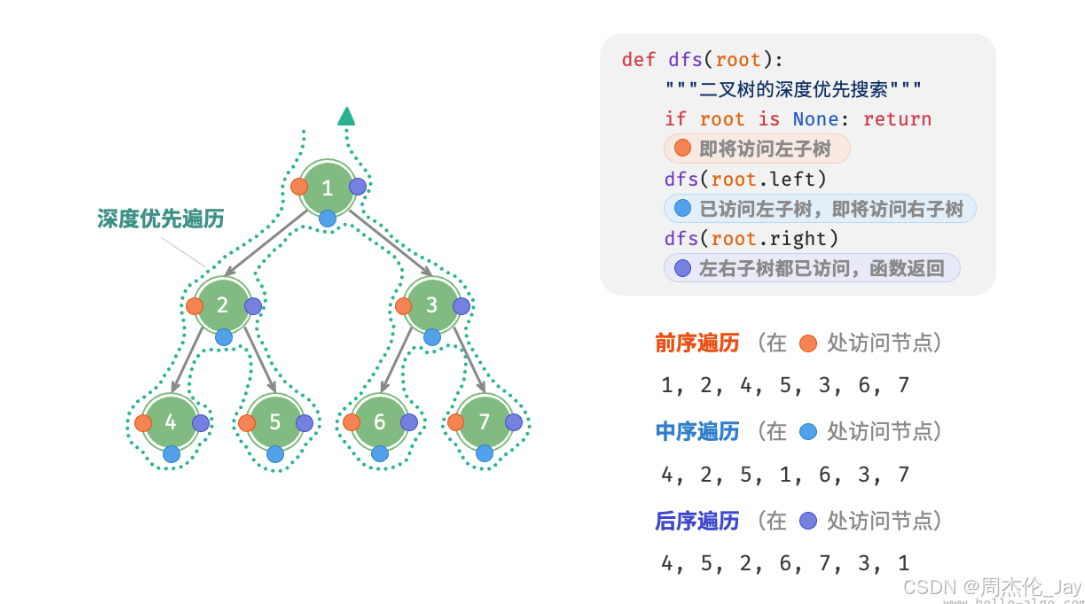
2.2.2、代码实现
/* 前序遍历 */
void preOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:根节点 -> 左子树 -> 右子树
list.add(root.val);
preOrder(root.left);
preOrder(root.right);
}
/* 中序遍历 */
void inOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:左子树 -> 根节点 -> 右子树
inOrder(root.left);
list.add(root.val);
inOrder(root.right);
}
/* 后序遍历 */
void postOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:左子树 -> 右子树 -> 根节点
postOrder(root.left);
postOrder(root.right);
list.add(root.val);
}
2.2.3、复杂度分析
时间复杂度为 O(n):所有节点被访问一次,使用 O(n)时间,其中n为节点数量。
空间复杂度为 O(n):在最差情况下,树退化为链表时,递归深度达到 n,占用 O(n)空间。
3、二叉树数组表示
3.1、表示满二叉树
层序遍历映射公式:若某节点的索引为 i,则该节点的左子节点索引为 2i+1 ,右子节点索引为2i+2。
映射公式的角色相当于链表中的节点引用(指针)
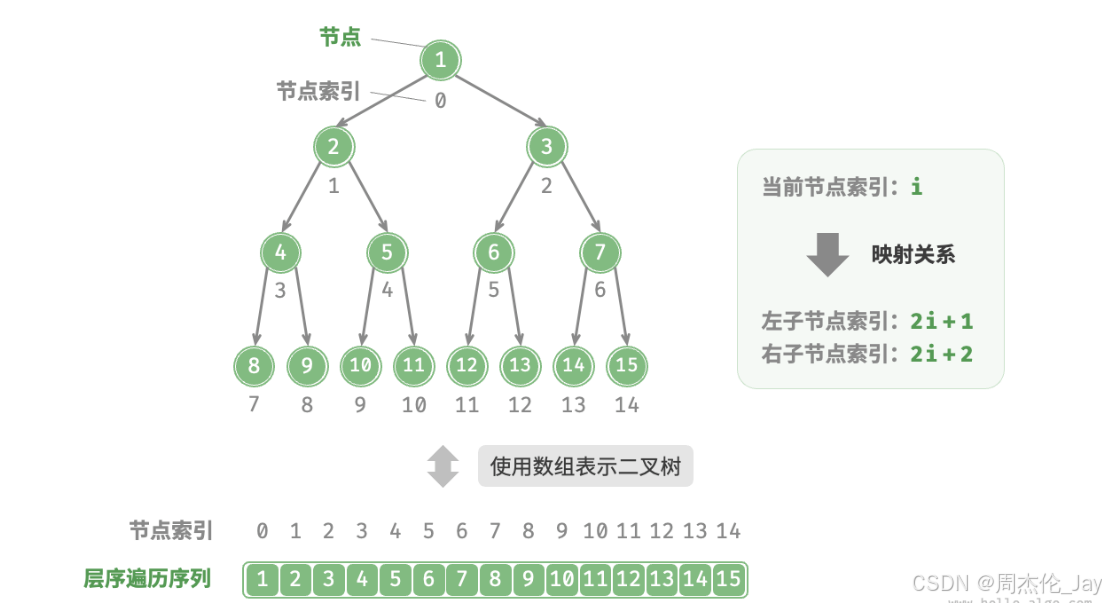
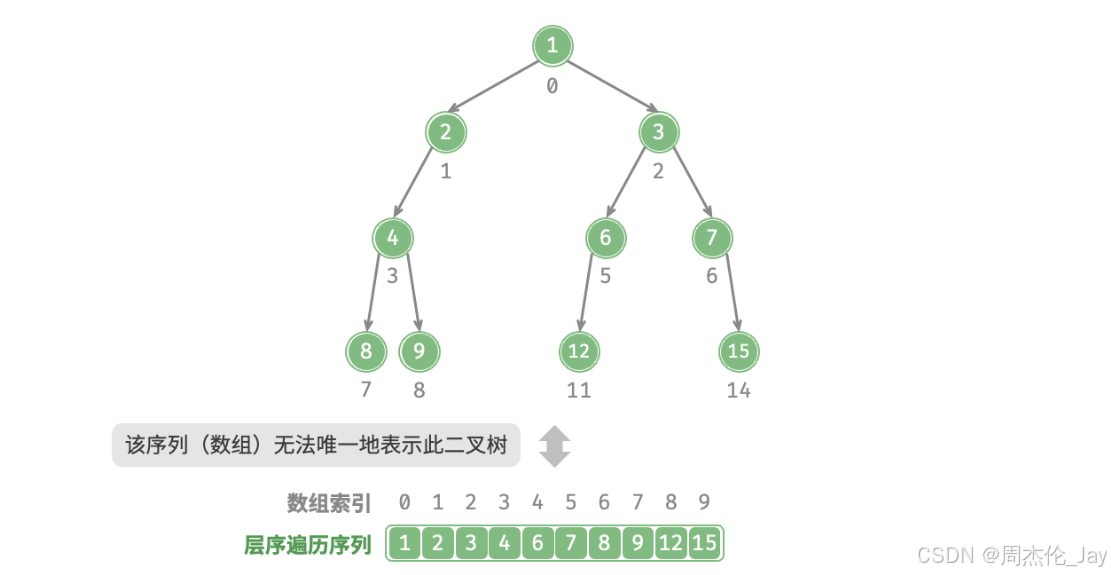
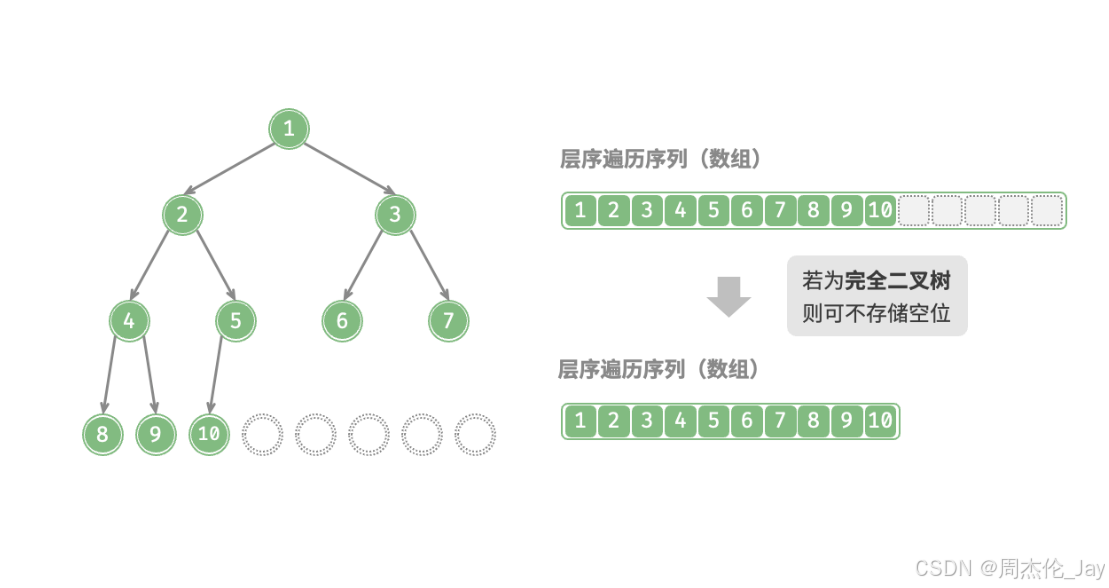
3.2、表示任意二叉树
问题:完美二叉树是特例,在二叉树中间层通常存在许多 None 。由于层序遍历序列并不包含这些 None ,无法仅凭该序列来推测None数量和分布位置。
解决办法:在层序遍历序列中显式地写出所有 None。
在这里插入代码片/* 二叉树的数组表示 */
// 使用 int 的包装类 Integer ,就可以使用 null 来标记空位
Integer[] tree = { 1, 2, 3, 4, null, 6, 7, 8, 9, null, null, 12, null, null, 15 };
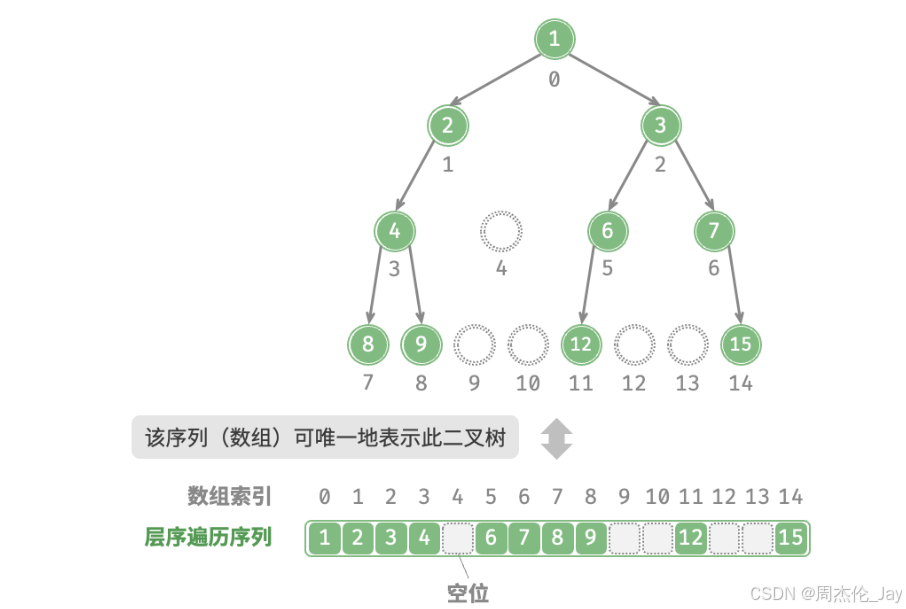
说明:完全二叉树非常适合使用数组来表示。回顾完全二叉树定义,None只出现在最底层且靠右位置,所有None一定出现在层序遍历序列的末尾。
/* 数组表示下的二叉树类 */
class ArrayBinaryTree {
private List<Integer> tree;
/* 构造方法 */
public ArrayBinaryTree(List<Integer> arr) {
tree = new ArrayList<>(arr);
}
/* 列表容量 */
public int size() {
return tree.size();
}
/* 获取索引为 i 节点的值 */
public Integer val(int i) {
// 若索引越界,则返回 null ,代表空位
if (i < 0 || i >= size())
return null;
return tree.get(i);
}
/* 获取索引为 i 节点的左子节点的索引 */
public Integer left(int i) {
return 2 * i + 1;
}
/* 获取索引为 i 节点的右子节点的索引 */
public Integer right(int i) {
return 2 * i + 2;
}
/* 获取索引为 i 节点的父节点的索引 */
public Integer parent(int i) {
return (i - 1) / 2;
}
/* 层序遍历 */
public List<Integer> levelOrder() {
List<Integer> res = new ArrayList<>();
// 直接遍历数组
for (int i = 0; i < size(); i++) {
if (val(i) != null)
res.add(val(i));
}
return res;
}
/* 深度优先遍历 */
private void dfs(Integer i, String order, List<Integer> res) {
// 若为空位,则返回
if (val(i) == null)
return;
// 前序遍历
if ("pre".equals(order))
res.add(val(i));
dfs(left(i), order, res);
// 中序遍历
if ("in".equals(order))
res.add(val(i));
dfs(right(i), order, res);
// 后序遍历
if ("post".equals(order))
res.add(val(i));
}
/* 前序遍历 */
public List<Integer> preOrder() {
List<Integer> res = new ArrayList<>();
dfs(0, "pre", res);
return res;
}
/* 中序遍历 */
public List<Integer> inOrder() {
List<Integer> res = new ArrayList<>();
dfs(0, "in", res);
return res;
}
/* 后序遍历 */
public List<Integer> postOrder() {
List<Integer> res = new ArrayList<>();
dfs(0, "post", res);
return res;
}
}
3.3、优点与局限性
数组表示优点:
数组存储在连续的内存空间中,对缓存友好,访问与遍历速度较快。
不需要存储指针,比较节省空间。
允许随机访问节点。
局限性:
数组存储需要连续内存空间,不适合存储数据量过大的树。
增删节点需要通过数组插入与删除操作实现,效率较低。
当二叉树中存在大量None时,数组中包含的节点数据比重较低,空间利用率较低。
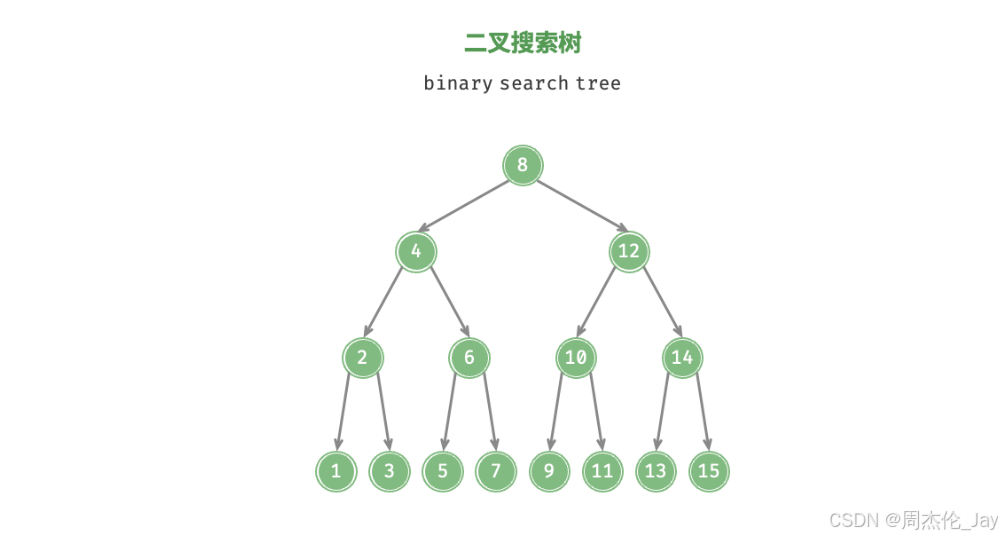
4、二叉搜索树
满足条件:
对于根节点,左子树中所有节点的值<根节点的值<右子树中所有节点的值。
任意节点的左、右子树也是二叉搜索树,即同样满足条件 1 。
4.1、二叉搜索树操作
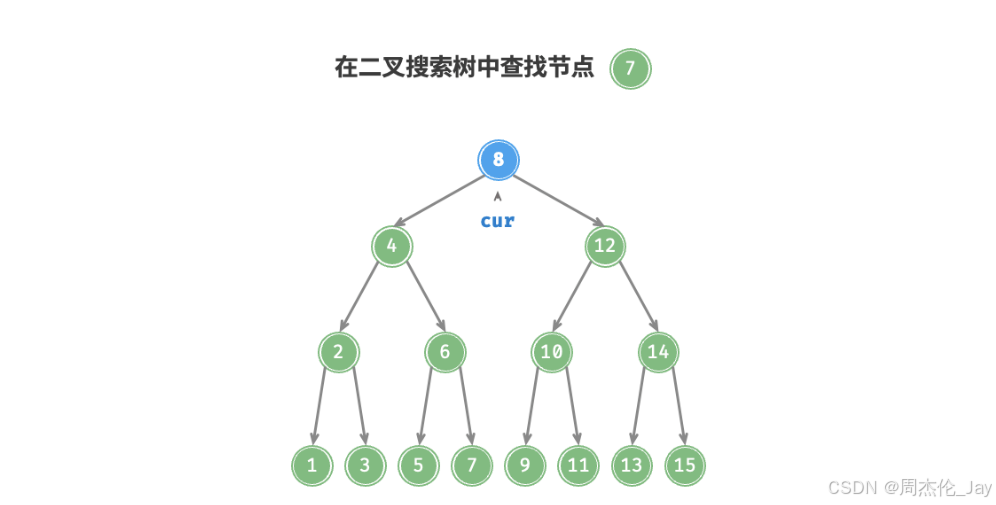
4.1.1、查找节点
过程:给定目标节点值 num ,根据二叉搜索树性质来查找。声明一个节点cur ,从二叉树根节点root出发,循环比较节点值cur.val和num之间大小关系。
若 cur.val < num ,说明目标节点在cur右子树中,执行cur = cur.right 。
若 cur.val > num ,说明目标节点在cur的左子树中,执行cur = cur.left 。
若 cur.val = num ,说明找到目标节点,跳出循环并返回该节点。
说明:二叉搜索树的查找操作与二分查找算法的工作原理一致,都是每轮排除一半情况。循环次数最多为二叉树的高度。当二叉树平衡时,使用O(log n)时间
/* 查找节点 */
TreeNode search(int num) {
TreeNode cur = root;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 目标节点在 cur 的右子树中
if (cur.val < num)
cur = cur.right;
// 目标节点在 cur 的左子树中
else if (cur.val > num)
cur = cur.left;
// 找到目标节点,跳出循环
else
break;
}
// 返回目标节点
return cur;
}
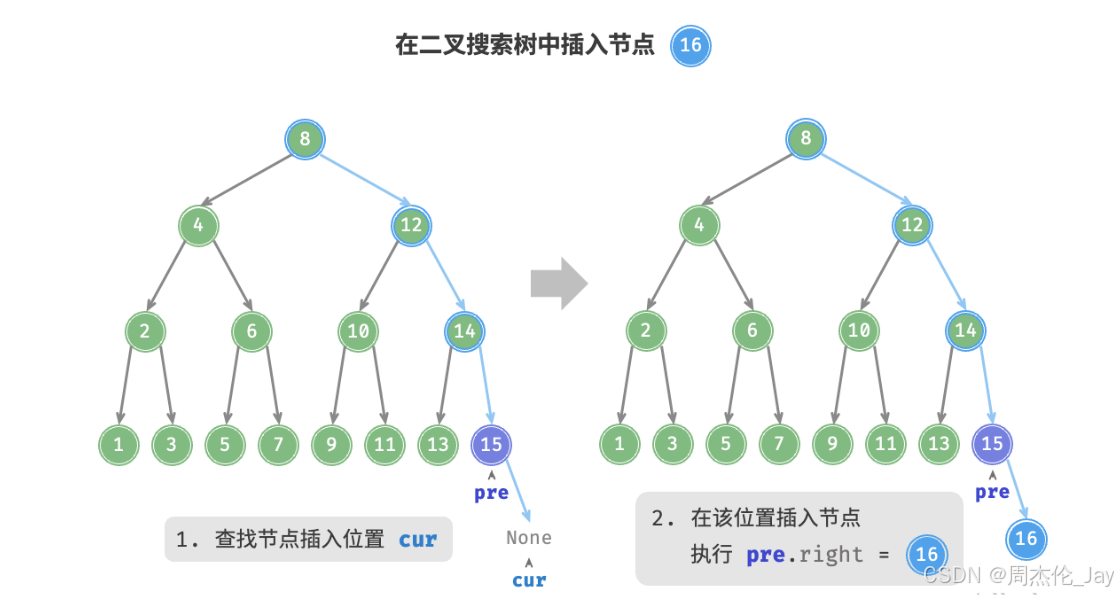
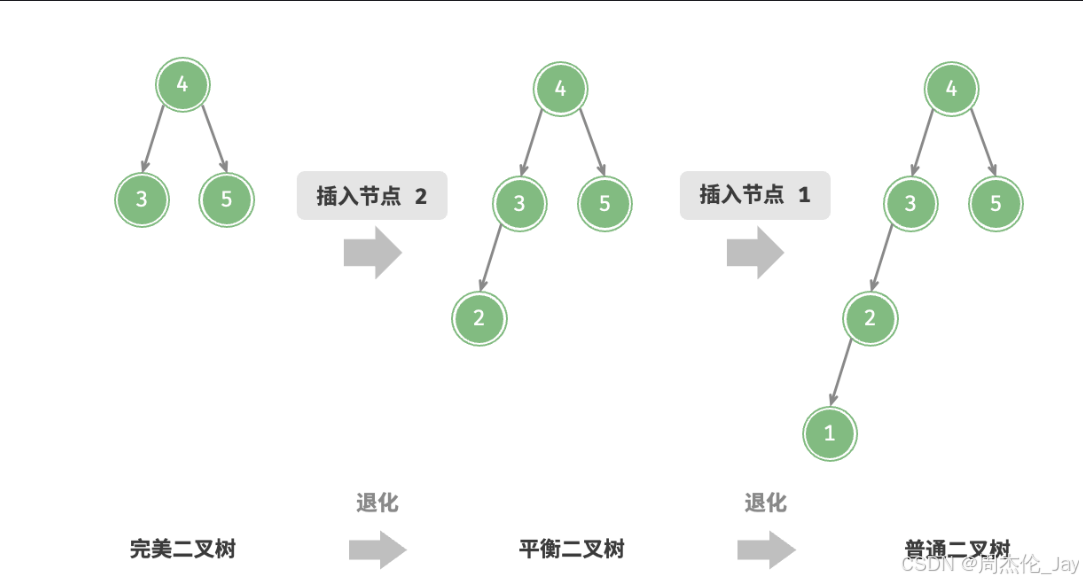
4.1.2、插入节点
给定一个待插入元素num ,保持二叉搜索树“左子树 < 根节点 < 右子树”性质。
插入操作流程如下:
**查找插入位置:**与查找操作相似,从根节点出发,根据当前节点值和num的大小关系循环向下搜索,直到越过叶节点(遍历至 None )时跳出循环。
在该位置插入节点:初始化节点 num ,将该节点置于 None 的位置。
说明:
二叉搜索树不允许存在重复节点,否则将违反其定义。若待插入节点在树中已存在,则不执行插入,直接返回。
为了实现插入节点,借助节点 pre 保存上一轮循环的节点。在遍历至 None 时,获取到其父节点,完成节点插入操作。
/* 插入节点 */
void insert(int num) {
// 若树为空,则初始化根节点
if (root == null) {
root = new TreeNode(num);
return;
}
TreeNode cur = root, pre = null;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 找到重复节点,直接返回
if (cur.val == num)
return;
pre = cur;
// 插入位置在 cur 的右子树中
if (cur.val < num)
cur = cur.right;
// 插入位置在 cur 的左子树中
else
cur = cur.left;
}
// 插入节点
TreeNode node = new TreeNode(num);
if (pre.val < num)
pre.right = node;
else
pre.left = node;
}
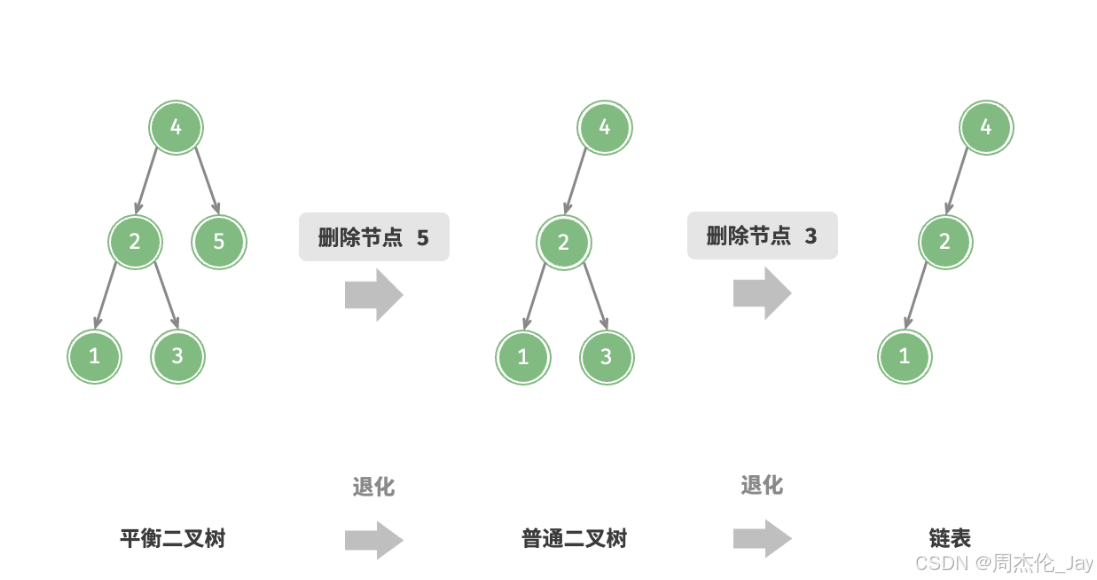
4.1.3、删除节点
过程:先在二叉树中查找到目标节点,再将其删除。与插入节点类似,保证在删除操作完成后,二叉搜索树的“左子树 < 根节点 < 右子树”的性质仍然满足。根据目标节点的子节点数量,分 0、1 和 2 三种情况,执行对应删除节点操作。
删除节点操作同样使用O(log n)时间,其中查找待删除节点需要O(log n)时间,获取中序遍历后继节点需要O(log n)时间。
①删除节点的度为0时,表示该节点是叶节点:直接删除。
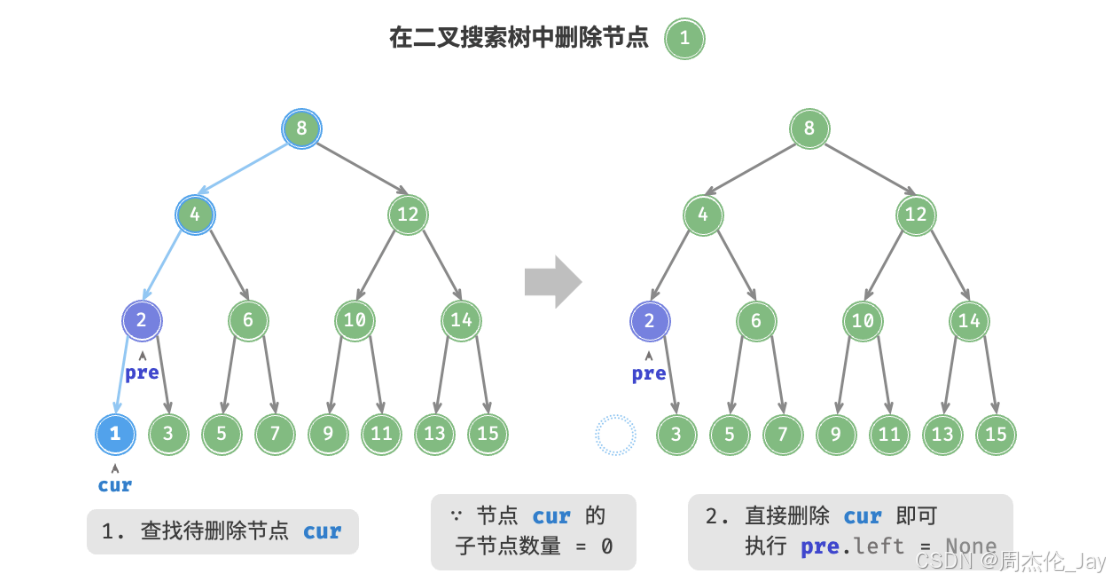
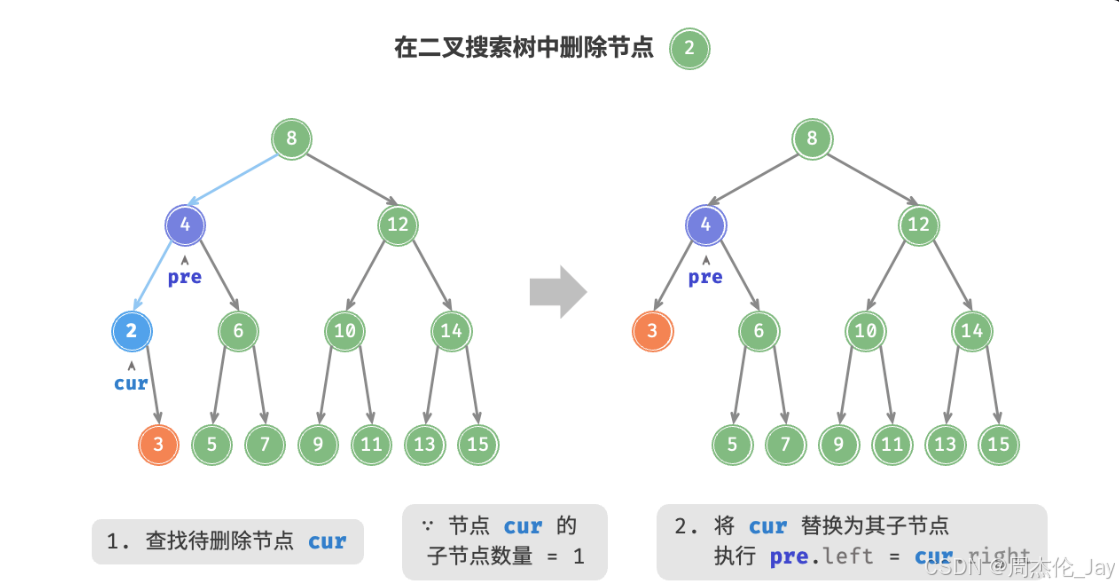
②删除节点度为1时,将待删除节点替换为其子节点
③删除节点度为2时,无法直接删除它,而需要使用一个节点替换该节点。由于要保持二叉搜索树“左子树<根节点 <右子树”的性质,这个节点是右子树的最小节点或左子树的最大节点。
选择右子树的最小节点(中序遍历的下一个节点),则删除操作流程如下:
找到待删除节点在“中序遍历序列”中的下一个节点,记为 tmp 。
用 tmp 的值覆盖待删除节点的值,并在树中递归删除节点 tmp 。
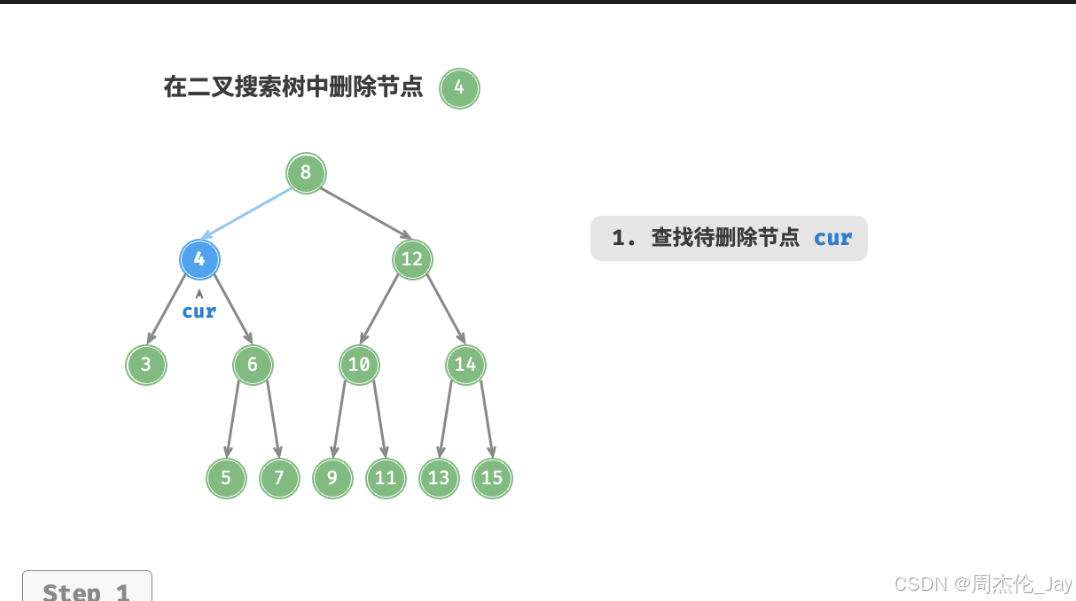
/* 删除节点 */
void remove(int num) {
// 若树为空,直接提前返回
if (root == null)
return;
TreeNode cur = root, pre = null;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 找到待删除节点,跳出循环
if (cur.val == num)
break;
pre = cur;
// 待删除节点在 cur 的右子树中
if (cur.val < num)
cur = cur.right;
// 待删除节点在 cur 的左子树中
else
cur = cur.left;
}
// 若无待删除节点,则直接返回
if (cur == null)
return;
// 子节点数量 = 0 or 1
if (cur.left == null || cur.right == null) {
// 当子节点数量 = 0 / 1 时, child = null / 该子节点
TreeNode child = cur.left != null ? cur.left : cur.right;
// 删除节点 cur
if (cur != root) {
if (pre.left == cur)
pre.left = child;
else
pre.right = child;
} else {
// 若删除节点为根节点,则重新指定根节点
root = child;
}
}
// 子节点数量 = 2
else {
// 获取中序遍历中 cur 的下一个节点
TreeNode tmp = cur.right;
while (tmp.left != null) {
tmp = tmp.left;
}
// 递归删除节点 tmp
remove(tmp.val);
// 用 tmp 覆盖 cur
cur.val = tmp.val;
}
}
4.2、中序遍历有序
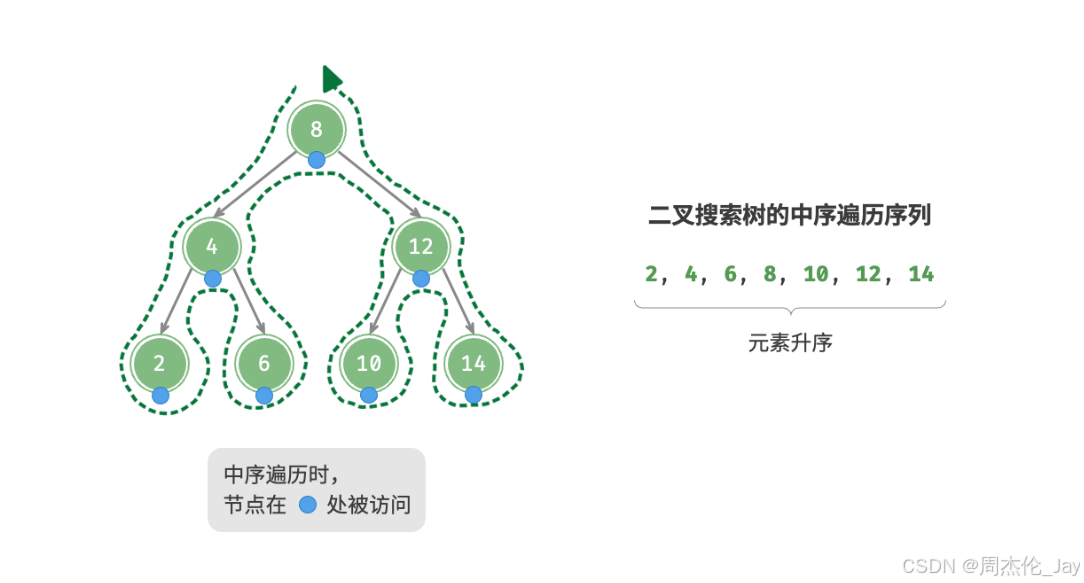
二叉树的中序遍历遵循“左<根<右”的遍历顺序,而二叉搜索树满足“左子节点<根节点 <右子节点”的大小关系。
二叉搜索树中进行中序遍历,总是会优先遍历下一个最小节点,从而得出一个重要性质:二叉搜索树的中序遍历序列是升序。
利用中序遍历升序性质,在二叉搜索树中获取有序数据仅需O(n)时间,无须进行额外的排序操作,非常高效。
4.3、二叉搜索树效率
给定一组数据,考虑使用数组或二叉搜索树存储。二叉搜索树的各项操作时间复杂度都是对数阶,具有稳定且高效的性能。只有在高频添加、低频查找删除数的场景下,数组比二叉搜索树的效率更高。

说明:理想情况下,二叉搜索树是“平衡”的,在log n轮循环内查找任意节点。然而,在二叉搜索树中不断地插入和删除节点,可能导致二叉树退化为链表,这时各种操作时间复杂度也会退化为 O(n)。
4.4、二叉搜索树效应用
①用作系统中的多级索引,实现高效的查找、插入、删除操作。
②作为某些搜索算法的底层数据结构。
③用于存储数据流,以保持其有序状态。
5、AVL树
在多次插入和删除操作后,二叉搜索树可能退化为链表。
5.1、AVL树术语
AVL 树既是二叉搜索树,也是平衡二叉树,同时满足这两类二叉树的所有性质,是一种平衡二叉搜索树。
①节点高度
由于AVL树的相关操作需要获取节点高度,为节点类添加height 变量。
/* AVL 树节点类 */
class TreeNode {
public int val; // 节点值
public int height; // 节点高度
public TreeNode left; // 左子节点
public TreeNode right; // 右子节点
public TreeNode(int x) { val = x; }
}
节点高度:从该节点到它的最远叶节点距离,所经过“边”数量。需要特别注意的是,叶节点的高度为0 ,而空节点的高度为-1。
/* 获取节点高度 */
int height(TreeNode node) {
// 空节点高度为 -1 ,叶节点高度为 0
return node == null ? -1 : node.height;
}
/* 更新节点高度 */
void updateHeight(TreeNode node) {
// 节点高度等于最高子树高度 + 1
node.height = Math.max(height(node.left), height(node.right)) + 1;
}
② 节点平衡因子
节点平衡因子(balance factor)定义为节点左子树的高度减去右子树的高度,同时规定空节点的平衡因子为0 。
/* 获取平衡因子 */
int balanceFactor(TreeNode node) {
// 空节点平衡因子为 0
if (node == null)
return 0;
// 节点平衡因子 = 左子树高度 - 右子树高度
return height(node.left) - height(node.right);
}
5.2、AVL树旋转
AVL树特点:“旋转”操作,能够在不影响二叉树中序遍历序列前提下,使失衡节点重新恢复平衡。旋转操作既能保持“二叉搜索树”性质,也能使树重新变为“平衡二叉树”。
旋转操作分为四种:右旋、左旋、先右旋后左旋、先左旋后右旋。
右旋和左旋操作在逻辑上是镜像对称的,它们分别解决的两种失衡情况也是对称的
5.2.1、右旋
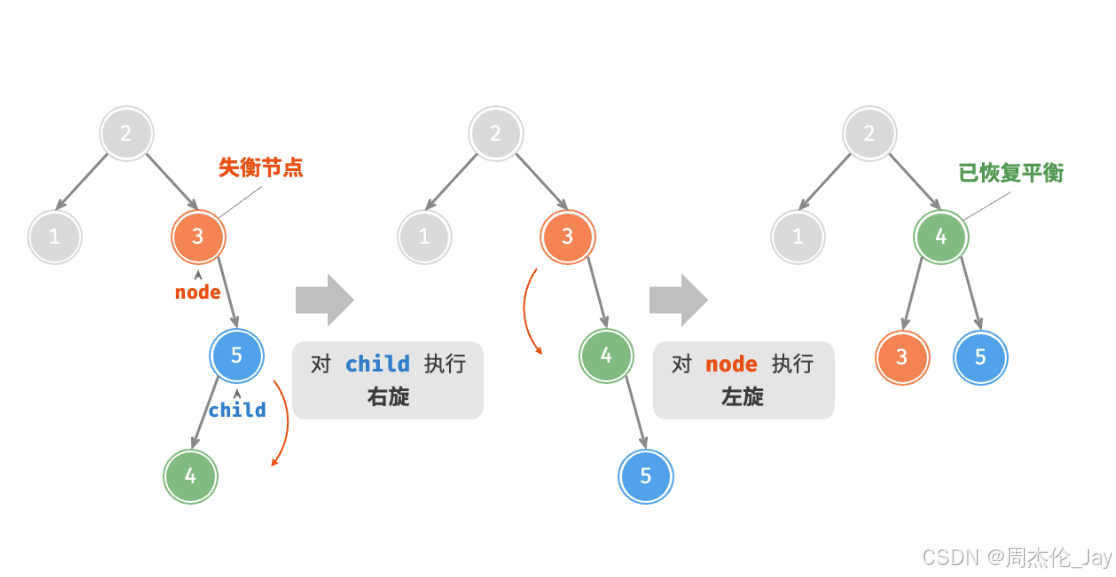
节点下方为平衡因子。从底至顶看,二叉树中首个失衡节点是“节点 3”。以该失衡节点为根节点的子树,将该节点记为 node ,其左子节点记为 child ,执行“右旋”操作。完成右旋后,子树恢复平衡,并且仍然保持二叉搜索树的性质。
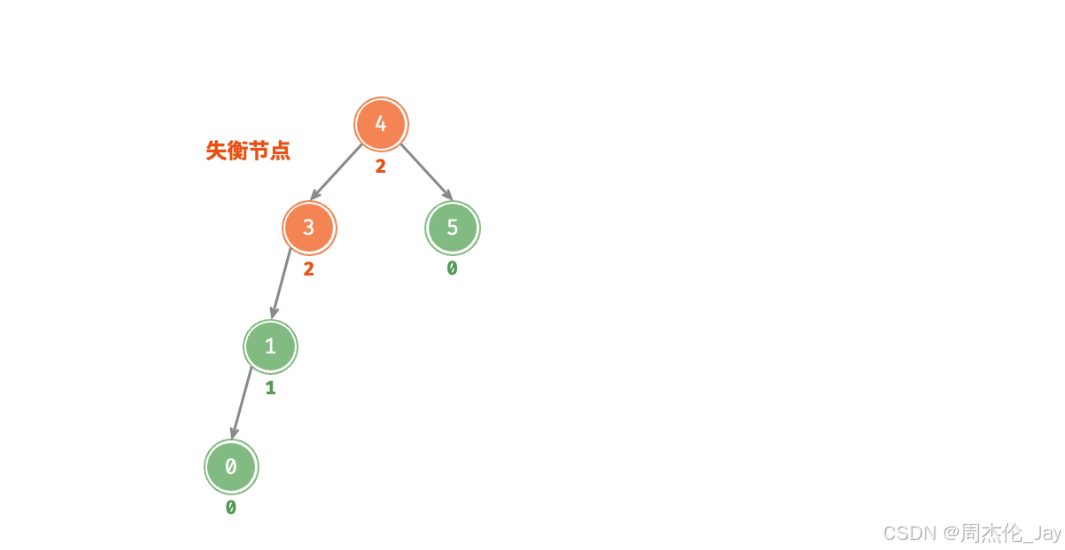
当节点 child 有右子节点(记为 grand_child )时,需要在右旋中添加一步:将 grand_child 作为 node 的左子节点
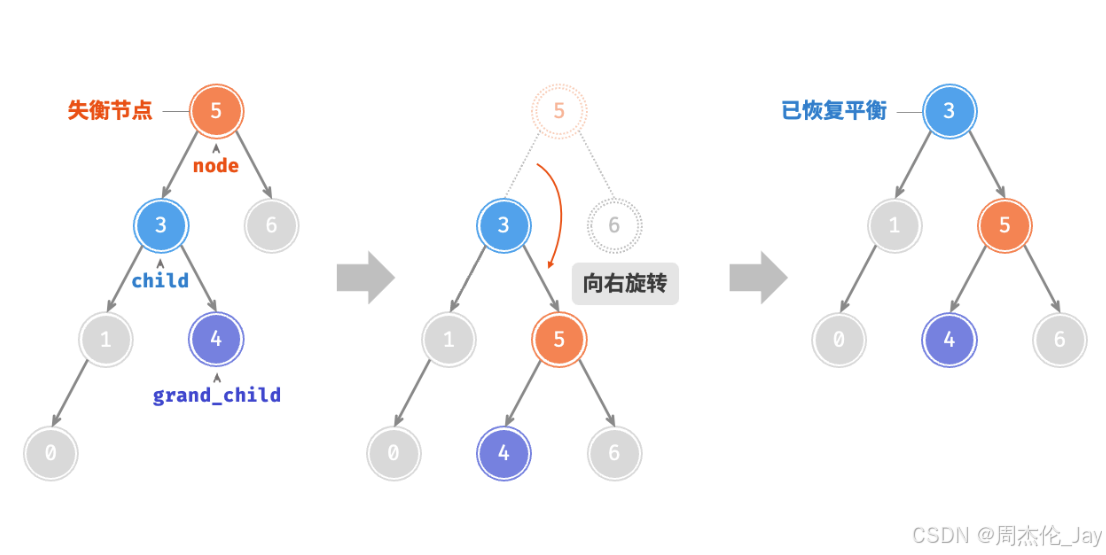
/* 右旋操作 */
TreeNode rightRotate(TreeNode node) {
TreeNode child = node.left;
TreeNode grandChild = child.right;
// 以 child 为原点,将 node 向右旋转
child.right = node;
node.left = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
5.2.2、左旋
相应地,如果考虑上述失衡二叉树的“镜像”。
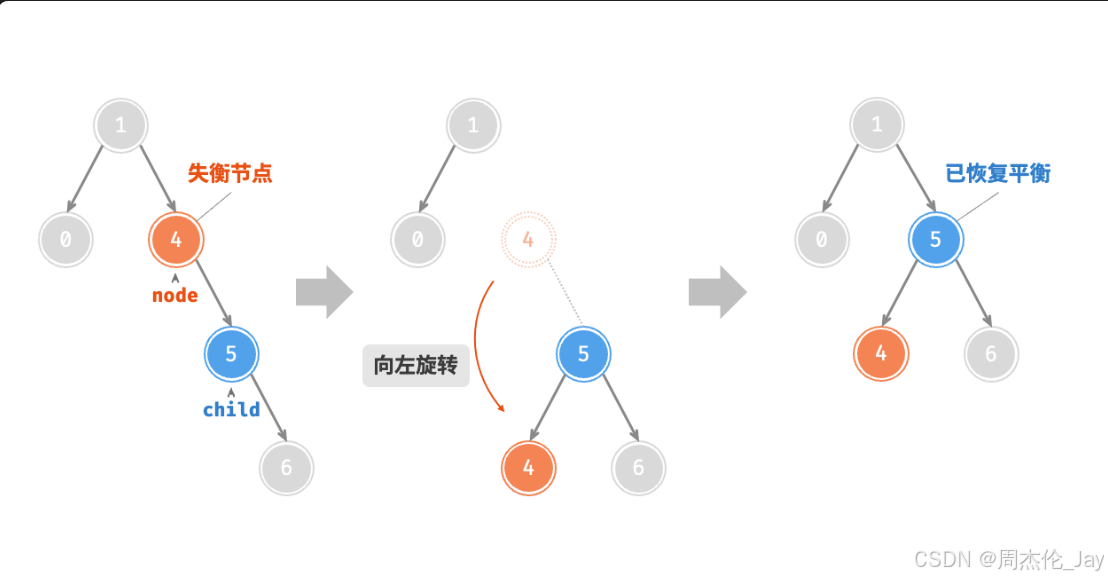
当节点 child 有左子节点(记为 grand_child )时,需要在左旋中添加一步:将 grand_child 作为 node 的右子节点。
/* 左旋操作 */
TreeNode leftRotate(TreeNode node) {
TreeNode child = node.right;
TreeNode grandChild = child.left;
// 以 child 为原点,将 node 向左旋转
child.left = node;
node.right = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
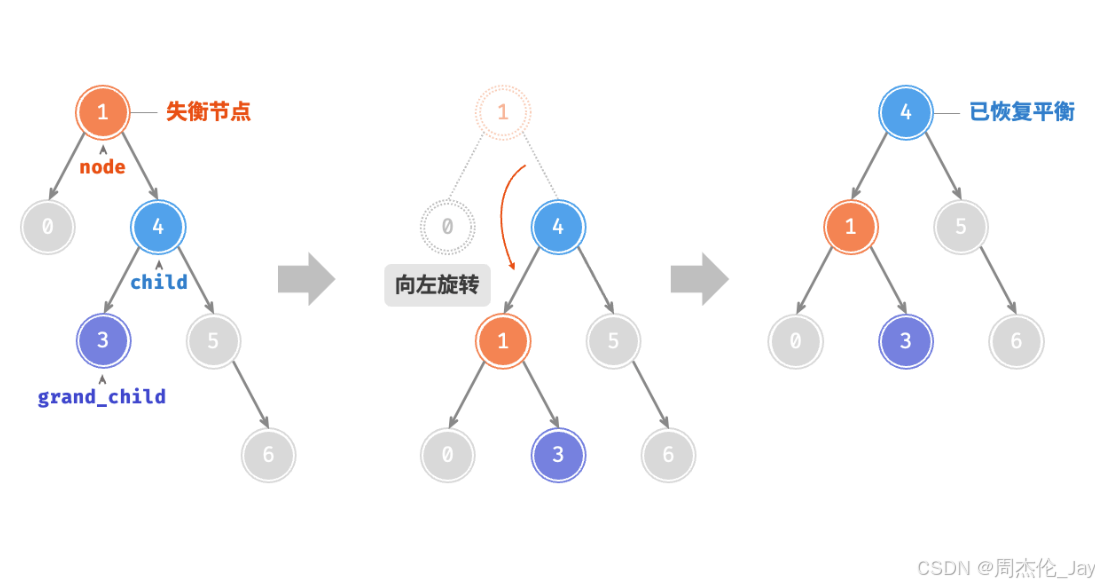
5.2.3、先左旋后右旋
失衡节点 3 ,仅使用左旋或右旋都无法使子树恢复平衡。此时需要先对 child 执行“左旋”,再对 node 执行“右旋”。
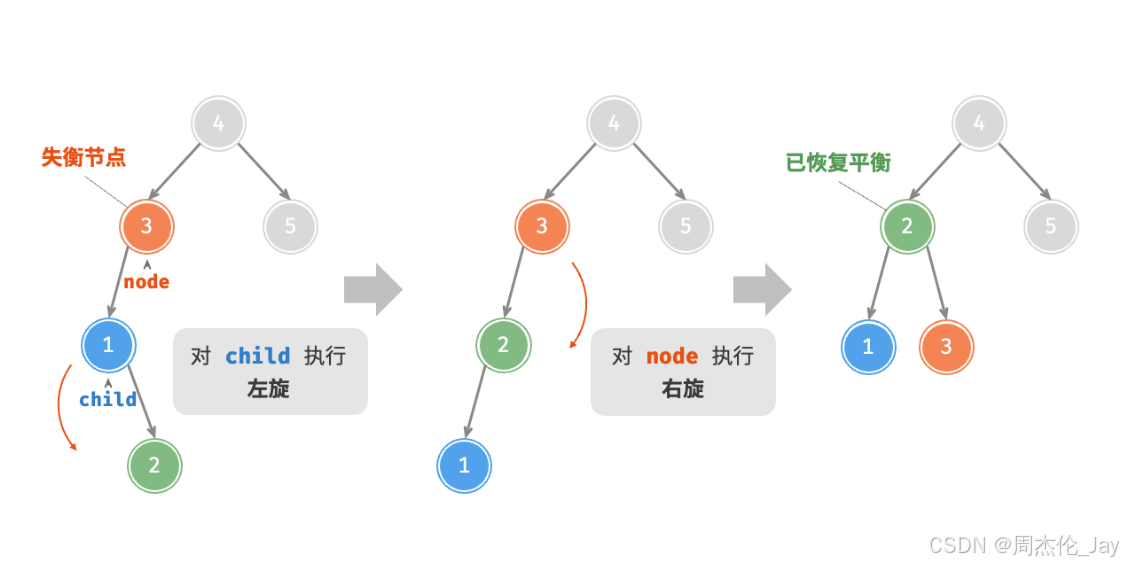
5.2.4、先右旋后左旋
对于上述失衡二叉树的镜像情况,需要先对 child 执行“右旋”,再对 node 执行“左旋”。
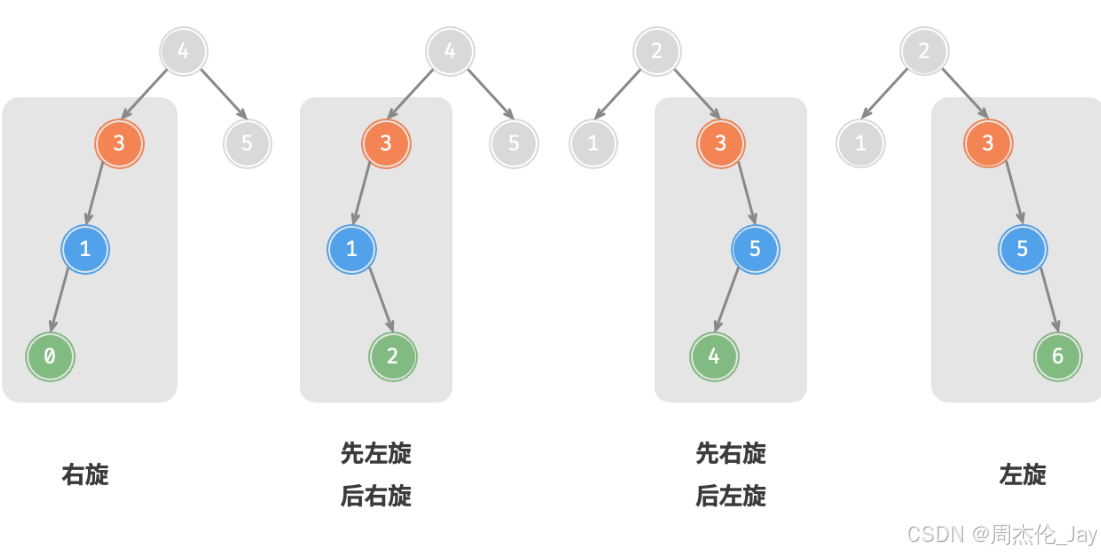
5.3、旋转的选择
四种失衡情况与上述案例逐个对应,分别需要采用右旋、先左旋后右旋、先右旋后左旋、左旋的操作。
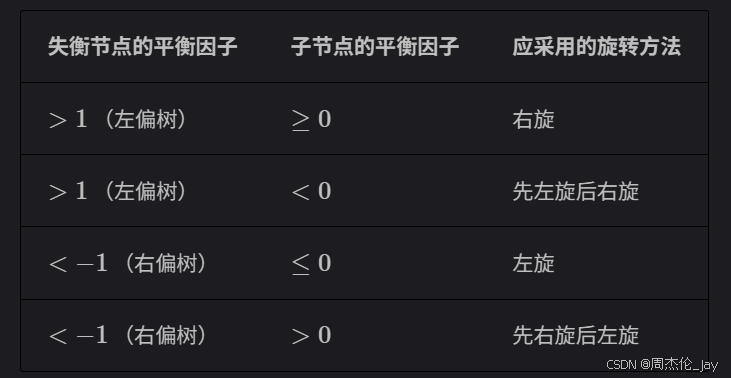
通过判断失衡节点的平衡因子以及较高一侧子节点的平衡因子的正负号,来确定失衡节点
/* 执行旋转操作,使该子树重新恢复平衡 */
TreeNode rotate(TreeNode node) {
// 获取节点 node 的平衡因子
int balanceFactor = balanceFactor(node);
// 左偏树
if (balanceFactor > 1) {
if (balanceFactor(node.left) >= 0) {
// 右旋
return rightRotate(node);
} else {
// 先左旋后右旋
node.left = leftRotate(node.left);
return rightRotate(node);
}
}
// 右偏树
if (balanceFactor < -1) {
if (balanceFactor(node.right) <= 0) {
// 左旋
return leftRotate(node);
} else {
// 先右旋后左旋
node.right = rightRotate(node.right);
return leftRotate(node);
}
}
// 平衡树,无须旋转,直接返回
return node;
}
5.4、AVL树常用操作
5.4.1、插入节点
节点插入操作与二叉搜索树在主体上类似。唯一的区别在于,在 AVL 树中插入节点后,从该节点到根节点的路径上可能会出现一系列失衡节点。需要从这个节点开始,自底向上执行旋转操作,使所有失衡节点恢复平衡。
/* 插入节点 */
void insert(int val) {
root = insertHelper(root, val);
}
/* 递归插入节点(辅助方法) */
TreeNode insertHelper(TreeNode node, int val) {
if (node == null)
return new TreeNode(val);
/* 1. 查找插入位置并插入节点 */
if (val < node.val)
node.left = insertHelper(node.left, val);
else if (val > node.val)
node.right = insertHelper(node.right, val);
else
return node; // 重复节点不插入,直接返回
updateHeight(node); // 更新节点高度
/* 2. 执行旋转操作,使该子树重新恢复平衡 */
node = rotate(node);
// 返回子树的根节点
return node;
}
5.4.2、删除节点
在二叉搜索树的删除节点方法的基础上,需要从底至顶执行旋转操作,使所有失衡节点恢复平衡。
/* 删除节点 */
void remove(int val) {
root = removeHelper(root, val);
}
/* 递归删除节点(辅助方法) */
TreeNode removeHelper(TreeNode node, int val) {
if (node == null)
return null;
/* 1. 查找节点并删除 */
if (val < node.val)
node.left = removeHelper(node.left, val);
else if (val > node.val)
node.right = removeHelper(node.right, val);
else {
if (node.left == null || node.right == null) {
TreeNode child = node.left != null ? node.left : node.right;
// 子节点数量 = 0 ,直接删除 node 并返回
if (child == null)
return null;
// 子节点数量 = 1 ,直接删除 node
else
node = child;
} else {
// 子节点数量 = 2 ,则将中序遍历的下个节点删除,并用该节点替换当前节点
TreeNode temp = node.right;
while (temp.left != null) {
temp = temp.left;
}
node.right = removeHelper(node.right, temp.val);
node.val = temp.val;
}
}
updateHeight(node); // 更新节点高度
/* 2. 执行旋转操作,使该子树重新恢复平衡 */
node = rotate(node);
// 返回子树的根节点
return node;
}
5.4.3、插入节点
AVL 树的节点查找操作与二叉搜索树一致。
5.5、AVL 树典型应用
①组织和存储大型数据,适用于高频查找、低频增删的场景。
②用于构建数据库中的索引系统。
③红黑树是一种常见平衡二叉搜索树。相较于AVL树,红黑树平衡条件更宽松,插入与删除节点所需旋转操作更少,节点增删操作平均效率更高。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











