 BMTN:多任务学习新框架
BMTN:多任务学习新框架







 BMTN是一种新型多任务学习框架,由Luc van Gool团队提出,旨在自动搜索网络分支位置,解决多任务学习中共享特征层的问题。通过度量任务关联性,BMTN能够构建最优分支任务网络,提高模型效率与性能。
BMTN是一种新型多任务学习框架,由Luc van Gool团队提出,旨在自动搜索网络分支位置,解决多任务学习中共享特征层的问题。通过度量任务关联性,BMTN能够构建最优分支任务网络,提高模型效率与性能。
1. 多任务学习网络
随着ICCV2017最佳论文授予kaiming大神的Mask-RCNN,多任务网络成为了新的研究热点。Mask-RCNN基于目标检测框架,在RoI pooling层后设计两个并行的子网络:一个分支是原始的目标检测分支,即判断物体类别和回归边框,另一个分支实现其他任务,如实例分割或人体关键点检测等,多任务同时学习提高了各自任务的性能(相比单独训练某个任务)。无独有偶,CVPR2018最佳论文颁给了Taskonomy。Taskonomy的主要目标是发掘不同视觉任务间的关联性,从而避免关联任务的重复学习,减少对标注数据的需求,同时提供了一个容易扩展和泛化性较强的多任务学习框架,尤其是对数据量有限的新任务的学习具有重要意义。尽管作者不认为taskonomy是多任务学习,但是可以用来解决多任务学习的问题。自此,多任务学习彻底成为深度学习领域的热门方向,新的研究成果层出不穷。
2. Branched Multi-Task Networks (BMTN)
论文地址:https://arxiv.org/abs/1904.02920
近期,来自ETH和鲁汶大学的Luc van Gool(计算机视觉大师,surf特征的作者)团队提出了一个新的多任务学习框架,主要思路借鉴了Taskonomy,但是又有所区别。作者认为不同视觉任务间可能会共享不同层次的特征,即具有不同程度的关联性,网络越深,学到的特征对某个任务越有针对性。因此,BMTN重点解决如下问题:对于共享某些底层特征的多个任务,到底需要共享哪些层的特征,从哪层特征开始需要针对各自任务设计分支。BMTN提出一种新的思路,自动搜索网络分支位置,来解决过去针对具体需求按照经验设计分支的位置的问题。论文提出的思想在一定程度上与Meta-Learning和NAS(Neural Architecture Searching)有概念重合。
与Taskonomy类似,BMTN也分为四个步骤,但是第三步与第四步与前者有本质的不同。方法框架如下图所示:
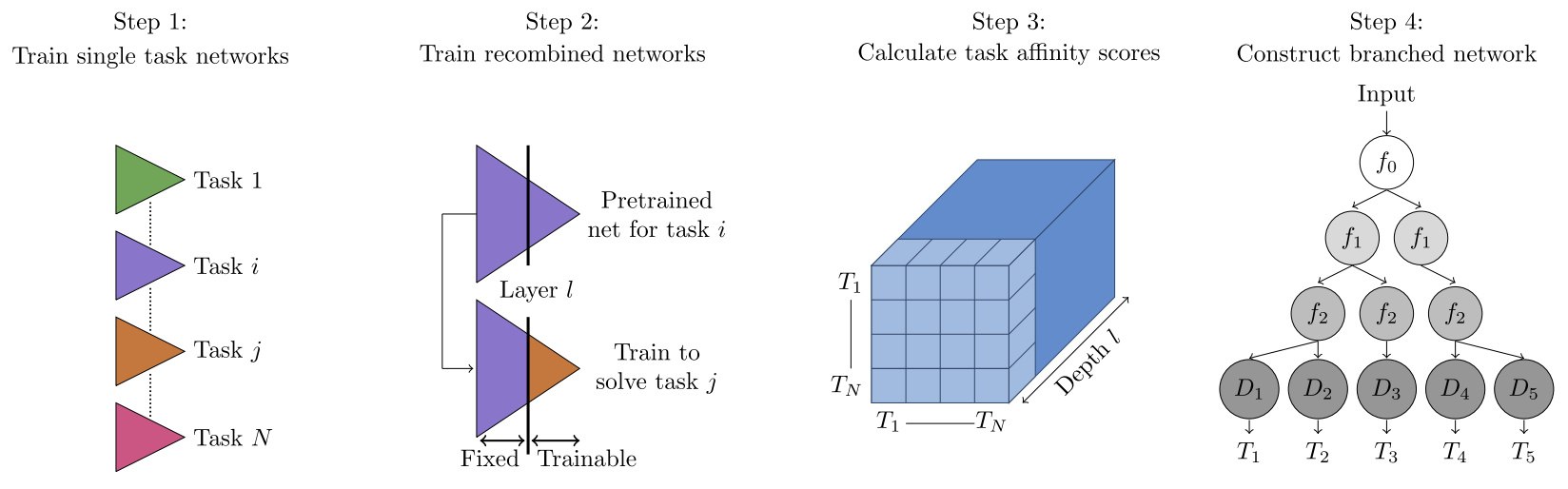
图1.BMTN四个步骤。Step 1:对每个任务从零开始各自训练自己的模型。Step 2:将所有任务两两配对,使用任务A的前l层训练好的网络替换任务B的前l层网络,微调任务B后L-l层网络。Step 3:定义度量任务关联程度的performance matrix。Step 4:定义损失函数,通过优化算法搜索最优分支位置。
Step 1:训练单任务网络
针对每个任务 t i ∈ T t_i \in \mathcal{T} ti∈T,训练各自的单任务网络。这些单任务网络的Ecoder部分完全相同,后面接一个与任务相关的Decoder,这个Decoder可以是一个上采样卷积网络,实现像素级操作的任务,如语义分割等,也可以是一个级联的全连层,实现诸如分类的任务。相比Encoder,Decoder是一个非常小的网络结构。
Step 2:训练重新组合的网络
将任务 t i t_i ti单任务网络的前 l l l层,使用其他一个已经训练好的单任务网络 t j t_j tj的前 l l l层进行替换,保持这部分权重不变,微调任务 t i t_i ti剩余网络的权重。如果任务 t i t_i ti与 t j t_j tj有较强的关联性,经过替换权重之后, t i t_i ti应该保持类似的性能或者性能变化不大,否则,性能会下降。这种性能上的变化在下一步用作度量多任务之间的关联性。
Step 3:计算任务关联性度量分数
对于任务 t l t_l tl,按照第二个步骤的方法,使用任意一个任务 t i t_i ti替换其encoder,若使用微调后的loss作为度量可比性较差,因此本文借鉴Taskonomy的做法,构建了一个Performance Matrix。对于任务 t l t_l tl,使用任务 t i t_i ti和任务 t j t_j tj分别替换其encoder并微调,然后在一个hold-out测试集上测试准确率。令,
w i j = 用 t i 替 换 t l 的 网 络 优 于 用 t j 替 换 t l 的 网 络 的 测 试 样 本 个 数 用 t i 替 换 t l 的 网 络 劣 于 用 t j 替 换 t l 的 网 络 的 测 试 样 本 个 数 w_{ij}= \frac{用t_i替换t_l的网络优于用t_j替换t_l的网络的测试样本个数}{用t_i替换t_l的网络劣于用t_j替换t_l的网络的测试样本个数} wij=用ti替换tl的网络劣于用tj替换tl的网络的测试样本个数用ti替换tl的网络优于用tj替换tl的网络的测试样本个数。
对于任务 t l t_l tl,可以构建一个对比矩阵 W t l ∈ R N × N W_{t_l} \in R^{N \times N} Wtl∈RN×N, N N N为任务个数,每个元素 w i j w_{ij} wij上面的公式得到。使用层次分析法(Analytic Hierarchy Process, AHP)分析矩阵 W t l W_{t_l} Wtl,具体方法解释参考这里。简单来说,计算 W t l W_{t_l} Wtl最大特征值对应的特征向量 v v v,将 v v v归一化,即 v ′ = v / ∣ v ∣ v'=v/|v| v′=v/∣v∣。 v ′ v' v′中第 i i i个元素对应任务 t i t_i ti与任务 t l t_l tl的关联程度。将所有 N N N个任务的关联度量堆叠到一起,构成Performance Matrix: P ∈ R N × N P \in R^{N \times N} P∈RN×N。这里,使用Taskonomy中的图来可视化矩阵 P P P:
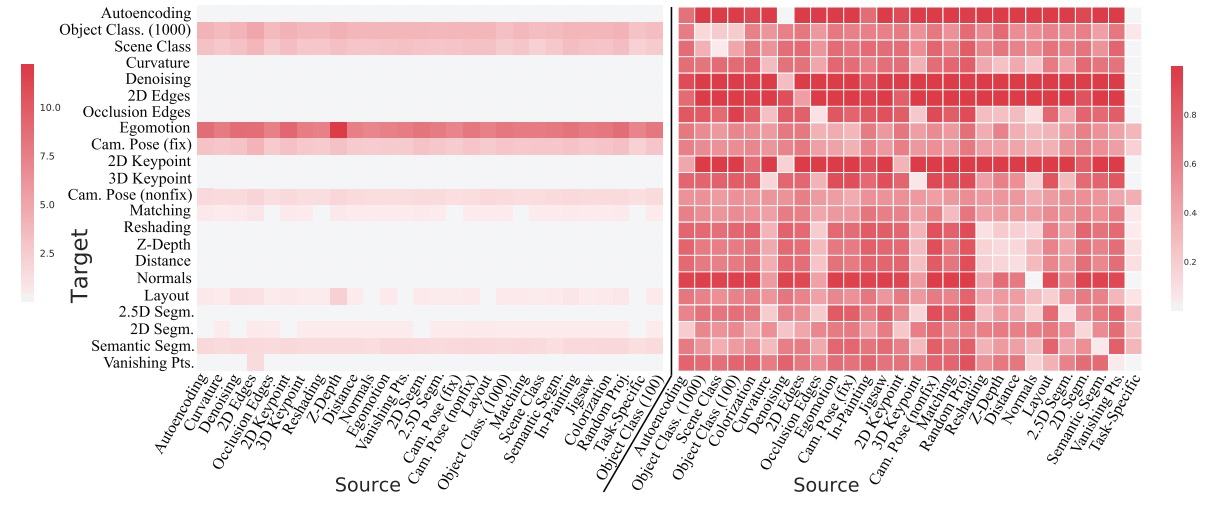
图2.Performance Matrix可视化。左边是没有使用AHP处理之前的结果,邮编是AHP处理之后的结果。
在BMTN中,作者提出一个运算 A = 1 2 ( P + P T ) A=\frac{1}{2}(P+P^T) A=21(P+PT),得到task affinity矩阵。将第三步运用在共享的encoder中的不同层上,可以度量一对任务在encoder某个深度上的关联性。最后,可以得到一个维度是 N × N × L N \times N \times L N×N×L的张量, N N N是任务数量, L L L是在共享的encoder上针对不同任务建立分支的位置。
Step 4:构建分支任务网络
这一步实际上是构建一个树形结构的过程。将encoder中第 l l l层表示为 f l ∈ E f_l \in E fl∈E,是树结构中一个节点, E E E表示整个encoder网络。若在第 l l l层建立分支,不同的分支实现不同的任务,则可以将分支个数表示为 b l b_l bl,也可以解释为节点 f l f_l fl有 b l b_l bl个子节点。针对某个具体任务的decoder( D t D_t Dt)可以在构建好的树中寻找一个节点的通路,也可以用树的叶子来表示。
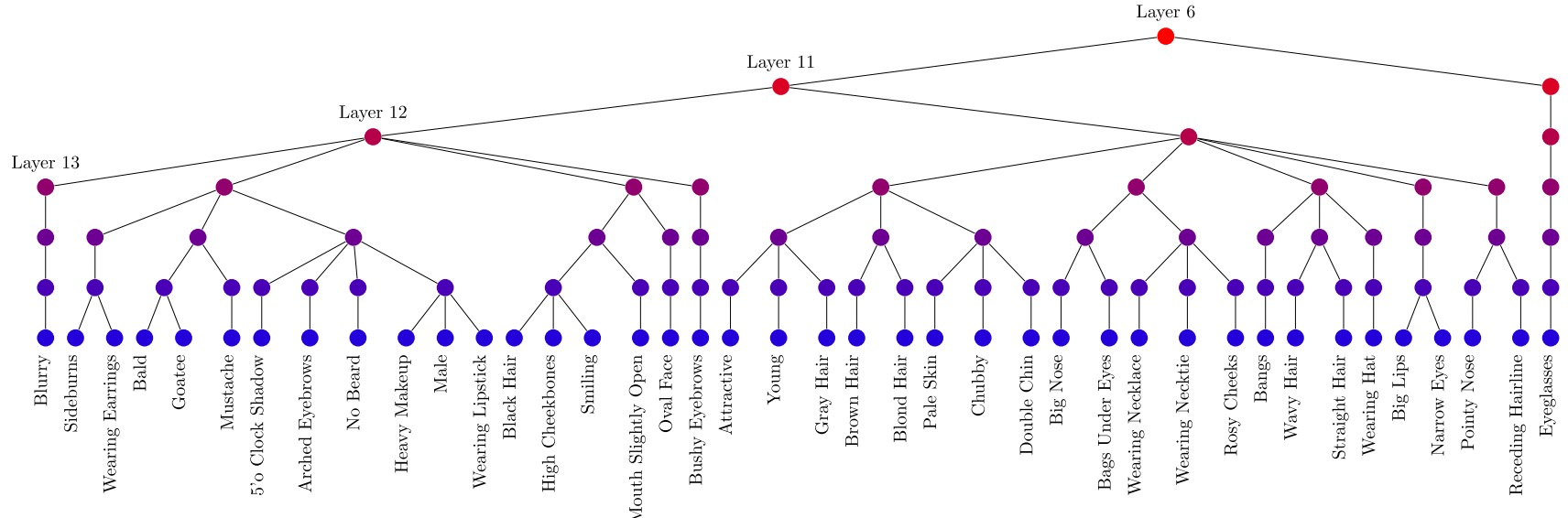
图3.BMTN构建的一个任务树。可以看到,在celebA人脸多属性识别中,相似任务(有关联的属性)共享encoder中更多地层,分支的位置更加靠后,如Goatee和Mustache。
下一个需要解决的问题是如何得到一棵最优的树。对于第 l l l层,将 l + 1 l+1 l+1层节点使用谱聚类的方式分组,使用每个组内部元素间的最大距离表示聚类损失 C c l u s t e r i n g l ( g ) C^l_{clustering}(g) Cclusteringl(g),这个损失值越小表示分组内部的任务相似度越大,分组之间的判别度越大,使用第三步中的task affinity分数来计算这里的距离。另外,作者希望得到一个复杂度最低的树结构,这个复杂度表示为:
C c o m p l e x i t y l ( g ) = ( b l − 1 ) ⋅ 2 p l C^l_{complexity}(g)=(b_l-1) \cdot 2^{p_l} Ccomplexityl(g)=(bl−1)⋅2pl
其中, b l b_l bl是第 l l l层的分支数量, p l p_l pl是 l l l层之前pooling层的数量。因此,分支数量越多网络越复杂,并且在pooling层后建立分支网络复杂度变高。将上面两个损失函数加权求和,将所有层的任务分组的损失求和,定义并最小化模型总的损失函数:
L = ∑ l C c l u s t e r i n g l ( g ) + α ⋅ C c o m p l e x i t y l ( g ) \mathcal{L}=\sum_l C^l_{clustering}(g) + \alpha \cdot C^l_{complexity}(g) L=∑lCclusteringl(g)+α⋅Ccomplexityl(g)
考虑到有的数据集中任务量较大,很难遍历所有所有树形,论文作者采用top-down方式逐层构建树。通过调节 α \alpha α,可以平衡网络复杂度与任务关联度之间的关系,较小的 α \alpha α可以得到复杂度较高的网络,最后的性能应该更好一些。
实验结果
在celebA人脸属性识别任务上,论文使用一个轻量版的VGG-16作为encoder,设置一个参数 ω \omega ω,取 ω \omega ω与VGG-16中每层特征通道数的小者作为该层特征个数。最后的全连接层参数设为 2 ω 2\omega 2ω,这样可以通过 ω \omega ω调节模型规模。
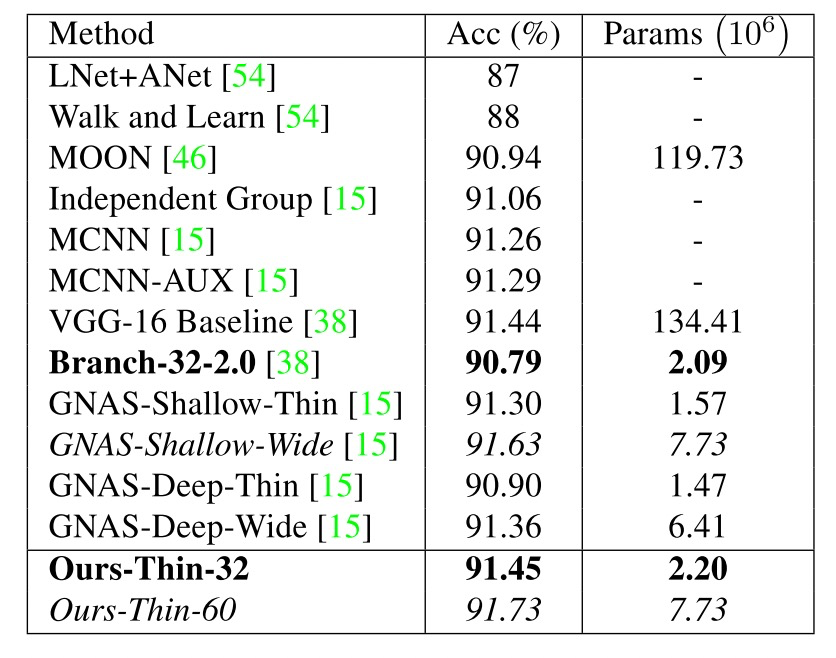
表1.在celeA上的性能对比。
从表中可以看出,论文提出的方法Thin-32只用了VGG-16参数量的1/64,就已达到了baseline的性能。通过加深网络,Thin-60在同等参数量的条件下, 超过了the-state-of-the-art方法性能。这里不再讨论其他数据集上的实验结果,感兴趣的读者可以仔细阅读原文。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









