







场景:Few-Shot Learning + Prompt Learning+PLM(BART)+Transfer Learning
Abstract
最近人们对研究少量的NER很感兴趣,其中低资源的目标域与资源丰富的源域有不同的标签集。现有的方法使用一种基于相似性的度量方法。然而,它们不能充分利用NER模型参数中的知识传递。为了解决这一问题,我们提出了一种基于模板的NER方法,将NER作为序列到序列框架中的语言模型排序问题,将由候选命名实体span填充的原始句子和语句模板分别视为源序列和目标序列。为了进行推理,模型需要根据相应的模板分数对每个候选跨度进行分类。
1 Introduction
命名实体识别(NER)是自然语言处理中的一项基本任务,根据预定义的实体类别识别文本输入,如位置、人、组织等。目前主要的方法使用顺序神经网络,如BiLSTM和bert来表示输入文本,使用softmax或CRF输出层来分配指定实体标签(例如组织、人和位置)或非实体标签在每个输入token上。如figure2(a)。
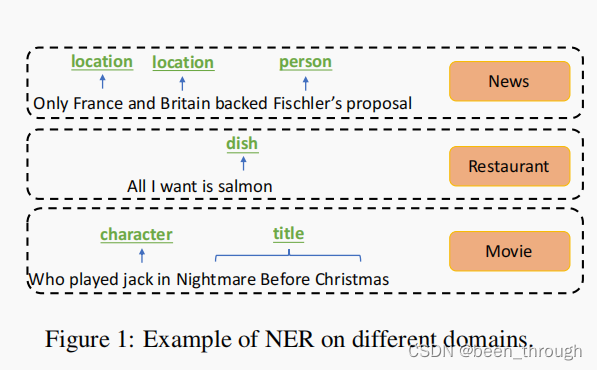
神经NER模型需要大量的标记训练数据,这些数据可以用于某些领域,如新闻,但在大多数其他领域很少有。理想情况下,最好从资源丰富的新闻领域转移知识,以便可以在基于一些标记实例的目标领域中使用模型。然而,在实践中,一个挑战是,实体类别在不同的领域中可能是不同的。如figure1所示,系统需要识别新闻域中的位置和人物,但识别电影域中的角色和标题。softmax层和CRF层都需要在训练和测试之间设置一致的标签集。因此,给定一个新的目标域,输出层需要进行调整,并且必须同时使用源域和目标域再次进行训练,这可能会很昂贵。
最近的一项工作通过使用距离度量研究了少镜头NER的设置。其主要思想是基于源域的实例训练相似度函数,然后利用目标域的相似度函数作为FSL-NER的最近邻准则。与传统方法相比,基于距离的方法大大降低了领域自适应的代价,特别是对于目标域数量较大的情况。然而,它们在标准的域内设置下的性能相对较弱。此外,它们的领域自适应能力也在两个方面受到限制。首先,利用目标域中的标记实例来寻找启发式最近邻搜索的最佳超参数设置,但不是用于更新NER模型的网络参数。虽然成本较低,但这些方法并不能改进跨域实例的神经表示。其次,这些方法依赖于源域和目标域之间类似的文本模式。当目标域的编写风格与源域不同时,这种强烈的假设可能会阻碍模型的性能。
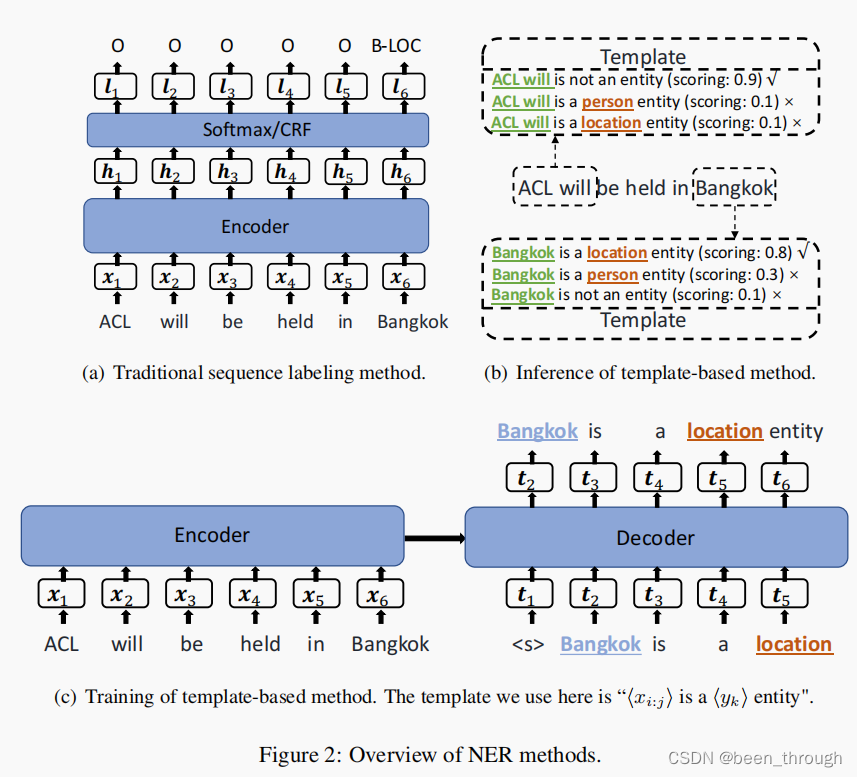
为了解决这些问题,我们研究了一种基于模板的方法,利用生成式预训练语言模型的少镜头学习潜力来进行序列标记。具体来说,如图2所示,BART使用由相应的标记实体填充的预定义模板进行了微调。例如,我们可以定义模板,如“<candidate_span> is a <entity_type entity>”, where <entity_type> can be “person” and “location”, etc.。考虑到句子“ACL will be held in Bangkok”,其中“ Bangkok”有一个gold label “location”,我们可以使用一个填充的模板“ “Bangkok is a location entity””来训练BART,作为输入句子的decoder输出。在非实体跨度方面,我们使用一个模板<cand
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









