






文章核心思想:combining PLMs with HTC.
挑战:
1、HTC的标签位于一个复杂的层次结构上,而MLM的预训练和平面提示调优不考虑标签层次结构。
2、HTC是一个多标签分类问题,其中输出标签与一个层次结构相连,而MLM预训练被表述为多类分类。
注:Multiclass classification 就是多分类问题,总共有多个类别,比如年龄预测中把人分为小孩,年轻人,青年人和老年人这四个类别。Multiclass classification 与 binary classification相对应,性别预测只有男、女两个值,就属于后者。
Multilabel classification 是多标签分类,一个样本有多个标签,比如一个新闻稿A可以与{政治,体育,自然}有关,就可以打上这三个标签。而新闻稿B可能只与其中的{体育,自然}相关,就只能打上这两个标签。
针对这两个gap的解决方法:
详细地说,为了连接层次结构和平面差距,我们将标签层次结构知识合并到具有连续表示的软提示中。此外,我们将标签层次结构中的深度和宽度信息合并到不同的虚拟模板词中,这有助于缓解我们的实验验证的标签不平衡问题。
为了弥合多标签和多类的差距,我们将HTC通过零有界多标签交叉熵损失将HTC转化为多标签交叉熵问题,不断增加正确标签的分数,减少错误标签的分数。
准备工作:
1、问题定义
层级结构式预定义的,节点集和边集,节点–>label, 边–>层级关系
一个可以简化问题的设置:每个节点都只有一个父节点。
目标数输出一个样本所属标签集。每个标签对应一条路径
2、Vanilla Fine Tuning for HTC
注:vanilla的中文是香草。在老美那边,貌似香草味就是咱们的原味。所以原味差不多就是原始版本的意思吧。
给定一个输入文本x,普通的微调方法首先将其转换为“[CLS]x[SEP]”作为模型输入,然后利用PLM对其进行编码。之后,它利用“[CLS]”的隐藏状态h[CLS]来预测输入文本的标签。先前基于PLM的方法(Chen等人,2021a;Wang等人,2022年)都遵循这种微调范式。
3、Prompt Tuning for HTC
hard soft
微调设置:
1)归一化用sigmoid 而不是原先的softmax
2)损失函数用二进制交叉熵
这样就可以训练了,但是还没涉及问题本质,也就是前边提到的两个gap
然后又解释了一下这两个gap
Hierarchy and flflat gap:软提示和硬提示都在预测之前不考虑标签,PLM认为所有候选词都是相同的。以往的研究表明,结合标签依赖性,而不是将其建模为平面分类,对于缓解标签的不平衡至关重要
. Multi-label and multi-class gap:以前在HTC上的工作将这个问题视为多重二值分类,但MLM是为多类分类而设计的。提示的目标是弥合预训练和微调之间的差距,但如果我们在微调过程中使用HTC使用sigmoid归一化和二进制交叉熵损失函数,差距仍然存在。
方法论:开始介绍具体方法 具体实现
4.1 Hierarchy-aware Prompt
Hierarchy Constraint和Hierarchy Injection
4.1.1 Hierarchy Constraint
分层提示,基于层次结构的深度构建模板
需要预定义的层级结构以及层次深度
动态模板词,模板词的个数等于层数,
用了一个特殊的token[PRED]表示预测的标签
1、用bert做text encoder
输出:T = [x1, . . . , xN , t1, eP , . . . , tL, eP ]
x1-xN是word embedding,
eP 是 [PRED]的embedding,被初始化为 bert的[MASK] token
{ti}Li=1 是根据层次动态变化的模板。和软提示一样,这个模板随机初始化,然后再训练中学习。
省略了 tokens of BERT ([CLS] and [SEP])
每个模板词后都跟了一个[pred],最后根据[PRED]位置的向量来预测embedding
2、把T送入bert编码得到隐藏状态
输入:
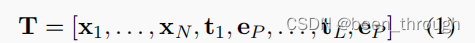
输出的长度没有变,ep有L个
输出:
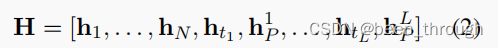
hp是ep对应的隐藏状态,模板词和[pred]是成对的
3、verbalizer,模板再映射回label
为每个label yi创建了一个可学习的虚拟词vi,初始化为label词向量的均值(label可能有多个词)
通过将预测分解为不同的插槽,模型可以更好地了解不同层间标签之间的依赖关系,并在一定程度上解决了标签的不平衡问题。
定义的verbalizer
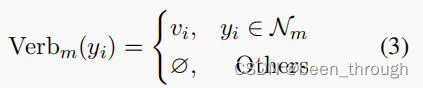
where Nm is the label set of the m-th layer and ∅ denotes that there is no label words for labels at
other layers.
yi是label,vi是虚拟模板词
将m层的label word映射程vi,其他层的映射为空,后边再看怎么定义的这个空,零向量?
4.1.2 Hierarchy Injection
Hierarchy Constraint只引入了标签的深度,但缺乏它们的连通性。为了以MLM的方式充分利用标签层次结构,我们进一步将每层标签层次结构知识注入到模板嵌入中。
使用GAT建模标签之间的层级关系。u是节点,k指节点所在层次。
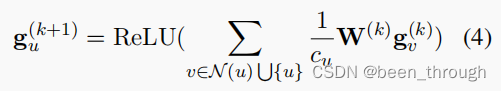
v属于u和u相邻节点组成的集合,也就是说,每个节点的信息由它本身的信息和它相邻节点的信息综合决定,cu是归一化常数,W是要训练的超参数。
为了实现分层提示,创建L个虚拟节点(L是层级树的层数),虚拟节点vi与第i层的所有label node对应。
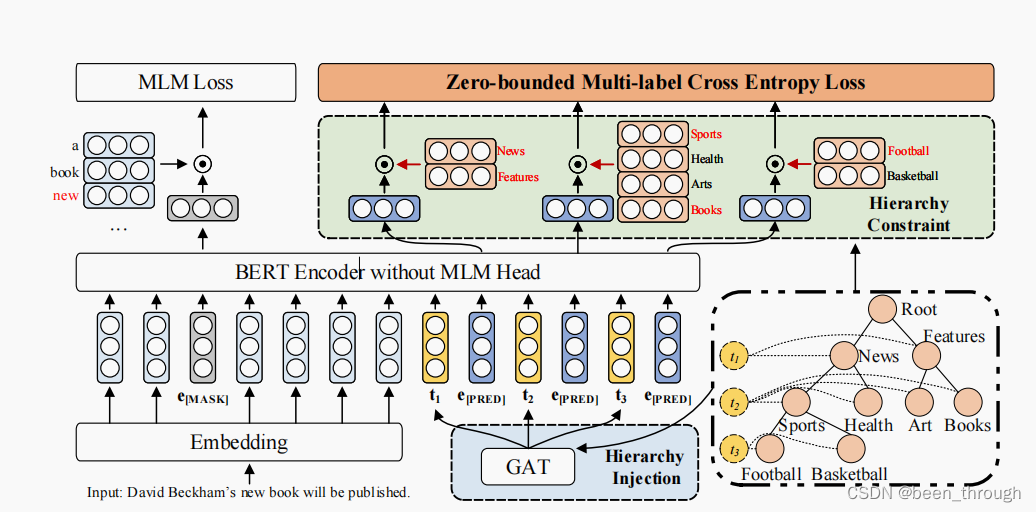
最初的GAT层中用虚拟label word表示树中的每一个节点,用模板向量当作这一层的虚拟节点。
解释:在GAT中有一个label node组成的树,和一个和一整层节点关联起来的虚拟节点。
label node用这个node对应的虚拟label word表示,虚拟节点和每一层对应的模板向量对应。
模板向量 template embedding在这提到的:

然后将GAT中的信息,根据下边这个公式生成虚拟节点vi的表示,这样虚拟节点的表示就包含了这一层所有节点的信息(has gathered knowledge from the i-th layer.)
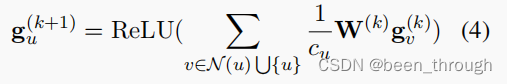
然后用残差连接
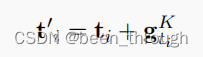
生成最终的虚拟节点的表示,这就是最终要用的template embedding,也就是送入bert的序列中的ti(如下图)

4.2 Zero-bounded Multi-label Cross EntropyLoss
BCEloss忽略了标签之间的关联,
CE强制黄金标签的得分大于所有其他标签,这直接模拟了标签的相关性。为了协调他们的目标,弥合这种多标签和多类的差距,我们期望所有目标标签的分数都大于所有非目标标签的分数,而不是单独计算每个标签的分数。因此,我们构造了一个多标签的交叉熵MLCE
MLCE损失的设计目的是在确定性条件下分离正(目标)标签和负(其他)标签,但是在HTC中,我们不能知道之前的目标标签的数量,这使得MLCE在我们的场景中不明确适用。为此,我们在MLCE中引入了一个得分不变为0的锚定标签,希望目标标签和非目标标签的得分都分别大于和小于0。因此,我们形成了一个零有界的多标签交叉熵(ZMLCE)损失。
我们保留原始的MLM损失作为BERT预训练,最终的损失Lall是不同层的ZMLCE损失和MLM损失的总和。
附一个补充知识损失函数到底该不该加sigmoid softmax:
BCE的activation layer是sigmoid,如果模型最后一层有sigmoid,就用nn.BCELoss();如果没有sigmoid,就用nn.BCEWithLogitsLoss(),因为这个损失函数自带sigmoid。
Pytorch的模型一般都不带sigmoid作为最后一层,一般来讲用BCEWithLogitsLoss要多一些。
CE的activation layer是softmax,如果模型最后一层带softmax, 用nn.NLLLoss(),如果模型最后一层没有,那就用nn.CrossEntropyLoss(),它自带softmax,这也是pytorch模型中常见的。
一个总结:
核心就是每层一个模板词,然后用各种方法生成一个模板词。
每个模板词后跟一个[pred],这就是预测的标签vi,再根据vi映射回label word。
我看这篇论文是为了看损失函数ZMLCE,其实就是把让正标签>0,负标签<0,这样就不用设threshhold了,最近的确被这个阈值搞得很烦。
实验部分待续,也可能不续。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









