







 博客探讨了LeetCode中的最大子数组和问题,通过四种不同的方法进行了解决:动态规划(超时)、优化后的动态规划、递归以及分治法。动态规划法中提到降低时间复杂度的重要性,而分治法虽然时间复杂度与动态规划相同,但空间效率较低。文章还介绍了分治法的适用条件和关键步骤,并提供了详细的代码实现。
博客探讨了LeetCode中的最大子数组和问题,通过四种不同的方法进行了解决:动态规划(超时)、优化后的动态规划、递归以及分治法。动态规划法中提到降低时间复杂度的重要性,而分治法虽然时间复杂度与动态规划相同,但空间效率较低。文章还介绍了分治法的适用条件和关键步骤,并提供了详细的代码实现。
问题描述
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [0]
输出:0
示例 4:
输入:nums = [-1]
输出:-1
示例 5:
输入:nums = [-100000]
输出:-100000
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104
进阶:如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-subarray
法I:我写的动态规划(竟然超时了)
//用动态规划,竟然超时了。。。
const int MIN = -10000;
class Solution {
public:
int maxSubArray(vector<int> &nums) {
vector<vector<int>> memo;//备忘录存储
for (int i = 0; i < nums.size(); i++) {
vector<int> tmp;
for (int j = 0; j < nums.size(); j++) {
tmp.push_back(MIN);
}
memo.push_back(tmp);
}
int max = MIN;
for (int i = 0; i < nums.size(); i++) {
memo[i][i] = nums[i];
max = max > nums[i] ? max : nums[i];
for (int j = i + 1; j < nums.size(); j++) {
memo[i][j] = memo[i][j - 1] + nums[j];
max = max > memo[i][j] ? max : memo[i][j];
}
}
return max;
}
};

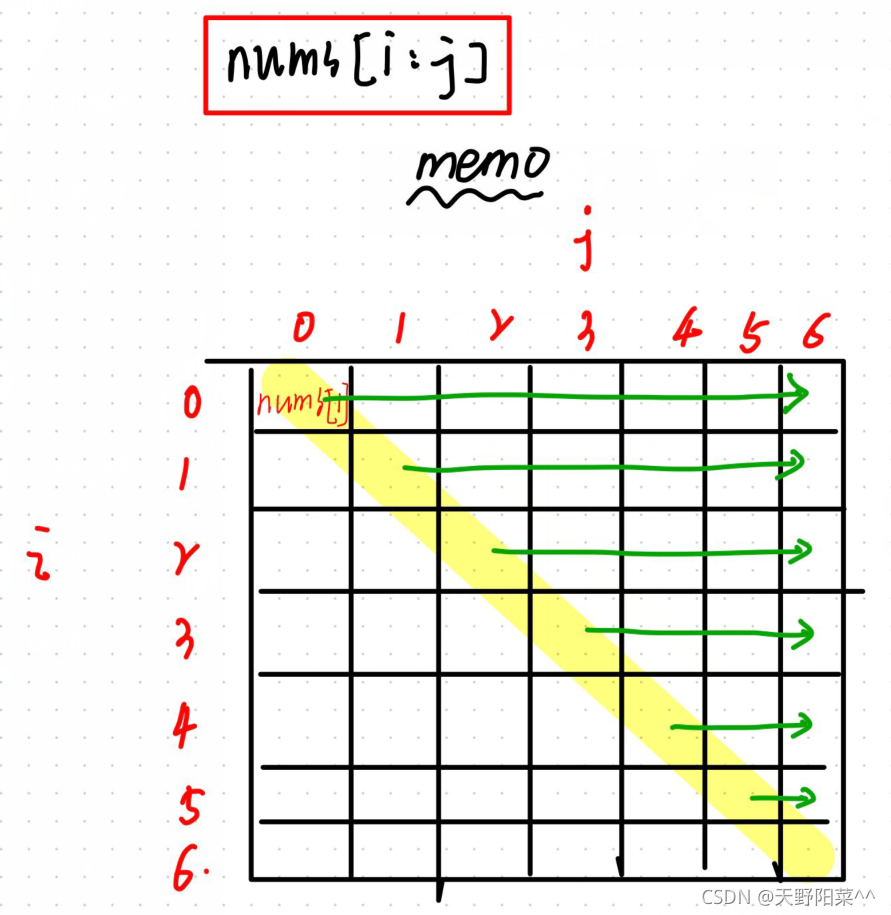
用一张图来解释我的思路吧,很好理解:
法II:标答的动态规划(果然牛逼)
看了标答才发现自己实在是太菜鸡了。。我写的memo是二维的,时间复杂度就到了O(n^2)。而标答的memo是一维的。。所以不要以为写出动态规划来就完事了,真的还是有可能超时的,想想能不能给memo降维吧先!
那我们就来看看标答是怎么实现一维的memo的:
我们首先来看一个时间复杂度和空间复杂度都是O(n)的算法:
我们用备忘录memo[i]来代表在nums[i]中以索引i为结尾的连续最长子段和,则求解最大的memo[i]即可。给出递推关系:memo[i] = max(memo[i-1]+nums[i], nums[i]);
其实,对于一维memo[i]求最值,我们每次大问题只需要用到仅仅在它前面的一个子问题的解,此时我们可以不用数组memo来记录所有子问题解,仅仅用一个变量pre来记录这个问题的前面子问题的解即可,同时用变量maxAns来记录当前的最大值,此时空间复杂度就降到了O(1)。
下面直接给出代码:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int pre = 0, maxAns = nums[0];
for (const auto &x: nums) {
pre = max(pre + x, x);
maxAns = max(maxAns, pre);
}
return maxAns;
}
};
我直呼,太简单了是不是!
但是我们看一下执行结果:
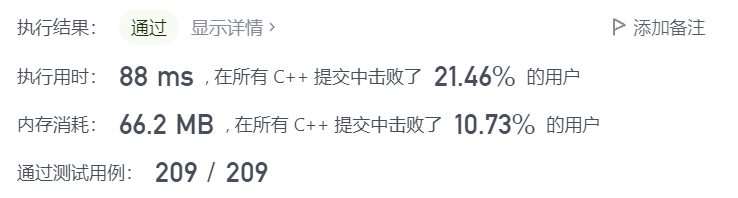
好像并不是辣么优秀诶!
法III:递归——依旧是我写的
我们知道递归的两要素:边界条件与递归方程。下面我们给出该题的这两要素:
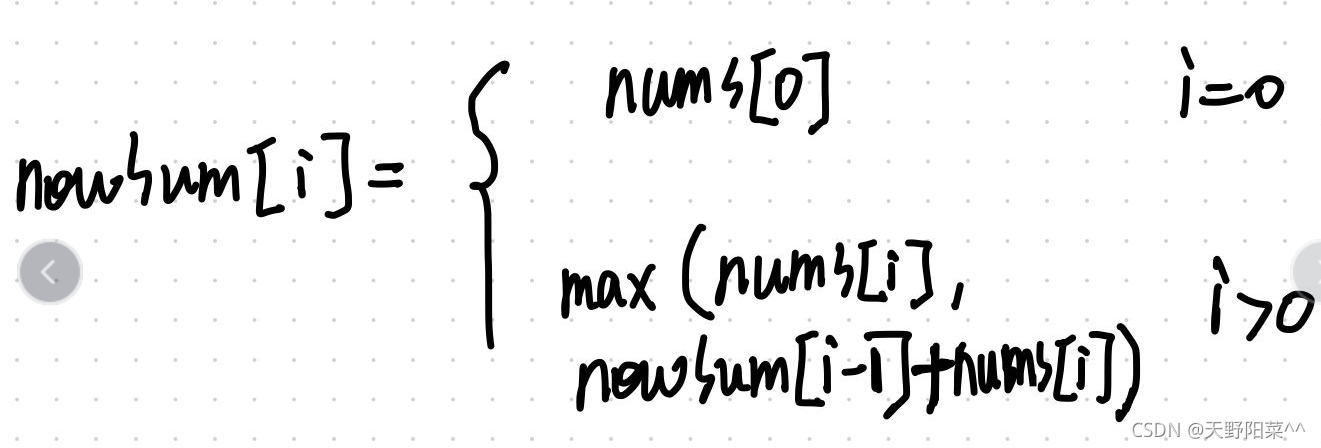
因此我们就可以写代码了:
//分治与递归
class Solution {
public:
int maxSubArray(vector<int> &nums) {
vector<int> sums = getMaxSum(nums.size() - 1, nums);
return sums[1];
}
vector<int> getMaxSum(int t, vector<int> &nums) {
if (t == 0) {
return { nums[0], nums[0] };
}
else {
vector<int> sums = getMaxSum(t - 1, nums);
int nowSum = max(nums[t], nums[t] + sums[0]);
int maxSum = max(nowSum, sums[1]);
return { nowSum,maxSum };
}
}
};

法IV:分治法
其实又看了一遍才知道了分治和递归并不是划等号的。。下面先大概说一下啥是分治:
什么是分治
算法的总体思想:将求出的小规模的问题的解合并为一个更大规模的问题的解,自底向上逐步求出原来问题的解。
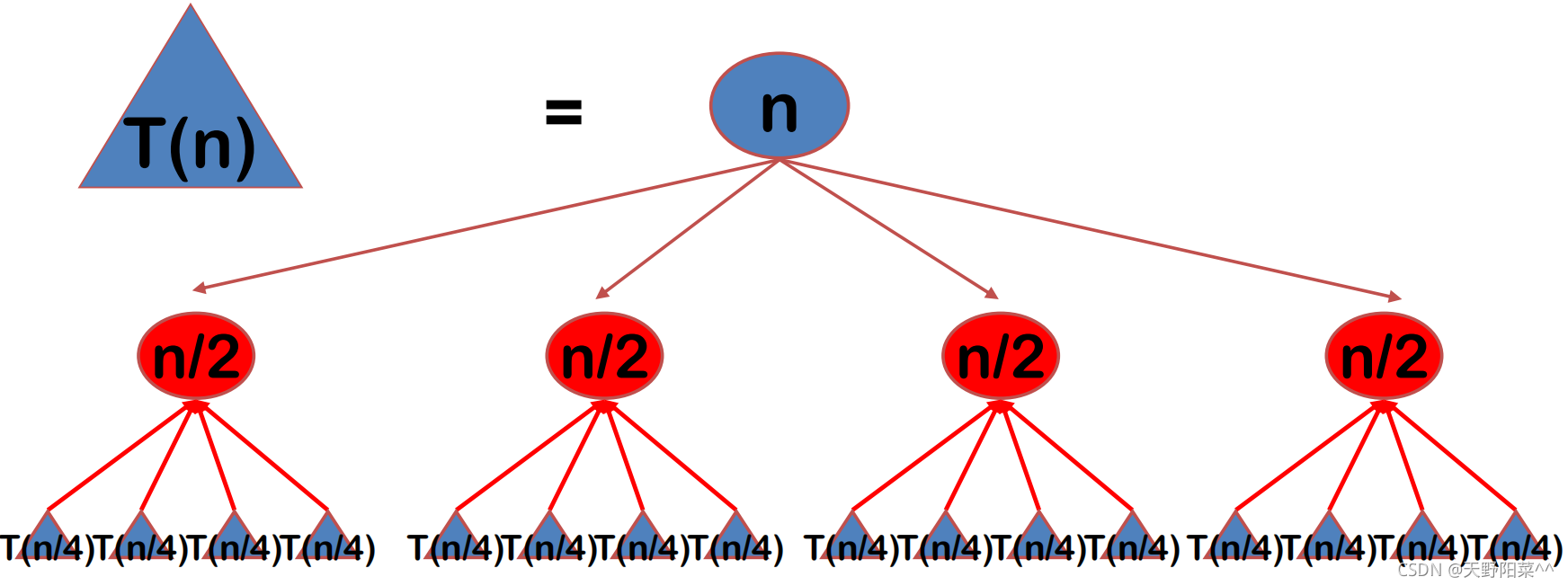
算法的基本步骤:

分割原则:人们从大量实践中发现,在用分治法设计算法时,最好使子问题的规模大致相同。即将一个问题分成大小相等的k个子问题的处理方法是行之有效的。这种使子问题规模大致相等的做法是出自一种平衡(balancing)子问题的思想,它几乎总是比子问题规模不等的做法要好。
分治法的适用条件:

该题的分治求解方法
这个分治方法类似于「线段树求解最长公共上升子序列问题」的 pushUp 操作。 也许读者还没有接触过线段树,没有关系,方法二的内容假设你没有任何线段树的基础。当然,如果读者有兴趣的话,推荐阅读线段树区间合并法解决多次询问的「区间最长连续上升序列问题」和「区间最大子段和问题」,还是非常有趣的。
我们定义一个操作 get(a, l, r) 表示查询 a 序列 [l,r]区间内的最大子段和,那么最终我们要求的答案就是 get(nums, 0, nums.size() - 1)。如何分治实现这个操作呢?对于一个区间 [l,r],我们取 m =(l+r)/2,对区间 [l,m]和 [m+1,r]分治求解。当递归逐层深入直到区间长度缩小为1的时候,递归「开始回升」。这个时候我们考虑如何通过 [l,m]区间的信息和 [m+1,r]区间的信息合并成区间 [l,r]的信息。最关键的两个问题是:
- 我们要维护区间的哪些信息呢?
- 我们如何合并这些信息呢?
对于一个区间 [l,r],我们可以维护四个量:
lSum:表示[l,r]内以l为左端点的最大子段和rSum:表示[l,r]内以r为右端点的最大子段和mSum:表示[l,r]内的最大子段和iSum:表示[l,r]的区间和
以下简称 [l,m]为 [l,r]的「左子区间」,[m+1,r]为 [l,r]的「右子区间」。我们考虑如何维护这些量呢(如何通过左右子区间的信息合并得到 [l,r]的信息)?对于长度为1的区间 [i, i],四个量的值都和 nums[i] 相等。对于长度大于1的区间:
首先最好维护的是iSum,区间 [l,r]的iSum 就等于「左子区间」的 iSum 加上「右子区间」的iSum。
对于 [l,r]的lSum,存在两种可能,它要么等于「左子区间」的 lSum,要么等于「左子区间」的iSum 加上「右子区间」的lSum,二者取大。
对于 [l,r]的rSum,同理,它要么等于「右子区间」的rSum,要么等于「右子区间」的iSum 加上「左子区间」的rSum,二者取大。
当计算好上面的三个量之后,就很好计算 [l,r]的mSum 了。我们可以考虑 [l,r] 的 mSum 对应的区间是否跨越m——它可能不跨越m,也就是说[l,r]的 mSum 可能是「左子区间」的mSum 和 「右子区间」的mSum 中的一个;它也可能跨越 m,可能是「左子区间」的rSum 和 「右子区间」的lSum 求和。三者取大。
这样问题就得到了解决。
下面列一下代码吧:
class Solution {
public:
struct Status {
int lSum, rSum, mSum, iSum;
};
Status pushUp(Status l, Status r) {//merge
int iSum = l.iSum + r.iSum;
int lSum = max(l.lSum, l.iSum + r.lSum);
int rSum = max(r.rSum, r.iSum + l.rSum);
int mSum = max(max(l.mSum, r.mSum), l.rSum + r.lSum);
return (Status) {lSum, rSum, mSum, iSum};
};
Status get(vector<int> &a, int l, int r) {
if (l == r) {
return (Status) {a[l], a[l], a[l], a[l]};
}
//拆分
int m = (l + r) >> 1;
Status lSub = get(a, l, m);
Status rSub = get(a, m + 1, r);
//合并
return pushUp(lSub, rSub);
}
int maxSubArray(vector<int>& nums) {
return get(nums, 0, nums.size() - 1).mSum;
}
};
分治法相较于动态规划来说,时间复杂度相同,但是因为使用了递归,并且维护了四个信息的结构体,运行的时间略长,空间复杂度也不如动态规划法优秀,而且难以理解。那么这种方法存在的意义是什么呢?
对于这道题而言,确实是如此的。但是仔细观察该方法,它不仅可以解决区间[0, n-1],还可以用于解决任意的子区间[l,r]的问题。如果我们把[0, n-1]分治下去出现的所有子区间的信息都用堆式存储的方式记忆化下来,即建成一颗真正的树之后,我们就可以在O(logn)的时间内求到任意区间内的答案,我们甚至可以修改序列中的值,做一些简单的维护,之后仍然可以在O(logn)的时间内求到任意区间内的答案,对于大规模查询的情况下,这种方法的优势便体现了出来。这棵树就是上文提及的一种神奇的数据结构——线段树。

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









