




逆向加密算法
url编码
import urllib.parse
# URL编码
urllib.parse.quote(str)
# URL解码
urllib.parse.unquote(str)
# 将字典或元组序列转换为URL查询字符串
urllib.parse.urlencode(字典/元组)
# 将URL查询字符串解析为字典
urllib.parse.parse_qs(str)
base64编码
base64是什么
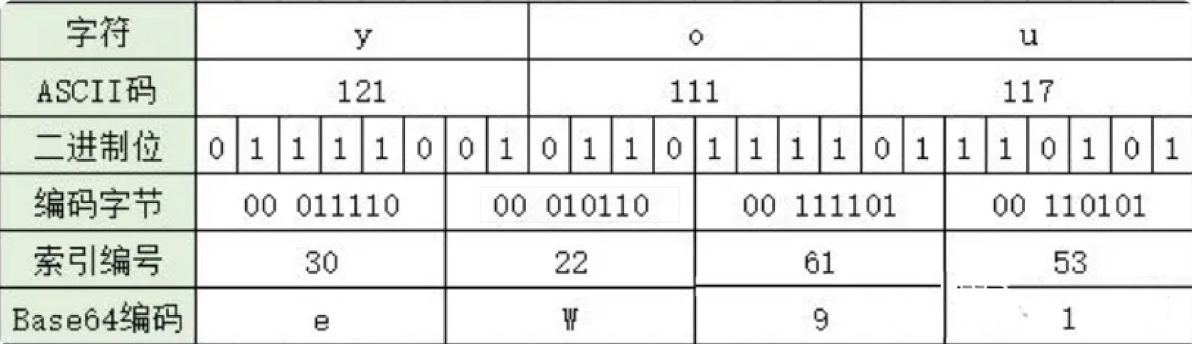
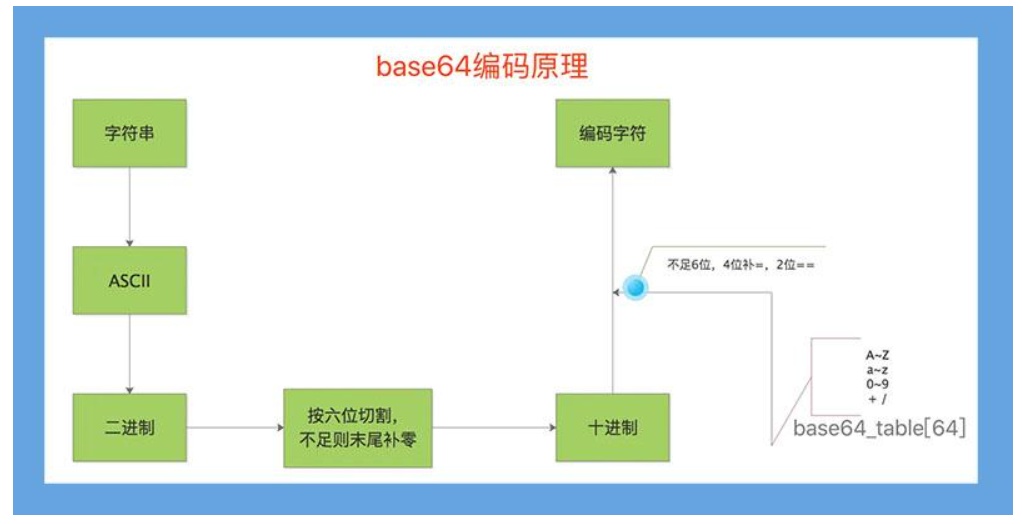
Base64编码,是由64个字符组成编码集:26个大写字母A-Z,26个小写字母a-z,10个数字0-9,符号“+”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后根据Base64的对应表,得到对应的编码数据。
当原始数据凑不够三个字节时,编码结果中会使用额外的 符号= 来表示这种情况。
base64原理
3个字符为一组的的base64编码方式
import base64
# 将字符串you转换成utf-8字节
bs = "you".encode("utf-8")
# 把字节转化成b64
base64.b64encode(bs).decode()
注意:b64处理后的字符串长度. 一定是4的倍数. 如果在网页上看到有些密文的b64长度不是4的倍数. 会报错
import base64
s = "eW91eQ"
s += ("=" * (4 - len(s) % 4))
print("填充后", s)
ret = base64.b64decode(s).decode()
print(ret)
base64变种
# 方式1
data = res.text.replace("-", "+").replace("_", "/")
base64.b64decode(data)
# 方式2
data = base64.b64decode(res.text, altchars=b"-_") # base64解码成字节流
base64优点
- 算法是编码,不是压缩,编码后只会增加字节数(一般是比之前的多1/3,比如之前是3, 编码后是4)
- 算法简单,基本不影响效率
- 算法可逆,解码很方便,不用于私密传输。
- 加密后的字符串只有【0-9a-zA-Z+/=】 ,不可打印字符(转译字符)也可以传输
用Base64编码因为限定了用于编码的字符集,确保编码的结果可打印且无歧义
JS的base64编码与解码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









