







rknn模型在开发板上的验证与部署
1 rknn模型的python验证
1.1 rk环境安装
cd project-Toolkit2.1/rknn-toolkit2-2.1.0/rknn-toolkit-lite2/packages/
pip install rknn_toolkit_lite2-2.1.0-cp38-cp38-linux_aarch64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
1.2 python验证
cd convert_rknn2.1/rknn_model_zoo-2.1.0/examples/yolov8_pose/python/
python yolov8_pose_demo.py
1.2.1 自己尝试的方式
我看连着板子操作比较麻烦,我也没有可以直连的机器,我就尝试直接在板子上跑,没想到也可以,现在将代码分享一下,有需要的可以参考。
import os
import sys
import urllib
import urllib.request
import time
import numpy as np
import argparse
import cv2,math
from math import ceil
#from rknn.api import RKNN
from rknnlite.api import RKNNLite
CLASSES = ['person']
INPUT_IMG_FULL_PATH = "./ws_ultra/thanks.jpg"
LOAD_MDL_PATH = "./ws_ultra/yolov8s_pose_ultra.rknn"
SAVE_IMG_PATH = "./result.jpg"
nmsThresh = 0.4
objectThresh = 0.5
def letterbox_resize(image, size, bg_color):
"""
letterbox_resize the image according to the specified size
:param image: input image, which can be a NumPy array or file path
:param size: target size (width, height)
:param bg_color: background filling data
:return: processed image
"""
if isinstance(image, str):
image = cv2.imread(image)
target_width, target_height = size
image_height, image_width, _ = image.shape
# Calculate the adjusted image size
aspect_ratio = min(target_width / image_width, target_height / image_height)
new_width = int(image_width * aspect_ratio)
new_height = int(image_height * aspect_ratio)
# Use cv2.resize() for proportional scaling
image = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_AREA)
# Create a new canvas and fill it
result_image = np.ones((target_height, target_width, 3), dtype=np.uint8) * bg_color
offset_x = (target_width - new_width) // 2
offset_y = (target_height - new_height) // 2
result_image[offset_y:offset_y + new_height, offset_x:offset_x + new_width] = image
return result_image, aspect_ratio, offset_x, offset_y
class DetectBox:
def __init__(self, classId, score, xmin, ymin, xmax, ymax, keypoint):
self.classId = classId
self.score = score
self.xmin = xmin
self.ymin = ymin
self.xmax = xmax
self.ymax = ymax
self.keypoint = keypoint
def IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2):
xmin = max(xmin1, xmin2)
ymin = max(ymin1, ymin2)
xmax = min(xmax1, xmax2)
ymax = min(ymax1, ymax2)
innerWidth = xmax - xmin
innerHeight = ymax - ymin
innerWidth = innerWidth if innerWidth > 0 else 0
innerHeight = innerHeight if innerHeight > 0 else 0
innerArea = innerWidth * innerHeight
area1 = (xmax1 - xmin1) * (ymax1 - ymin1)
area2 = (xmax2 - xmin2) * (ymax2 - ymin2)
total = area1 + area2 - innerArea
return innerArea / total
def NMS(detectResult):
predBoxs = []
sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True)
for i in range(len(sort_detectboxs)):
xmin1 = sort_detectboxs[i].xmin
ymin1 = sort_detectboxs[i].ymin
xmax1 = sort_detectboxs[i].xmax
ymax1 = sort_detectboxs[i].ymax
classId = sort_detectboxs[i].classId
if sort_detectboxs[i].classId != -1:
predBoxs.append(sort_detectboxs[i])
for j in range(i + 1, len(sort_detectboxs), 1):
if classId == sort_detectboxs[j].classId:
xmin2 = sort_detectboxs[j].xmin
ymin2 = sort_detectboxs[j].ymin
xmax2 = sort_detectboxs[j].xmax
ymax2 = sort_detectboxs[j].ymax
iou = IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2)
if iou > nmsThresh:
sort_detectboxs[j].classId = -1
return predBoxs
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x, axis=-1):
exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
def process(out,keypoints,index,model_w,model_h,stride,scale_w=1,scale_h=1):
xywh=out[:,:64,:]
conf=sigmoid(out[:,64:,:])
out=[]
for h in range(model_h):
for w in range(model_w):
for c in range(len(CLASSES)):
if conf[0,c,(h*model_w)+w]>objectThresh:
xywh_=xywh[0,:,(h*model_w)+w] #[1,64,1]
xywh_=xywh_.reshape(1,4,16,1)
data=np.array([i for i in range(16)]).reshape(1,1,16,1)
xywh_=softmax(xywh_,2)
xywh_ = np.multiply(data, xywh_)
xywh_ = np.sum(xywh_, axis=2, keepdims=True).reshape(-1)
xywh_temp=xywh_.copy()
xywh_temp[0]=(w+0.5)-xywh_[0]
xywh_temp[1]=(h+0.5)-xywh_[1]
xywh_temp[2]=(w+0.5)+xywh_[2]
xywh_temp[3]=(h+0.5)+xywh_[3]
xywh_[0]=((xywh_temp[0]+xywh_temp[2])/2)
xywh_[1]=((xywh_temp[1]+xywh_temp[3])/2)
xywh_[2]=(xywh_temp[2]-xywh_temp[0])
xywh_[3]=(xywh_temp[3]-xywh_temp[1])
xywh_=xywh_*stride
xmin=(xywh_[0] - xywh_[2] / 2) * scale_w
ymin = (xywh_[1] - xywh_[3] / 2) * scale_h
xmax = (xywh_[0] + xywh_[2] / 2) * scale_w
ymax = (xywh_[1] + xywh_[3] / 2) * scale_h
keypoint=keypoints[...,(h*model_w)+w+index]
keypoint[...,0:2]=keypoint[...,0:2]//1
box = DetectBox(c,conf[0,c,(h*model_w)+w], xmin, ymin, xmax, ymax,keypoint)
out.append(box)
return out
pose_palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102], [230, 230, 0], [255, 153, 255],
[153, 204, 255], [255, 102, 255], [255, 51, 255], [102, 178, 255], [51, 153, 255],
[255, 153, 153], [255, 102, 102], [255, 51, 51], [153, 255, 153], [102, 255, 102],
[51, 255, 51], [0, 255, 0], [0, 0, 255], [255, 0, 0], [255, 255, 255]],dtype=np.uint8)
kpt_color = pose_palette[[16, 16, 16, 16, 16, 0, 0, 0, 0, 0, 0, 9, 9, 9, 9, 9, 9]]
skeleton = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8],
[7, 9], [8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]
limb_color = pose_palette[[9, 9, 9, 9, 7, 7, 7, 0, 0, 0, 0, 0, 16, 16, 16, 16, 16, 16, 16]]
def rknn_infer():
parser = argparse.ArgumentParser(description='Yolov8 Pose Python Demo', add_help=True)
# basic params
parser.add_argument('--model_path', type=str, required=True,
help='model path, could be .rknn file')
parser.add_argument('--target', type=str,
default='rk3588', help='target RKNPU platform')
parser.add_argument('--device_id', type=str,
default=None, help='device id')
args = parser.parse_args()
# Create RKNN object
rknn = RKNN(verbose=True)
# Load RKNN model
ret = rknn.load_rknn(args.model_path)
if ret != 0:
#print('Load RKNN model \"{}\" failed!'.format(args.model_path))
exit(ret)
#print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(target=args.target)
if ret != 0:
#print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread('../model/bus.jpg')
letterbox_img, aspect_ratio, offset_x, offset_y = letterbox_resize(img, (640,640), 56) # letterbox缩放
infer_img = letterbox_img[..., ::-1] # BGR2RGB
# Inference
#print('--> Running model')
results = rknn.inference(inputs=[infer_img])
def rknn_lite_infer(infer_img):
print('--> load model')
# Create RKNN object
rknn = RKNNLite()
# Load RKNN model
ret = rknn.load_rknn(LOAD_MDL_PATH)
if ret != 0:
print('Load RKNN model \"{}\" failed!'.format(LOAD_MDL_PATH))
exit(ret)
print(f'done mdl_path: {LOAD_MDL_PATH}\n')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done\n')
# Inference
print('--> Running model')
results = rknn.inference(inputs=[infer_img])
print('done\n')
# Release
rknn.release()
return results
def preprocess():
print('--> read img')
img = cv2.imread(INPUT_IMG_FULL_PATH)
print(f"done img_path: {INPUT_IMG_FULL_PATH}\n")
letterbox_img, aspect_ratio, offset_x, offset_y = letterbox_resize(img, (640,640), 56)
infer_img = letterbox_img[..., ::-1] # BGR2RGB
#infer_img = np.transpose(infer_img, (2, 0, 1)) # 将 HWC 转为 CHW
infer_img = np.expand_dims(infer_img, axis=0) # 增加 batch 维度
infer_img = infer_img.astype(np.float32)
return infer_img, img, aspect_ratio, offset_x, offset_y
def postprocess(results, img, aspect_ratio, offset_x, offset_y):
print('--> postprocess')
outputs=[]
keypoints=results[3]
for x in results[:3]:
index,stride=0,0
if x.shape[2]==20:
stride=32
index=20*4*20*4+20*2*20*2
if x.shape[2]==40:
stride=16
index=20*4*20*4
if x.shape[2]==80:
stride=8
index=0
feature=x.reshape(1,65,-1)
output=process(feature,keypoints,index,x.shape[3],x.shape[2],stride)
outputs=outputs+output
predbox = NMS(outputs)
for i in range(len(predbox)):
xmin = int((predbox[i].xmin-offset_x)/aspect_ratio)
ymin = int((predbox[i].ymin-offset_y)/aspect_ratio)
xmax = int((predbox[i].xmax-offset_x)/aspect_ratio)
ymax = int((predbox[i].ymax-offset_y)/aspect_ratio)
classId = predbox[i].classId
score = predbox[i].score
w = abs(xmax - xmin)
h = abs(ymax - ymin)
print(f"{CLASSES[classId]} @ ({xmin}, {ymin}, {w}, {h}) {score:.2f}")
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
ptext = (xmin, ymin)
title= CLASSES[classId] + "%.2f" % score
cv2.putText(img, title, ptext, cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2, cv2.LINE_AA)
keypoints =predbox[i].keypoint.reshape(-1, 3) #keypoint [x, y, conf]
keypoints[...,0]=(keypoints[...,0]-offset_x)/aspect_ratio
keypoints[...,1]=(keypoints[...,1]-offset_y)/aspect_ratio
for k, keypoint in enumerate(keypoints):
x, y, conf = keypoint
print(f"kpt: ({x}, {y}, {conf:.2f})")
color_k = [int(x) for x in kpt_color[k]]
if x != 0 and y != 0:
cv2.circle(img, (int(x), int(y)), 5, color_k, -1, lineType=cv2.LINE_AA)
for k, sk in enumerate(skeleton):
pos1 = (int(keypoints[(sk[0] - 1), 0]), int(keypoints[(sk[0] - 1), 1]))
pos2 = (int(keypoints[(sk[1] - 1), 0]), int(keypoints[(sk[1] - 1), 1]))
conf1 = keypoints[(sk[0] - 1), 2]
conf2 = keypoints[(sk[1] - 1), 2]
if pos1[0] == 0 or pos1[1] == 0 or pos2[0] == 0 or pos2[1] == 0:
continue
cv2.line(img, pos1, pos2, [int(x) for x in limb_color[k]], thickness=2, lineType=cv2.LINE_AA)
cv2.imwrite(SAVE_IMG_PATH, img)
print(f"done save_image_path: {SAVE_IMG_PATH}")
if __name__ == '__main__':
img, img0, aspect_ratio, offset_x, offset_y = preprocess()
results = rknn_lite_infer(img)
postprocess(results, img0, aspect_ratio, offset_x, offset_y)
【遇到问题1】
运行yolov8_pose_demo.py脚本,出现如下图所示的奇葩结果。
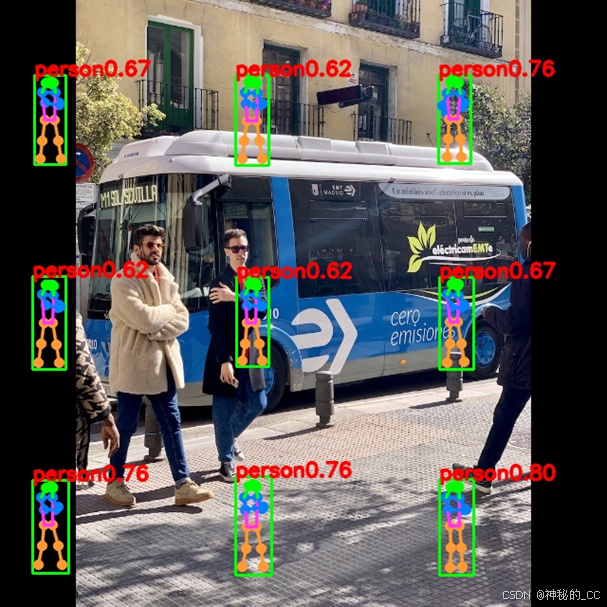
【解决方案1】
最后经别人提示,发现是通道问题,rk的通道顺序是HWC。注释代码中的这句话即可。
#infer_img = np.transpose(infer_img, (2, 0, 1)) # 将 HWC 转为 CHW

【遇到问题2】
from rknn.api import RKNN
报错没有RKNN。
【解决方案2】
在板子上,没有RKNN,应该为RKNNLite,将
from rknn.api import RKNN修改为from rknnlite.api import RKNNLite as RKNN即可。
1.2.2 官方推荐方式
连板调试,文档地址: https://github.com/airockchip/rknn-toolkit2/blob/master/doc/01_Rockchip_RKNPU_Quick_Start_RKNN_SDK_V2.2.0_CN.pdf。
在线阅读可能加载不全,建议下载浏览。
2 rknn模型的C++部署
2.1 更新库并查看版本
- 更新librknnrt.so库
cp /usr/lib/librknnrt.so /usr/lib/librknnrt.so_bk
cp convert_rknn2.1/rknn-toolkit2-2.1.0/rknpu2/runtime/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/
sudo chmod +x /usr/lib/librknnrt.so
- 查看librknnrt.so库版本
strings /usr/lib/librknnrt.so | grep -i "librknnrt version"
# 结果显示
librknnrt version: 2.1.0 (967d001cc8@2024-08-07T19:28:19)
2.2 更新服务并查看版本
- 更新服务
cp /usr/bin/restart_rknn.sh /usr/bin/restart_rknn.sh.bk
cp /usr/bin/rknn_server /usr/bin/rknn_server.bk
cp /usr/bin/start_rknn.sh /usr/bin/start_rknn.sh.bk
cp convert_rknn2.1/rknn-toolkit2-2.1.0/rknpu2/runtime/Linux/rknn_server/aarch64/usr/bin/* /usr/bin/
sudo chmod +x /usr/bin/restart_rknn.sh
sudo chmod +x /usr/bin/rknn_server
sudo chmod +x /usr/bin/start_rknn.sh
- 查看服务版本
strings /usr/bin/rknn_server | grep -i "rknn_server version"
# 结果显示
rknn_server version: 2.1.0 (6405676 build@2024-08-03T14:59:00)
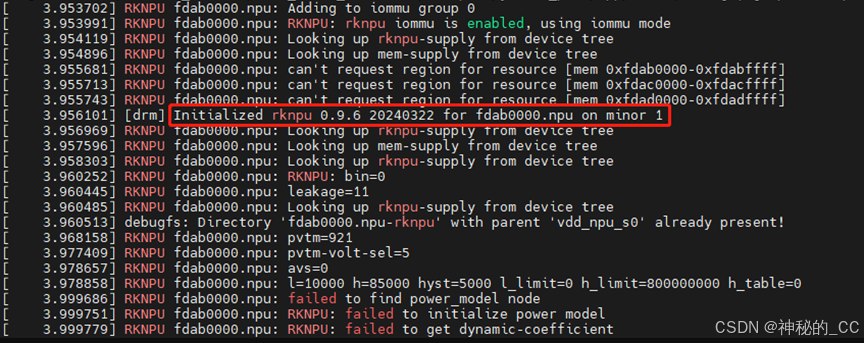
2.3 查看npu版本
dmesg | grep -i rknpu
# 结果显示
Initialized rknpu 0.9.6 20240322 for fdab0000.npu on minor 1 # 其中显示版本号rknpu 0.9.6
2.4 构建项目
cd convert_rknn2.1/rknn_model_zoo-2.1.0/examples/yolov8_pose/cpp_pose/build_pose/
make -j
2.5 运行程序
cd convert_rknn2.1/rknn_model_zoo-2.1.0/examples/yolov8_pose/cpp_pose/run_pose/
../build_pose/rknn_yolov8_pose_demo ./yolov8s_pose.rknn ./1.jpg
【遇到问题1】
执行运行命令./rknn_yolov8_pose_demo ./yolov8_pose_rk3588.rknn ./1.jpg后,rknn_init函数报错,但是用的就是官方demo文件,我本身没有做修改。

【解决方案1】
查看报错代码,提示传入参数错误。
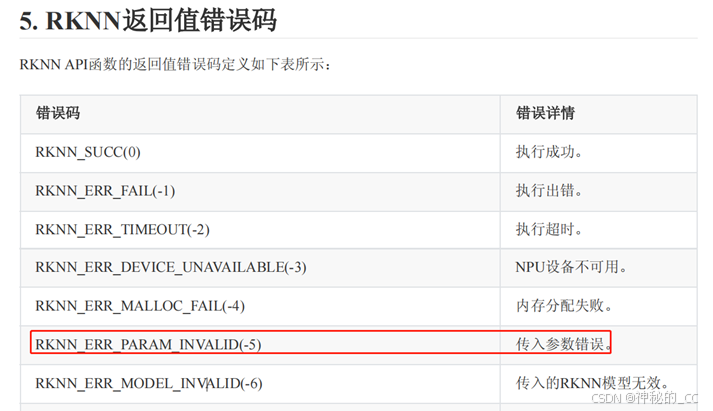
查文档,发现允许传入rknn模型路径与二进制数据。官方demo中传入的是rknn模型路径,但是传入rknn模型路径会报错,改为传入rknn模型的二进制数据解决。
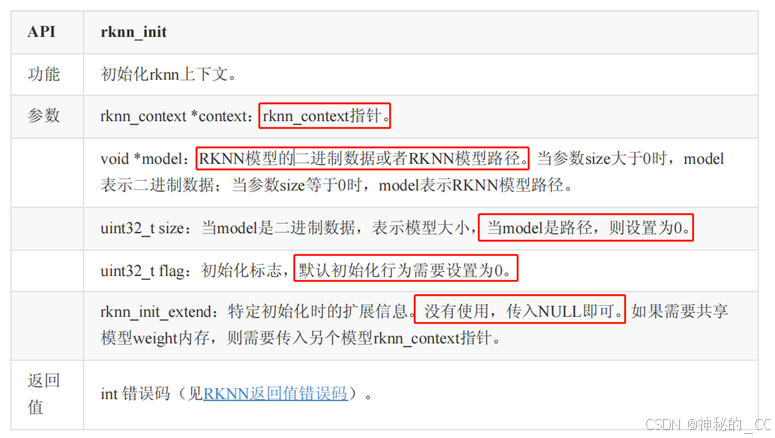
【遇到问题2】
模型读入正确了,rknn_init函数又报错。

【解决方案2】
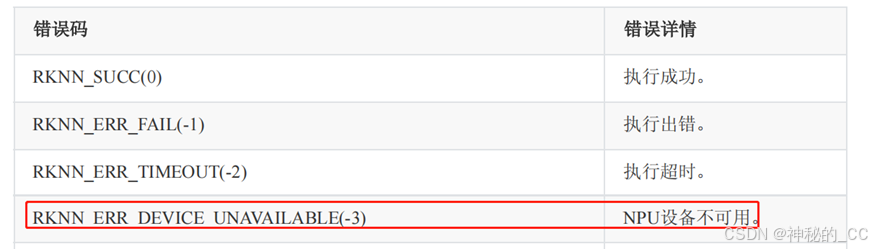
查看文档,根据返回值-3,是NPU设备不可用。
刚开始以为是npu驱动问题,通过以下命令查看,发现也没有问题。
dmesg | grep -i rknpu
最后更新了rknn_server版本,librknnrt.so库版本,要与所用的toolkit版本一致rknn-toolkit2.1.0。
strings /usr/bin/rknn_server | grep -i “rknn_server version”

strings /usr/lib/librknnrt.so | grep -i “librknnrt version”

但是发现,还是不行。
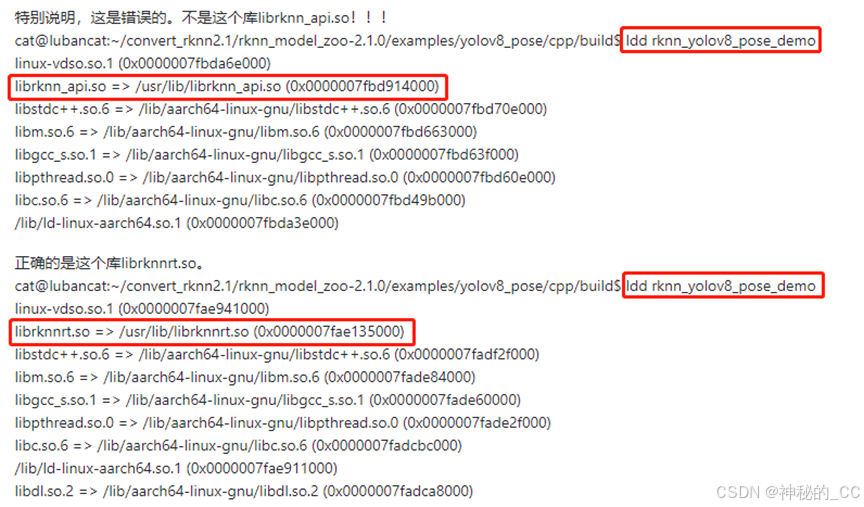
最后ldd rknn_yolov8_pose_demo发现,是我链接的库错了!!!
刚开始链接的库为librknn_api.so,最后修改,保证链接的运行时库为librknnrt.so,然后解决。
2.6 推理结果

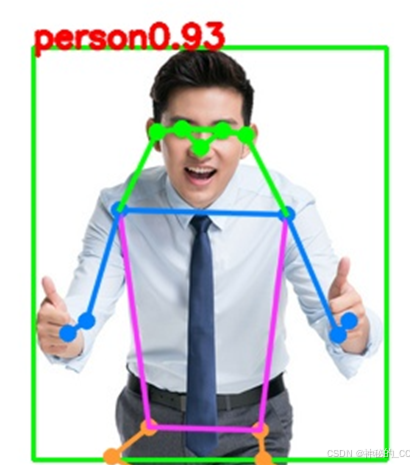


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









