







概述

GeoParquet是一种用于存储地理空间数据的文件格式,基于Apache Parquet。它支持高效地存储和查询大型地理空间数据集,具有良好的压缩性能和**列式**存储结构。GeoParquet还与许多地理信息系统(GIS)和大数据处理工具兼容,使得地理数据处理更加灵活和高效。
- 基础概念:GeoParquet基于Apache Parquet,是一种列式存储格式,适用于大规模数据集。它使用了高效的压缩算法,减少了存储需求并提高了读取速度。
- 地理空间支持:GeoParquet扩展了Parquet,以支持地理空间数据类型,如点、线、面等。它符合OGC(开放地理空间联盟)的标准,使得GIS应用可以直接处理这些数据。
- 数据模型:在GeoParquet中,数据通常以“属性-几何”的形式存储,属性包含特征的信息,而几何则描述空间位置。这样可以方便地进行复杂的空间查询和分析。
- 优势:
- 高效存储:由于采用列式存储,读取特定列的数据时速度更快,尤其在处理大规模数据时。
- 灵活性:支持多种数据类型和复杂结构,适用于多样化的GIS应用场景。
- 兼容性:与多种大数据框架(如Apache Spark、Flink)和GIS工具(如QGIS、PostGIS)兼容,方便集成和使用。
- 应用场景:GeoParquet适用于大数据分析、机器学习、实时数据处理等场景,特别是在需要处理大量地理空间数据时。
- 学习和使用:可以通过实际项目来深入了解GeoParquet,比如使用Apache Spark进行数据处理,或者将其与GIS工具结合,进行可视化和分析。
相关网站
与常见矢量存储格式的异同
GeoParquet与常见的SHP(Shapefile)和GeoJSON文件在几个关键方面有所不同:
- 存储格式:
- SHP:基于二进制格式,通常由多个文件(.shp、.shx、.dbf等)组成,适合存储简单的几何和属性数据,但不支持复杂数据结构。
- GeoJSON:基于文本格式(JSON),易于阅读和编辑,适合小型数据集,但在存储和处理大型数据时效率较低。
- GeoParquet:基于列式存储格式,支持高效的压缩和查询,适合大规模数据集。
- 数据类型支持:
- SHP和GeoJSON:支持常见的几何类型,但在复杂数据结构(如多几何体)支持上有限。
- GeoParquet:支持更丰富的地理空间数据类型,符合OGC标准,可以处理复杂的几何结构。
- 性能:
- SHP:读取速度较快,但文件大小较大,且支持的数据量有限。
- GeoJSON:便于交换和使用,但在处理大数据集时效率较低。
- GeoParquet:由于其列式存储特性,读取和查询大型数据集时性能优越,适合大数据分析。
- 兼容性与应用:
- SHP和GeoJSON:广泛支持于各种GIS软件和工具,易于使用和共享。
- GeoParquet:与大数据处理框架(如Apache Spark)兼容,适合进行大规模数据分析。
有关生态
目前GeoParquet生态已有很多工具与库供外部使用,具体可参考GeoParquet官网首页下方链接。
Tools
- Browser-based converter(基于浏览器的转换器):由GPQ库驱动,可在浏览器中实现GeoJSON与GeoParquet之间的互相转换。
- GeoPandas** (Python) **:扩展了pandas的数据类型,支持几何类型的空间操作,并支持GeoParquet文件的reading与writing。
- QGIS:Windows和Linux版本原生支持GeoParquet。Mac用户可以通过conda安装支持(在激活的conda环境中运行以下命令:
conda config --add channels conda-forge
conda install qgis libgdal-arrow-parquet
qgis
然后直接在终端中输入qgis运行软件)。
- Scribble Maps:一个功能全面的Web应用,支持GeoParquet的导入和导出。
- BigQuery Converter:提供Python脚本,用于与Google BigQuery交互,读取和写入GeoParquet文件。
- CARTO:一个地理空间平台,支持GeoParquet的supports import。
- gpq:提供一个命令行界面,用于验证和描述任何GeoParquet文件,还可以将GeoParquet转换为GeoJSON,反之亦然。
- stac-geoparquet:将STAC目录(SpatioTemporal Asset Catalogs)转换为GeoParquet。
- Apache Sedona:一个用于处理大规模空间数据的集群计算系统,可扩展Apache Spark和Apache Flink。它支持通过Scala、Java、Python或Rload和saveGeoParquet。
- Esri’s ArcGIS GeoAnalytics Engine:通过扩展Apache Spark,提供空间分析功能和工具。它的Python库或Spark插件支持加载或保存GeoParquet文件。详见其GeoParquet page。
- FME: by Safe Software:一个无需编写代码的平台,从version 23.1开始支持GeoParquet文件的读写。
- SeerAI’s** **Geodesic Platform:一个云原生的、全球规模的时空数据网格和数据融合平台。其Boson服务网格原生支持GeoParquet,并能通过API以兼容格式向其他分析系统和地理空间软件暴露大规模GeoParquet数据集。所有表格和要素数据输出均以Parquet/GeoParquet格式保存。
- Wherobots:一个完全托管的云空间数据湖仓(data lakehouse),支持任何规模的地理空间数据管理和分析。所有数据可保存为GeoParquet格式,并使用其Havasu Spatial Table Format进行目录管理。
- pygeoapi:OGC API标准套件的Python服务器实现,支持一个Parquet数据提供程序,将GeoParquet文件发布为OGC API - Features集合。
Libraries
- geoarrow ®
- sfarrow ®
- GDAL/OGR (C++, bindings in several languages)
- GeoParquet.jl (Julia)
- gpq (Go and WASM)
- Fiona (Python - as of version 1.9.4. Note the GeoParquet driver will only be available if your system’s GDAL library links libarrow; fiona wheels on PyPI do not include libarrow as it is rather large.)
- .NET 6 library (.NET)
- C++ example code - see this discussion topic for more info.
使用示例
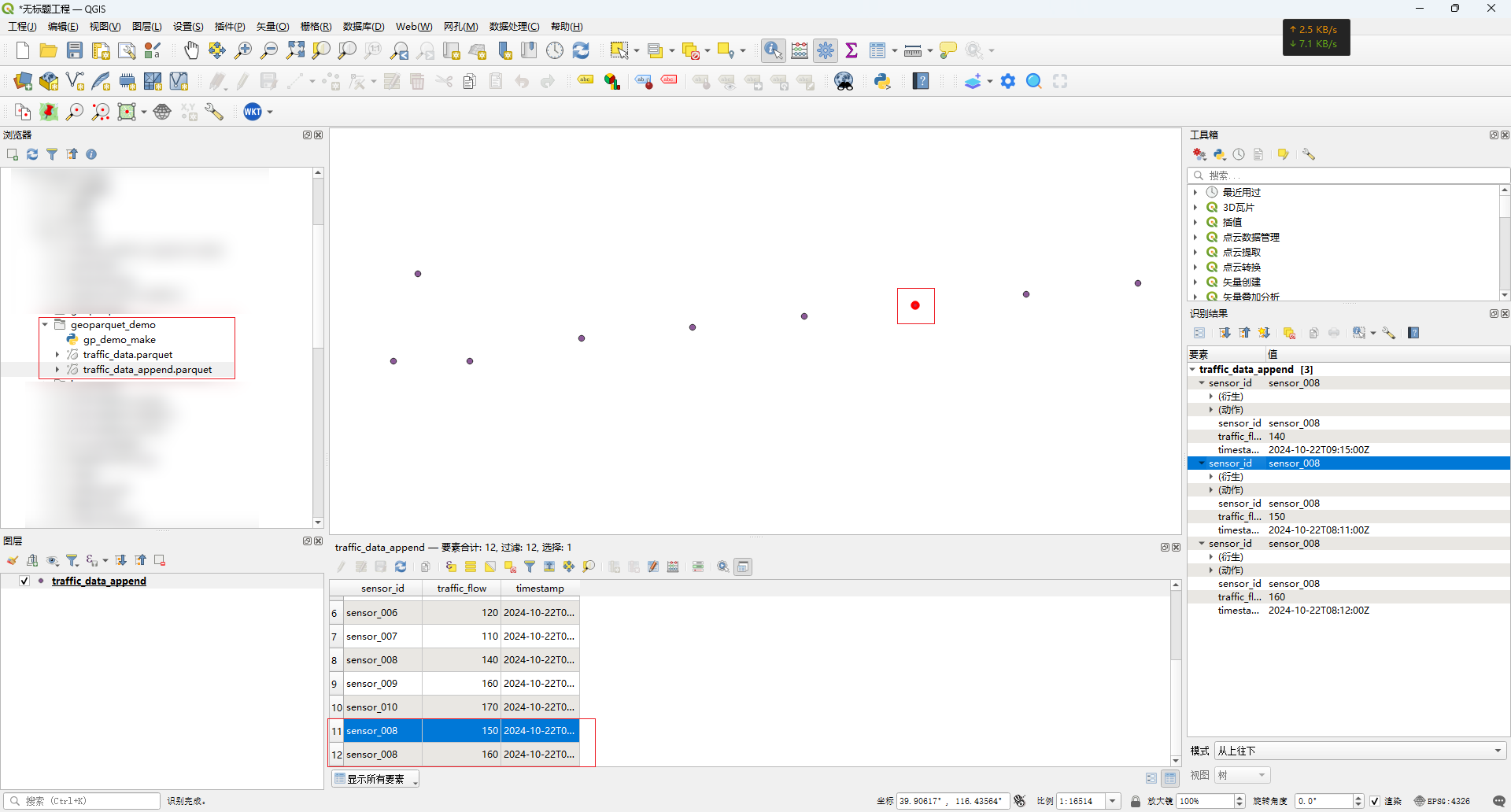
使用GeoPandas完成GeoParquet文件的生成、读取、编写;使用QGIS完成GeoParquet文件的加载渲染。
- Conda虚拟环境创建(可选)
conda create -n geoparquet_env python=3.9
conda activate geoparquet_env
- Python库安装
conda install -c conda-forge pyarrow geopandas
- 编写示例代码
import geopandas as gpd
import pandas as pd
from shapely.geometry import Point
import numpy as np
# GeoParquet-创建数据
# 创建示例数据
data = {
'sensor_id': [
'sensor_001', 'sensor_002', 'sensor_003', 'sensor_004', 'sensor_005',
'sensor_006', 'sensor_007', 'sensor_008', 'sensor_009', 'sensor_010'
],
'traffic_flow': [120, 150, 90, 200, 180, 120, 110, 140, 160, 170],
'timestamp': [
'2024-10-22T08:30:00Z', '2024-10-22T08:30:00Z', '2024-10-22T08:30:00Z',
'2024-10-22T08:45:00Z', '2024-10-22T08:45:00Z', '2024-10-22T09:00:00Z',
'2024-10-22T09:00:00Z', '2024-10-22T09:15:00Z', '2024-10-22T09:15:00Z',
'2024-10-22T09:30:00Z'
],
'geometry': [
Point(116.397128, 39.916527), Point(116.405285, 39.925818),
Point(116.403122, 39.917989), Point(116.410000, 39.918000),
Point(116.420000, 39.920000), Point(116.430000, 39.921000),
Point(116.440000, 39.922000), Point(116.450000, 39.923000),
Point(116.460000, 39.924000), Point(116.470000, 39.925000)
]
}
# 创建GeoDataFrame
gdf = gpd.GeoDataFrame(data, crs="EPSG:4326")
# 保存为GeoParquet文件
gdf.to_parquet('traffic_data.parquet', engine='pyarrow')
# GeoParquet-读取数据
# 读取GeoParquet文件
gdf = gpd.read_parquet('traffic_data.parquet')
# 过滤出8号传感器的车流量数据
sensor_8_data = gdf[gdf['sensor_id'] == 'sensor_008']
print(sensor_8_data[['timestamp', 'traffic_flow']])
# GeoParquet-追加数据并保存
# 读取现有的GeoParquet文件
gdf = gpd.read_parquet('traffic_data.parquet')
# 创建要追加的新数据
new_data = {
'sensor_id': ['sensor_008', 'sensor_008'], # 传感器ID
'traffic_flow': [150, 160], # 新车流量数据
'timestamp': ['2024-10-22T08:11:00Z', '2024-10-22T08:12:00Z'], # 新时间戳
'geometry': [Point(116.450000, 39.923000), Point(116.450000, 39.923000)] # 新位置
}
# 将新数据转换为DataFrame
new_df = gpd.GeoDataFrame(new_data, crs="EPSG:4326")
# 将新数据追加到原有DataFrame
gdf = pd.concat([gdf, new_df], ignore_index=True)
# 保存更新后的GeoDataFrame为GeoParquet文件
gdf.to_parquet('traffic_data_append.parquet', engine='pyarrow')
# GeoParquet-读取数据
# 读取GeoParquet文件
gdf = gpd.read_parquet('traffic_data_append.parquet')
# 过滤出8号传感器的车流量数据
sensor_8_data = gdf[gdf['sensor_id'] == 'sensor_008']
print(sensor_8_data[['timestamp', 'traffic_flow']])
- QGIS双击文件添加到图层


















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









