






 本文探讨了一种结合嗅觉神经网络和视觉神经网络的深度学习系统。通过自编码器处理嗅觉传感器数据,对20种物质进行识别,而卷积神经网络用于解析彩色图像信息。最后,利用全连接层神经网络动态调整嗅觉和视觉识别结果的权重,实现对不同物质的综合判断。该系统模仿人类大脑对多感官信息的处理方式,提高了识别的准确性和鲁棒性。
本文探讨了一种结合嗅觉神经网络和视觉神经网络的深度学习系统。通过自编码器处理嗅觉传感器数据,对20种物质进行识别,而卷积神经网络用于解析彩色图像信息。最后,利用全连接层神经网络动态调整嗅觉和视觉识别结果的权重,实现对不同物质的综合判断。该系统模仿人类大脑对多感官信息的处理方式,提高了识别的准确性和鲁棒性。
嗅觉神经网络
六个传感器组成的传感器阵列,每组数据如下:
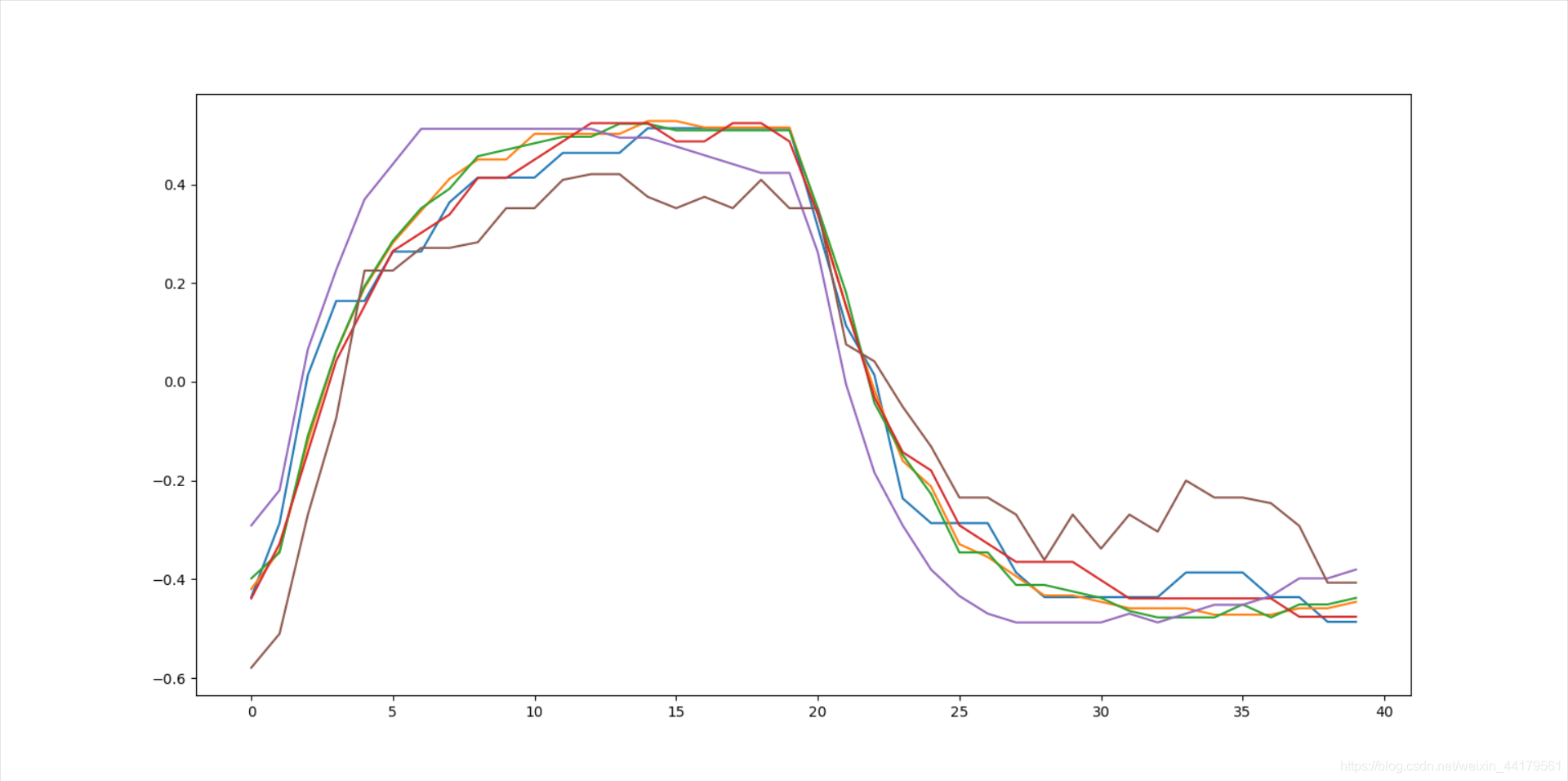
其应是一个(6,40)的矩阵,行表示传感器,列表示时间,内部元素是每个传感器在每一秒处的响应值。
对20种实验物质进行采集,每种物质采集10组数据,共200组数据。其中,每组数据为明确属于不同传感器的响应,制成六通道的数据形式。最终训练集为(200,6,1,40)的四维矩阵。而标签集为(200,20)的矩阵,列索引对应物质种类,200行为200组数据的标签,是one-hot型的矩阵,i行j列为1表示第i组数据是物质j。将训练集和标签集导入自编码器中进行训练。
训练完成的自编码器,在完成识别任务时,导入一组检测数据(1,6,1,40),其Encoder输出的softmax矩阵为(1,20),每列上的索引对应物质种类。

视觉神经网络
对于20种物质,分别用蓝色激光和绿色激光进行照射,然后用相机拍摄图片。


每张图片的像素都是(960,960),由于是彩色图片,因此每张照片实际上是三通道的矩阵(3,960,960)。鉴于一种物质分别有蓝色激光和绿色激光照射下所拍的两张图片,将其制成六通道的矩阵(6,960,960)。与嗅觉同理,同样制作成训练集(N,6,960,960)N是图片数量,标签集(N,20)。

将训练集与标签集用于卷积神经网络的训练,网络的最后同样经由全连接层输出成softmax形式的矩阵。
最终决策网络
参考生活中的经验,我们可以想到,在日常生活中,人们常常结合嗅觉与视觉对物体进行识别,但大多数情况下,嗅觉的判断结果与视觉的判断结果在我们的大脑中的权重是根据识别的物质的不同而变化的。
举个例子来说,当识别橙汁时,通过封装的透明饮料瓶,我们的视觉可以看到黄色的液体以及里面的果肉颗粒物,此时我们视觉的判断结果是橙汁,而我们的大脑就已经确认这瓶饮料是橙汁了。而我们的嗅觉甚至还没能闻到饮料瓶里的气味。显然,在这种情况下,视觉的判断结果所占的权重比嗅觉要大。
而在识别榴莲、臭豆腐等气味浓烈的物质时,人们甚至在尚未看到物质时就能仅通过嗅觉判断出物质的种类,此时显然嗅觉的判断结果所占的权重要比视觉的大得多。
参考以上推论,本文借用全连接层神经网络,通过训练来让它自行决定对不同物质时,嗅觉与视觉判断结果所占的权重。
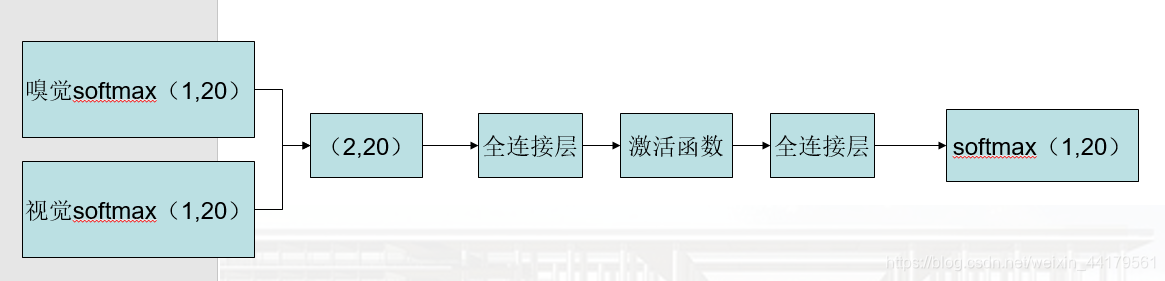
最后所获取的softmax输出结果就是整个结合了神经网络对这种物质的识别结果,与此前的单一感官的神经网络所不同的在于,该神经网络并非仅根据嗅觉信息或视觉信息来做出而别,而是同时结合了嗅觉所获取的信息和视觉所获取的信息,进行综合判断后再给出识别结果。

















 3107
3107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









