







一、基本概念
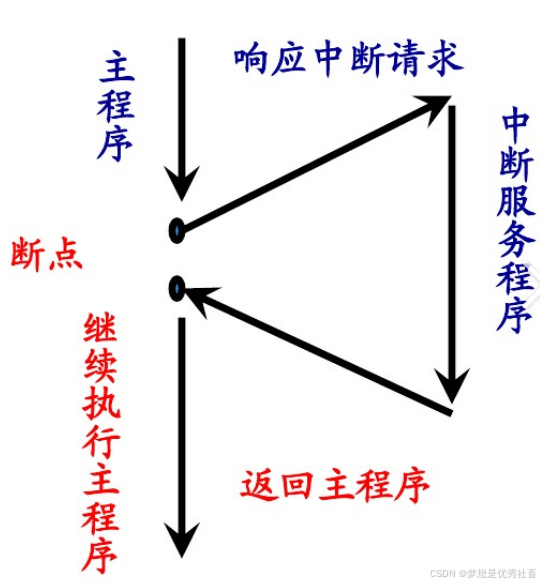
定义:CPU在运行过程中,发生了某些紧急事件需要处理,CPU必须保存现场,暂停当前程序,转而处理紧急事件,处理完毕后再返回原程序继续执行。
内部中断/外部中断:内部中断源来自于CPU内部,如溢出、软件中断指令 等;外部中断来自于CPU外部,由外设提出中断请求
可屏蔽中断/不可屏蔽中断:可屏蔽中断可以通过配置中断控制寄存器等方法被屏蔽,屏蔽后不再处理响应中断
向量中断/非向量中断:向量中断会给中断分配中断号,由硬件决定中断入口地址;非向量中断共享同一个入口地址,进入该地址后,再由软件判别具体执行哪个中断处理函数,下面是非向量中断的中断服务程序示例。

二、中断控制器

中断控制器是负责处理器所有中断源的采集、仲裁和分发的机制/硬件模块。
不同架构使用的中断控制器总结如下:
| 指令架构 | 控制器 | 备注 |
| X86 | 8259(A) -> APIC | APIC相比于8259A,区分本地APIC和I/O APIC,支持多核中断、虚拟中断处理,可支配中断数量更大 |
| ARM | VIC -> NVIC、 GIC(v1-v4) | VIC支持快速中断、向量中断、非向量中断 NVIC 支持中断嵌套,主要用于Cortex-M系列微控制器中 GIC支持多核中断、虚拟中断处理,主要用于Cortex-A/Cortex-R系列处理器中 |
| PowerPC | MPIC、EPIC | MPIC支持多核中断处理 EPIC支持中断嵌套 |
三、底半部和顶半部
3.1. 基本概念
为了在中断执行时间尽量短和中断处理需完成的工作尽量大之间找到一个平衡点,Linux将中断处理程序分解为两个半部:顶半部和底半部。
为什么要分底半部和顶半部?
理想情况下,为了保证系统任务的实时性,都要求中断的处理必须是非阻塞的、快速的,然而实际情况并没有那么理想,比如I\O引发的中断,就可能需要进行数据处理。因此操作系统一般都会提供中断上下文和非中断上下文结合的机制,共同完成中断处理。Linux的机制则称为底半部和顶半部
3.2. Linux的底半部实现机制
3.2.1. 软中断
软中断注册:
软中断通过open__softirq接口将软中断号以及处理函数联系在一起,软中断号和处理函数在编译过后即确定,不可运行中修改。Linux上可注册的软中断是有效的,最多32个,目前已用10个。
struct softirq_action {
void (*action) (struct softirq_action *); /* 软中断的处理函数 */
};
static struct softirq_action softirq_vec[NR_SOFTIRQS];
enum {
HI_SOFTIRQ = 0, /* 优先级高的tasklets */
TIMER_SOFTIRQ, /* 定时器的下半部 */
NET_TX_SOFTIRQ, /* 发送网络数据包 */
NET_RX_SOFTIRQ, /* 接收网络数据包 */
BLOCK_SOFTIRQ, /* BLOCK装置 */
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /* 正常优先级的tasklets */
SCHED_SOFTIRQ, /* 调度程序 */
HRTIMER_SOFTIRQ, /* 高分辨率定时器 */
RCU_SOFTIRQ, /* RCU锁定 */
NR_SOFTIRQS /* 10 */
};
void open_softirq(int nr, void (*action) (struct softirq_action *))
{
softirq_vec[nr].action = action;
}软中断原理 :
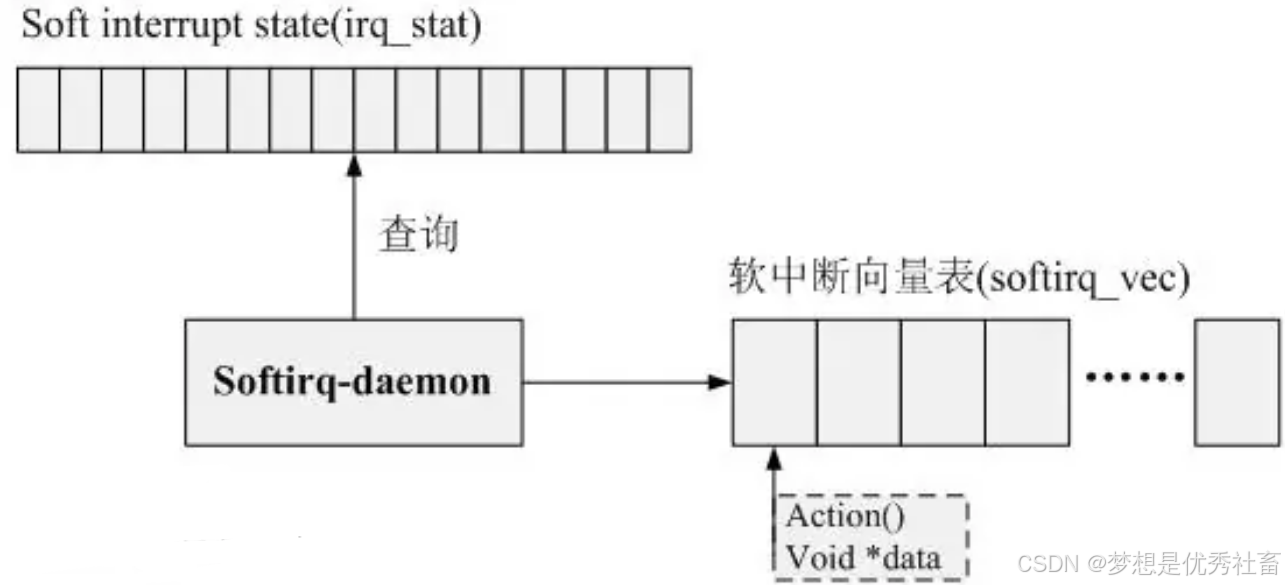
构成软中断机制的核心元素包括:
1、 软中断状态寄存器soft interrupt state(irq_stat)
2、 软中断向量表(softirq_vec)
3、 软中断守护daemon
软中断的工作工程模拟了实际的中断处理过程,当某一软中断事件发生后,首先需要设置对应的中断标记位,触发中断事务,然后唤醒守护线程去检测中断状态寄存器,如果通过查询发现有软中断事务发生,那么通过查询软中断向量表调用相应的软中断服务程序action()。
软中断的三个触发场景:
- 当调用local_bh_enable()函数激活本地CPU的软中断时。条件满足就调用do_softirq() 来处理软中断。
- 当do_IRQ()完成硬中断处理后调用irq_exit()时,调用do_softirq()来处理软中断。
- 当内核线程ksoftirqd/n被唤醒时,处理软中断。
软中断与硬件中断的区别:
1. 软中断的中断向量表映射过程由守护线程完成,硬件中断由硬件中断控制器自动完成。2. 软中断不能相互抢占,硬件中断可以抢占软中断,且硬件中断之间可分配抢占优先级,实时性更高。
3. 软中断可以在多个CPU上并行执行 ,因此处理函数需要为可重入函数,同一个硬件中断同一时间只能由一个CPU处理。
软中断(下半部)是以内核线程的方式执行,并且每一个 CPU 都对应一个软中断内核线程,名字通常为ksoftirqd/0 断(下半部)是以内核线程的方式执行,并且每一个 CPU 都对应一个软中断内核线程,名字通常为"ksoftirqd/CPU 编号"
不过,软中断不只是包括硬件设备中断处理程序的下半部,一些内核自定义事件也属于软中断,比如内核调度等、RCU 锁(内核里常用的一种锁)等。
既然软中断是软件模拟的中断行为,为什么不直接用普通的线程调度代替软中断进行底半部的处理?
1. 软中断相较于普通线程的优先级更高,能够一定程度保证实时性。
2. 软中断工作在内核态,可以访问系统资源完成底半部的数据处理工作。
3. 软中断在多个CPU上并行执行,提高了系统的总体效率。
3.2.2. tasklet
tasklet注册:
tasklet的行为和状态通过tasklet_struct描述,有三种注册tasklet任务的方法,两种静态一种动态。
struct tasklet_struct
{
struct tasklet_struct *next;//将多个tasklet链接成单向循环链表
unsigned long state; //TASKLET_STATE_SCHED, TASKLET_STATE_RUN
atomic_t count; //0:激活tasklet 非0:禁用tasklet
void (*func)(unsigned long); //该tasklet处理程序
unsigned long data; //传递给tasklet处理函数的参数
};
//定义名字为name的激活tasklet
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
//定义名字为name的非激活tasklet
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
//动态初始化tasklet
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
tasklet原理:
tasklet基于软中断实现,上下文是软中断,执行时机是顶半部返回的时候。
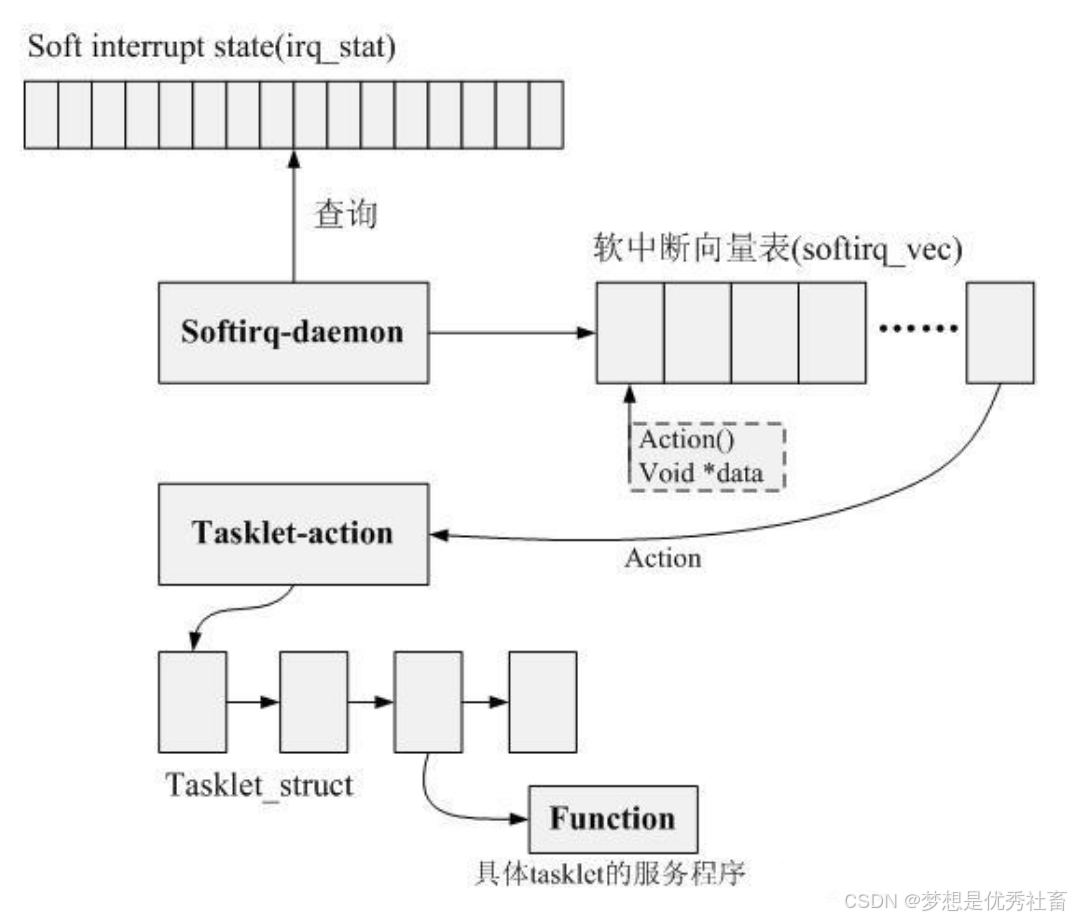
完成tasklet注册后,驱动模块可以在中断处理的上半部分调用tasklet_schedule,该接口会触发TASKLET_SOFTIRQ软中断,并将自定义的tasklet加入到内核维护的tasklet链表中。触发完成后,tasklet_action函数作为TASKLET_SOFTIRQ软中断的处理函数以下半部的形式在一个合适的推迟的时间点上被内核运行,该函数会扫描tasklet的链表,针对链表中的每一个预先注册的tasklet,调用回调函数function。
程序在多个上下文中可以多次调度同一个tasklet执行(也可能来自多个cpu core),不过实际上该tasklet只会一次挂入首次调度到的那个cpu的tasklet链表,也就是说,即便是多次调用tasklet_schedule,实际上tasklet只会挂入一个指定CPU的tasklet队列中(而且只会挂入一次)。这是通过数据结构字段TASKLET_STATE_SCHED实现的。
既然已经有了软中断,为什么还要加以封装,提出tasklet?
1. 同一种tasklet同一时间内只能在一个CPU上执行,不需要可重入函数,编程简单2. 软中断只能注册32中,而tasklet无类型数量限制
3. 软中断编译后即锁定,tasklet可在运行过程中动态改变
3.2.3. 工作队列
工作队列注册:
工作队列可挂载工作项,包括普通工作项、高优先级工作项、延迟工作项,可挂载在缺省工作队列上,也可挂载在自定义工作队列中。
struct work_struct {
atomic_long_t data; //传递给工作函数的参数
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; //链表结构,链接同一工作队列上的工作。
work_func_t func; //工作函数,用户自定义实现
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
//工作队列执行函数的原型:
void (*work_func_t)(struct work_struct *work);
//该函数会由一个工作者线程执行,因此其在进程上下文中,可以睡眠也可以中断。但只能在内核中运行,无法访问用户空间。
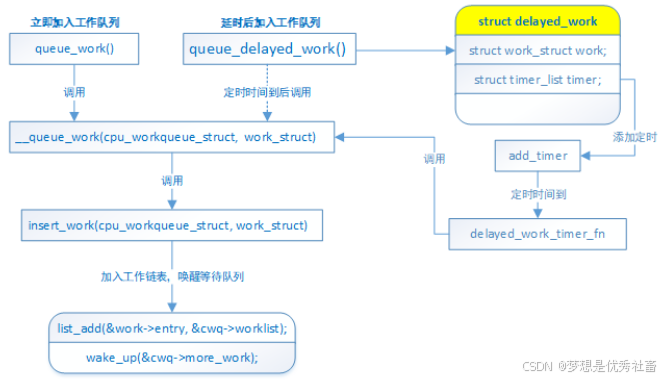
struct delayed_work {
struct work_struct work;
struct timer_list timer; //定时器,用于实现延迟处理
};
/*1.缺省工作队列任务创建*/
struct work_struct my_work;
struct delayed_work my_delayed_work;
// 静态创建
DECLARE_WORK(&my_work,function); //定义正常执行的工作项
DECLARE_DELAYED_WORK(&my_delayed_work,function);//定义延后执行的工作项
// 动态创建
INIT_WORK(&my_work, _func) //创建正常执行的工作项
INIT_DELAYED_WORK(&my_delayed_work, _func)//创建延后执行的工作项
// 调度默认工作队列
int schedule_work(struct work_struct *work);
// 对正常执行的工作进行调度,即把给定工作的处理函数提交给缺省的工作队列和工作者线程。
//工作者线程本质上是一个普通的内核线程,在默认情况下,每个CPU均有一个类型为“events”的工作者线程,当调用schedule_work时,这个工作者线程会被唤醒去执行工作链表上的所有工作。
// 系统默认的工作队列名称是:keventd_wq,默认的工作者线程叫:events/n,这里的n是处理器的编号,每个处理器对应一个线程。比如,单处理器的系统只有events/0这样一个线程。而双处理器的系统就会多一个events/1线程。
// 默认的工作队列和工作者线程由内核初始化时创建:
// start_kernel()-->rest_init-->do_basic_setup-->init_workqueues
// 调度延迟工作
int schedule_delayed_work(struct delayed_work *dwork,unsigned long delay);
// 刷新缺省工作队列
void flush_scheduled_work(void)
//此函数会一直等待,直到队列中的所有工作都被执行。
// 取消延迟工作
static inline int cancel_delayed_work(struct delayed_work *work)
//flush_scheduled_work并不取消任何延迟执行的工作,因此,如果要取消延迟工作,应该调用cancel_delayed_work。
/*2.自定义工作队列创建*/
struct workqueue_struct *p_my_workqueue;
//宏定义 返回值为工作队列,name为工作线程名称。创建新的工作队列和相应的工作者线程,name用于该内核线程的命名
p_my_workqueue = create_singlethread_workqueue(name);
// p_my_workqueue = create_workqueue(name);
// 类似于schedule_work,区别在于queue_work把给定工作提交给创建的工作队列wq而不是缺省队列
int queue_work(struct workqueue_struct *wq, struct work_struct *work);
// 调度延迟工作
int queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork, unsigned long delay);
// 刷新指定工作队列
void flush_workqueue(struct workqueue_struct *wq);
// 释放创建的工作队列
void destroy_workqueue(struct workqueue_struct *wq);工作队列原理:
工作队列的上下文是内核线程,可以睡眠和调度。
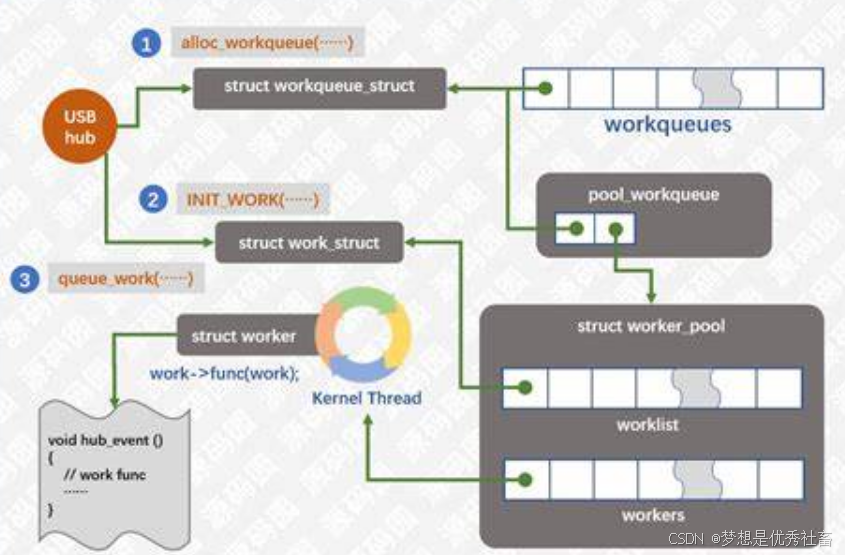
内核会为每个CPU创建独立的缺省工作队列cpu_workqueue_struct,用户也能根据需要自定义工作队列。每个工作队列会对应一个或多个工作线程池,当调用schedule_work/queue_work函数将work_struct插入到工作队列中后,会由工作者线程将队列中等待执行的工作逐一出队、执行。当工作队列为空时,相应的工作者线程会被挂起。
工作队列相比于软中断/tasklet的优劣势是什么?
优势:
1. 上下文是内核线程,可阻塞/睡眠
2. 工作队列提供定时器进行延迟操作3. 可缓存多个工作项,集中处理
劣势:
1. 如果一个工作队列上注册太多任务,则会影响队列性能,每个任务都需要等待上一个任务完成才能够执行
注:工作队列的本质,是对内核线程的封装,让用户能够较容易地使用内核线程资源,而不用花费大量功夫管理。
3.2.4. 线程化irq
threaded irq注册:
/**
* @param irq [unsigned int] 中断号,标识要处理的中断。
* @param handler [irq_handler_t] 中断处理函数,当硬件中断发生时调用。这个函数通常执行快速的、时间敏感的操作。
* @param thread_fn [irq_handler_t] 线程处理函数,在进程上下文中调用,用于处理不需要立即响应的任务。
* @param flags [unsigned long] 中断标志,控制中断处理的行为,如IRQF_SHARED(允许多个设备共享同一个中断)等。
* @param name [const char *] 中断处理程序的名称,用于调试和日志记录。
* @param dev [void *] 设备相关的数据指针,传递给中断处理函数,通常指向设备结构体。
*
* @return 返回0表示成功,负值表示错误代码。
*/
int request_threaded_irq(unsigned int irq,
irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long flags,
const char *name,
void *dev);threaded irq原理:
将中断线程化,中断底半部的操作作为内核线程运行,可被赋予不同的实时优先级。在负载较高时,中断线程可以被挂起,以避免某些更高优先级的实时任务得不到及时响应。
threaded irq的优势?
将中断处理作为独立的线程运行,各个线程的任务执行不会相互影响。
四、共享中断
随着设备的增加,一个中断号对应一个中断处理程序已经不太现实,于是诞生了共享中断的机制。多个设备使用同一个中断线号,同一个中断设备线号的所有处理程序链接成一个链表,这样当下一个中断产生的时候,就要遍历其对应的处理程序链表。通过dev_id判断是否为本设备的中断。
Linux支持这种中断共享,下面是中断共享的使用方法:
1)共享中断的多个设备在申请中断时,都应该使用IRQF_SHARED标志,而且一个设备以IRQF_SHARED申请某中断成功的前提是该中断未被申请,或该中断虽然被申请了,但是之前申请该中断的所有设备也都以IRQF_SHARED标志申请该中断。
2)尽管内核模块可访问的全局地址都可以作为request_irq(…,void*dev_id)的最后一个参数dev_id,但是设备结构体指针显然是可传入的最佳参数。
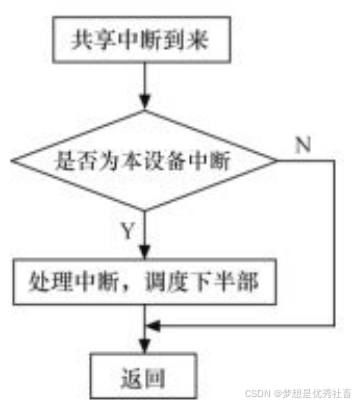
3)在中断到来时,会遍历执行共享此中断的所有中断处理程序,直到某一个函数返回IRQ_HANDLED。在中断处理程序顶半部中,应根据硬件寄存器中的信息比照传入的dev_id参数迅速地判断是否为本设备的中断,若不是,应迅速返回IRQ_NONE,如下图所示。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











