







概论
梯度下降(Gradient Descent GD)是用来寻求损失函数(loss function)最小化的方法,最为常用随机梯度下降(stochastic gradient descent)SGD,几乎可以解决除了决策树之外所有算法的损失函数最小化问题。
比较通俗的例子是一个人站在山顶,为了尽快下山,这个人需要寻找当前位置最为陡峭的方向往下走。
另一个更好的例子是山泉流入山谷的过程。
- 水本身是受到重力影响的,水流就会沿着当前最为陡峭的方向流动,甚至是垂直流下。(梯度下降)
- 水流在某些地方,会分流,因为多个方向具有同样的陡峭度(梯度)。(可能有多个解)
- 遇到洼地,水流可能形成湖泊,而不再往山下流。(局部最优,不是全局最优)
理论基础
了解梯度下降,需要数学中微积分的相关知识。包括导数、微分、偏导数、梯度。
导数和微分
导数的几何意义是该函数曲线在这一点上的切线斜率。函数 y = f ( x ) y=f(x) y=f(x)在 x 0 x_{0} x0点的导数 f ′ ( x 0 ) f'(x_{0}) f′(x0)的几何意义:表示函数曲线在点 P 0 ( x 0 , f ( x 0 ) ) P_{0}(x_{0}, f(x_{0})) P0(x0,f(x0))处的切线的斜率。
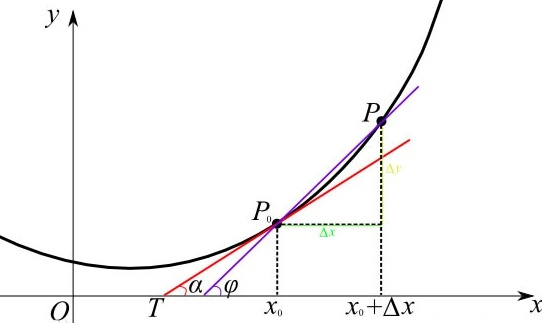
导数的计算,几乎就是所有深度学习中优化算法的关键步骤。深度学习中通常选取的损失函数,是对于模型参数可微的。
简而言之,对于每一个参数,如果我们对这个参数增加或者减少一个无穷小的量,我们可以知道损失会以多快的速度增加和减少。
假设我们有一个函数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R,其输入和输出都是标量。如果 f f f的导数存在,这个极限被定义为
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h . f'(x) = \lim_{h \rightarrow 0} \frac{f(x+h) - f(x)}{h}. f′(x)=h→0limhf(x+h)−f(x).
如果
f
′
(
a
)
f'(a)
f′(a)存在,则称
f
f
f在
a
a
a处是可微(differentiable)的。如果
f
f
f在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。
我们可以将 导数
f
′
(
x
)
f'(x)
f′(x)解释为
f
(
x
)
f(x)
f(x)相对于
x
x
x的瞬时(instantaneous)变化率。所谓的瞬时变化率是基于
x
x
x中的变化
h
h
h,且
h
h
h接近
0
0
0。
偏导数
前面我们只描述了一个变量的函数的微分。在深度学习中,目标函数通常依赖于许多变量。因此,我们需要将微分的思想推广到多元函数(multivariate function)上。
偏导数的几何意义

设 y = f ( x 1 , x 2 , … , x n ) y = f(x_1, x_2, \ldots, x_n) y=f(x1,x2,…,xn)是一个具有 n n n个变量的函数。 y y y关于第 i i i个参数 x i x_i xi的偏导数(partial derivative)为:
∂ y ∂ x i = lim h → 0 f ( x 1 , … , x i − 1 , x i + h , x i + 1 , … , x n ) − f ( x 1 , … , x i , … , x n ) h . \frac{\partial y}{\partial x_i} = \lim_{h \rightarrow 0} \frac{f(x_1, \ldots, x_{i-1}, x_i+h, x_{i+1}, \ldots, x_n) - f(x_1, \ldots, x_i, \ldots, x_n)}{h}. ∂xi∂y=h→0limhf(x1,…,xi−1,xi+h,xi+1,…,xn)−f(x1,…,xi,…,xn).
为了计算 ∂ y ∂ x i \frac{\partial y}{\partial x_i} ∂xi∂y,我们可以简单地将 x 1 , … , x i − 1 , x i + 1 , … , x n x_1, \ldots, x_{i-1}, x_{i+1}, \ldots, x_n x1,…,xi−1,xi+1,…,xn看作常数,并计算 y y y关于 x i x_i xi的导数。对于偏导数的表示,以下是等价的:
∂ y ∂ x i = ∂ f ∂ x i = f x i = f i = D i f = D x i f . \frac{\partial y}{\partial x_i} = \frac{\partial f}{\partial x_i} = f_{x_i} = f_i = D_i f = D_{x_i} f. ∂xi∂y=∂xi∂f=fxi=fi=Dif=Dxif.
梯度
我们可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。具体而言,设函数 f : R n → R f:\mathbb{R}^n\rightarrow\mathbb{R} f:Rn→R的输入是一个 n n n维向量 x = [ x 1 , x 2 , … , x n ] ⊤ \mathbf{x}=[x_1,x_2,\ldots,x_n]^\top x=[x1,x2,…,xn]⊤,并且输出是一个标量。函数 f ( x ) f(\mathbf{x}) f(x)相对于 x \mathbf{x} x的梯度是一个包含 n n n个偏导数的向量:
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x n ] ⊤ \nabla_{\mathbf{x}} f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_n}\bigg]^\top ∇xf(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x)]⊤
其中 ∇ x f ( x ) \nabla_{\mathbf{x}} f(\mathbf{x}) ∇xf(x)通常在没有歧义时被 ∇ f ( x ) \nabla f(\mathbf{x}) ∇f(x)取代。
假设 x \mathbf{x} x为 n n n维向量,在微分多元函数时经常使用以下规则:
- 对于所有 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n,都有 ∇ x A x = A ⊤ \nabla_{\mathbf{x}} \mathbf{A} \mathbf{x} = \mathbf{A}^\top ∇xAx=A⊤
- 对于所有 A ∈ R n × m \mathbf{A} \in \mathbb{R}^{n \times m} A∈Rn×m,都有 ∇ x x ⊤ A = A \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} = \mathbf{A} ∇xx⊤A=A
- 对于所有 A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A∈Rn×n,都有 ∇ x x ⊤ A x = ( A + A ⊤ ) x \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} \mathbf{x} = (\mathbf{A} + \mathbf{A}^\top)\mathbf{x} ∇xx⊤Ax=(A+A⊤)x
- ∇ x ∥ x ∥ 2 = ∇ x x ⊤ x = 2 x \nabla_{\mathbf{x}} \|\mathbf{x} \|^2 = \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{x} = 2\mathbf{x} ∇x∥x∥2=∇xx⊤x=2x
同样,对于任何矩阵 X \mathbf{X} X,都有 ∇ X ∥ X ∥ F 2 = 2 X \nabla_{\mathbf{X}} \|\mathbf{X} \|_F^2 = 2\mathbf{X} ∇X∥X∥F2=2X。正如我们之后将看到的,梯度对于设计深度学习中的优化算法有很大用处。
链式法则
然而,上面方法可能很难找到梯度。这是因为在深度学习中,多元函数通常是复合(composite)的,所以我们可能没法应用上述任何规则来微分这些函数。幸运的是,链式法则使我们能够微分复合函数。
让我们先考虑单变量函数。假设函数 y = f ( u ) y=f(u) y=f(u)和 u = g ( x ) u=g(x) u=g(x)都是可微的,根据链式法则:
d y d x = d y d u d u d x . \frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}. dxdy=dudydxdu.
现在让我们把注意力转向一个更一般的场景,即函数具有任意数量的变量的情况。假设可微分函数 y y y有变量 u 1 , u 2 , … , u m u_1, u_2, \ldots, u_m u1,u2,…,um,其中每个可微分函数 u i u_i ui都有变量 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn。注意, y y y是 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn的函数。对于任意 i = 1 , 2 , … , n i = 1, 2, \ldots, n i=1,2,…,n,链式法则给出:
d y d x i = d y d u 1 d u 1 d x i + d y d u 2 d u 2 d x i + ⋯ + d y d u m d u m d x i \frac{dy}{dx_i} = \frac{dy}{du_1} \frac{du_1}{dx_i} + \frac{dy}{du_2} \frac{du_2}{dx_i} + \cdots + \frac{dy}{du_m} \frac{du_m}{dx_i} dxidy=du1dydxidu1+du2dydxidu2+⋯+dumdydxidum
梯度下降
梯度下降很少直接用于深度学习中,但它是很多算法(如随机梯度下降)的基础。
数学定义
梯度下降的数学公式:
θ n + 1 = θ n − η ⋅ ∇ J ( θ ) (1) \theta_{n+1} = \theta_{n} - \eta \cdot \nabla J(\theta) \tag{1} θn+1=θn−η⋅∇J(θ)(1)
其中:
- θ n + 1 \theta_{n+1} θn+1:下一个值;
- θ n \theta_n θn:当前值;
- − - −:减号,梯度的反向;
- η \eta η:学习率或步长,控制每一步走的距离,不要太快以免错过了最佳景点,不要太慢以免时间太长;
- ∇ \nabla ∇:梯度,函数当前位置的最快上升点;
- J ( θ ) J(\theta) J(θ):函数。
梯度下降的三要素
- 当前点;
- 方向;
- 步长。
为什么说是“梯度下降”?
“梯度下降”包含了两层含义:
- 梯度:函数当前位置的最快上升点;
- 下降:与导数相反的方向,用数学语言描述就是那个减号。
亦即与上升相反的方向运动,就是下降。
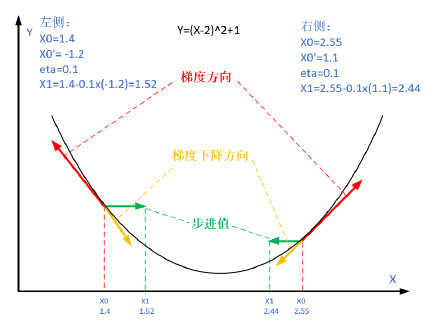
一维梯度下降
为什么梯度下降算法可以优化目标函数?一维中的梯度下降给我们很好的启发。考虑一类连续可微实值函数 f : R → R f: \mathbb{R} \rightarrow \mathbb{R} f:R→R,利用泰勒展开,我们可以得到
f ( x + ϵ ) = f ( x ) + ϵ f ′ ( x ) + O ( ϵ 2 ) . f(x + \epsilon) = f(x) + \epsilon f'(x) + \mathcal{O}(\epsilon^2). f(x+ϵ)=f(x)+ϵf′(x)+O(ϵ2).
注:二阶段泰勒展开
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ( x − x 0 ) 2 + O ( ∣ x − x 0 ∣ 3 ) . f(x) = f(x_{0}) + f'(x_{0})(x-x_{0}) + \frac{f''(x_{0})}{2}(x-x_{0})^2 + O(|x-x_{0}|^3). f(x)=f(x0)+f′(x0)(x−x0)+2f′′(x0)(x−x0)2+O(∣x−x0∣3).
即在一阶近似中, f ( x + ϵ ) f(x+\epsilon) f(x+ϵ)可通过 x x x处的函数值 f ( x ) f(x) f(x)和一阶导数 f ′ ( x ) f'(x) f′(x)得出。我们可以假设在负梯度方向上移动的 ϵ \epsilon ϵ会减少 f f f。为了简单起见,我们选择固定步长 η > 0 \eta > 0 η>0,然后取 ϵ = − η f ′ ( x ) \epsilon = -\eta f'(x) ϵ=−ηf′(x)。将其代入泰勒展开式我们可以得到
f ( x − η f ′ ( x ) ) = f ( x ) − η f ′ 2 ( x ) + O ( η 2 f ′ 2 ( x ) ) . f(x - \eta f'(x)) = f(x) - \eta f'^2(x) + \mathcal{O}(\eta^2 f'^2(x)). f(x−ηf′(x))=f(x)−ηf′2(x)+O(η2f′2(x)).
如果其导数 f ′ ( x ) ≠ 0 f'(x) \neq 0 f′(x)=0没有消失,我们就能继续展开,这是因为 η f ′ 2 ( x ) > 0 \eta f'^2(x)>0 ηf′2(x)>0。此外,我们总是可以令 η \eta η小到足以使高阶项变得不相关。因此,
f ( x − η f ′ ( x ) ) ⪅ f ( x ) . f(x - \eta f'(x)) \lessapprox f(x). f(x−ηf′(x))⪅f(x).
这意味着,如果我们使用
x ← x − η f ′ ( x ) x \leftarrow x - \eta f'(x) x←x−ηf′(x)
来迭代 x x x,函数 f ( x ) f(x) f(x)的值可能会下降。因此,在梯度下降中,我们首先选择初始值 x x x和常数 η > 0 \eta > 0 η>0,然后使用它们连续迭代 x x x,直到停止条件达成。例如,当梯度 ∣ f ′ ( x ) ∣ |f'(x)| ∣f′(x)∣的幅度足够小或迭代次数达到某个值时。
学习率
学习率(learning rate)决定目标函数能否收敛到局部最小值,以及何时收敛到最小值。学习率 η \eta η可由算法设计者设置。请注意,如果我们使用的学习率太小,将导致 x x x的更新非常缓慢,需要更多的迭代。
相反,如果我们使用过高的学习率, ∣ η f ′ ( x ) ∣ \left|\eta f'(x)\right| ∣ηf′(x)∣对于一阶泰勒展开式可能太大。也就是说, O ( η 2 f ′ 2 ( x ) ) \mathcal{O}(\eta^2 f'^2(x)) O(η2f′2(x))可能变得显著了。在这种情况下, x x x的迭代不能保证降低 f ( x ) f(x) f(x)的值。
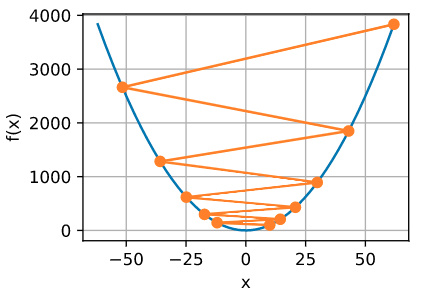
局部最小
为了演示非凸函数的梯度下降,考虑函数 f ( x ) = x ⋅ cos ( c x ) f(x) = x \cdot \cos(cx) f(x)=x⋅cos(cx),其中 c c c为某常数。这个函数有无穷多个局部最小值。根据我们选择的学习率,我们最终可能只会得到许多解的一个。下面的例子说明了(不切实际的)高学习率如何导致较差的局部最小值。
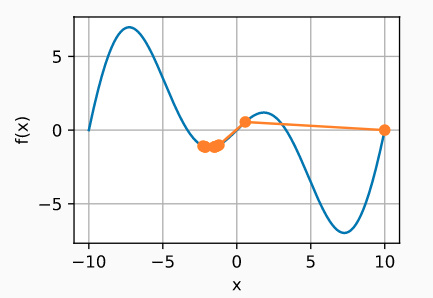
多元梯度下降
现在我们对单变量的情况有了更好的理解,让我们考虑一下 x = [ x 1 , x 2 , … , x d ] ⊤ \mathbf{x} = [x_1, x_2, \ldots, x_d]^\top x=[x1,x2,…,xd]⊤的情况。即目标函数 f : R d → R f: \mathbb{R}^d \to \mathbb{R} f:Rd→R将向量映射成标量。相应地,它的梯度也是多元的:它是一个由 d d d个偏导数组成的向量:
∇ f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x d ] ⊤ . \nabla f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_d}\bigg]^\top. ∇f(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xd∂f(x)]⊤.
梯度中的每个偏导数元素 ∂ f ( x ) / ∂ x i \partial f(\mathbf{x})/\partial x_i ∂f(x)/∂xi代表了当输入 x i x_i xi时 f f f在 x \mathbf{x} x处的变化率。和先前单变量的情况一样,我们可以对多变量函数使用相应的泰勒近似来思考。具体来说,
f ( x + ϵ ) = f ( x ) + ϵ ⊤ ∇ f ( x ) + O ( ∥ ϵ ∥ 2 ) . f(\mathbf{x} + \boldsymbol{\epsilon}) = f(\mathbf{x}) + \mathbf{\boldsymbol{\epsilon}}^\top \nabla f(\mathbf{x}) + \mathcal{O}(\|\boldsymbol{\epsilon}\|^2). f(x+ϵ)=f(x)+ϵ⊤∇f(x)+O(∥ϵ∥2).
换句话说,在
ϵ
\boldsymbol{\epsilon}
ϵ的二阶项中,最陡下降的方向由负梯度
−
∇
f
(
x
)
-\nabla f(\mathbf{x})
−∇f(x)得出。
选择合适的学习率
η
>
0
\eta > 0
η>0来生成典型的梯度下降算法:
x ← x − η ∇ f ( x ) . \mathbf{x} \leftarrow \mathbf{x} - \eta \nabla f(\mathbf{x}). x←x−η∇f(x).
总结
梯度下降是深度学习中基础的理论,希望整理的资料能对梯度下降有一个整体的认识。

















 2175
2175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









