









 本文介绍了正则表达式的应用,包括基本和扩展类型,如元字符、匹配次数等。接着讲解了sed工具的常见选项、操作及实际应用场景,如删除、替换文本。最后探讨了awk的内建变量和使用方法,如输出特定列信息。
本文介绍了正则表达式的应用,包括基本和扩展类型,如元字符、匹配次数等。接着讲解了sed工具的常见选项、操作及实际应用场景,如删除、替换文本。最后探讨了awk的内建变量和使用方法,如输出特定列信息。
一、 基本正则表达式
元字符类型:
^:匹配字符串开始内容
$:匹配字符串结束内容
. :匹配任意字符
* :匹配前面的字符0次或多次
[ ] :匹配括号里任意一个
[^ ] : 匹配未包含括号里面的字符
[n1-n2]:字符范围
{n} :匹配前面字符n次
{n,} :匹配前面字符最少n次
{n,m} : 匹配前面字符最少n次,最大m次
\:字符转义
基本正则表达式应用
- 查询以the开始的行

- 查询包含o的行(后面两个任意字符)
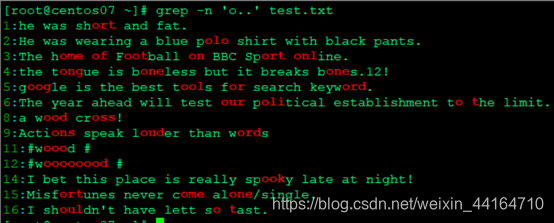
- 匹配至少有两个o的行
- 匹配[ ]中任意字符的行

- 匹配不包含[ ]中的字符加^
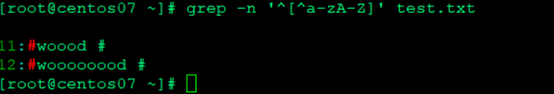
- 匹配以小写字母开始的行

- 匹配包含两个o的行
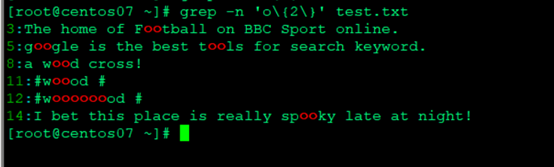
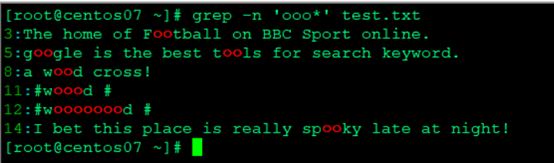
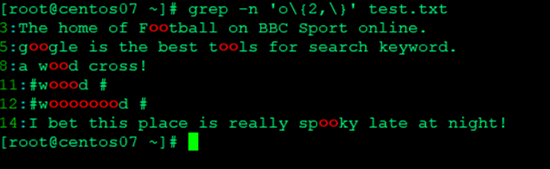
- 包含两个或多个o的行
扩展正则表达式
+:重复上一个字符多次或一次
?:零个或一个前面的字符
| :或者
():组字符串
():辨别多个重复的组
扩展正则表达式应用(使用egrep进行查看)
- 查询包含一个或多个o的行
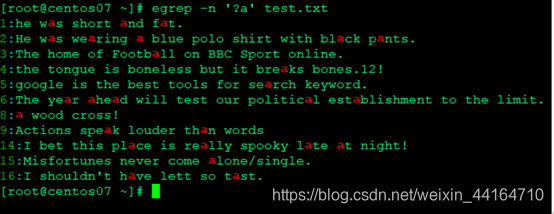
- 匹配前面任意字符
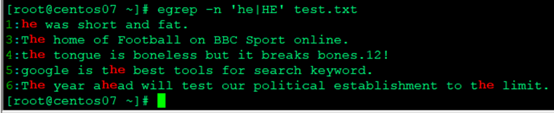
- 查询包含he或者HE的行
- 查询组应用匹配组中任意一个

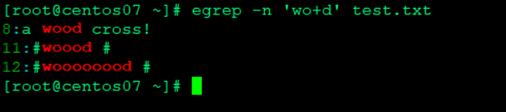
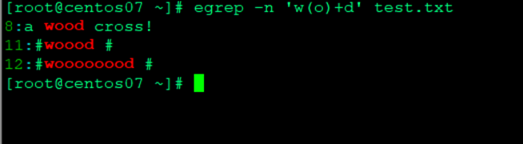
- 匹配包含o或者多个o以w开始d结束的行
二、 使用sed工具
1. 常见的选项
-e 用命令或脚本来处理输入的文本
-f 用指定的脚本文件来处理输入的文本文件
-h 帮助
-n 表示显示处理后结果
-i 直接编辑文本文件
2. 常见的操作
a :增加,在当前行的下面增加一行指定内容
c :替换,选定行替换为指定内容
d :删除,删除原定行
i :插入,在选定行上面插入一行指定内容
p :打印信息
s :替换,替换指定字符
y :字符转义
3. Sed的应用
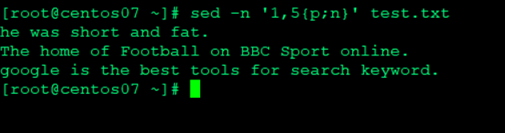
查询1到5之间的奇数行
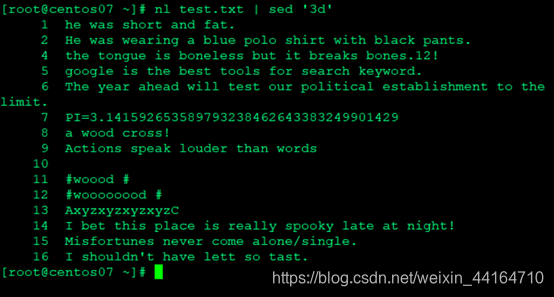
删除第3行内容
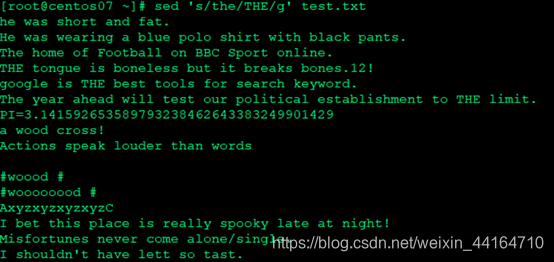
替换文件中所有the为THE
三、 awk的应用
1. awk的内建变量
FS :指定每行文本的字段分隔符
NF :当前处理的行的字段个数
NR :当前处理的行的行号
$0 :当前处理的整行内容
$n : 当前处理的行(n第几列)
FILENAME :被处理的文件名
RS :数据记录分割
2. awk的使用
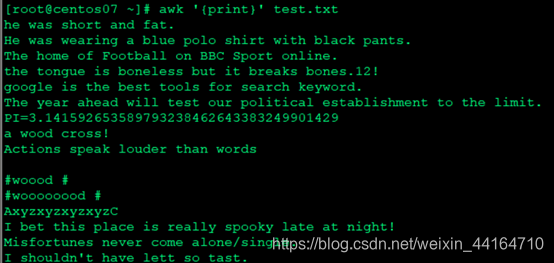
输出文本内容
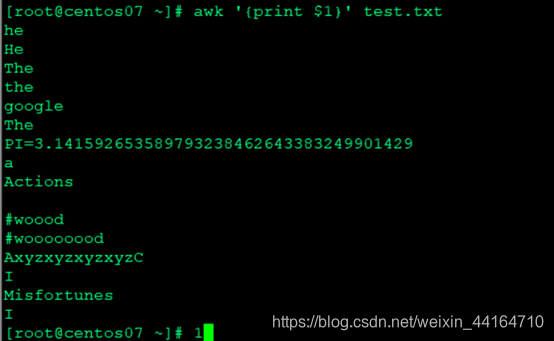
输出第一列内容
查看第一行和第二行

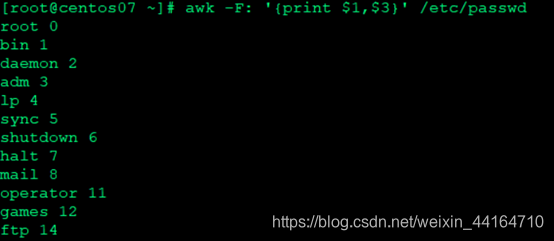
查看第1列和第3列信息以:为分隔符(F表示以什么分隔)

















 2199
2199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









