







论文笔记:STAR: Secret Sharing for Private Threshold Aggregation Reporting
论文介绍
STAR: Secret Sharing for Private Threshold Aggregation Reporting 是CCS信息安全顶会2022的论文

解决问题
阈值聚合报告系统为开发人员提供了一个实用的、保护隐私的解决方案,让他们了解如何“in-wild”使用他们的应用程序,简单来说就是做一个隐私保护条件下的数据收集。
迄今为止,所提出的系统被证明不适合大规模采用,因为需要:
1.禁止性的信任假设。
2.计算成本高。
3.庞大的用户基础。因此,采用真正私人的方法仅限于少数规模巨大(成本极高)的项目。
在这项工作中,我们通过提出STAR来改善私人数据收集的状态,STAR是一个高效、易于部署的系统,用于提供加密强制执行对k-用户数据收集的匿名保护。
STAR协议易于实现,运行成本低廉,同时提供了类似或超过当前技术水平的隐私“资产”。对我们开源STAR实现的测量发现,它比现有的最先进技术快1773倍,所需通信量减少62.4倍,运行成本低24倍。

图5:STAR与先前工作的粗粒度比较。我们使用λ表示安全参数,n= |C|表示客户端的数量,k是聚合消息的门限阈值,以及m表示在多服务器设置中使用的服务器的数量。
对比最近的方案Boneh:它不允许携带辅助数据,带宽要求小nλ < mnλ
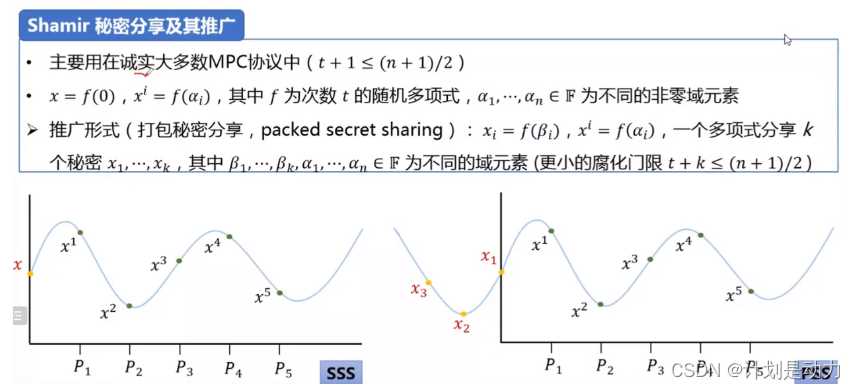
核心方法(Shamir)
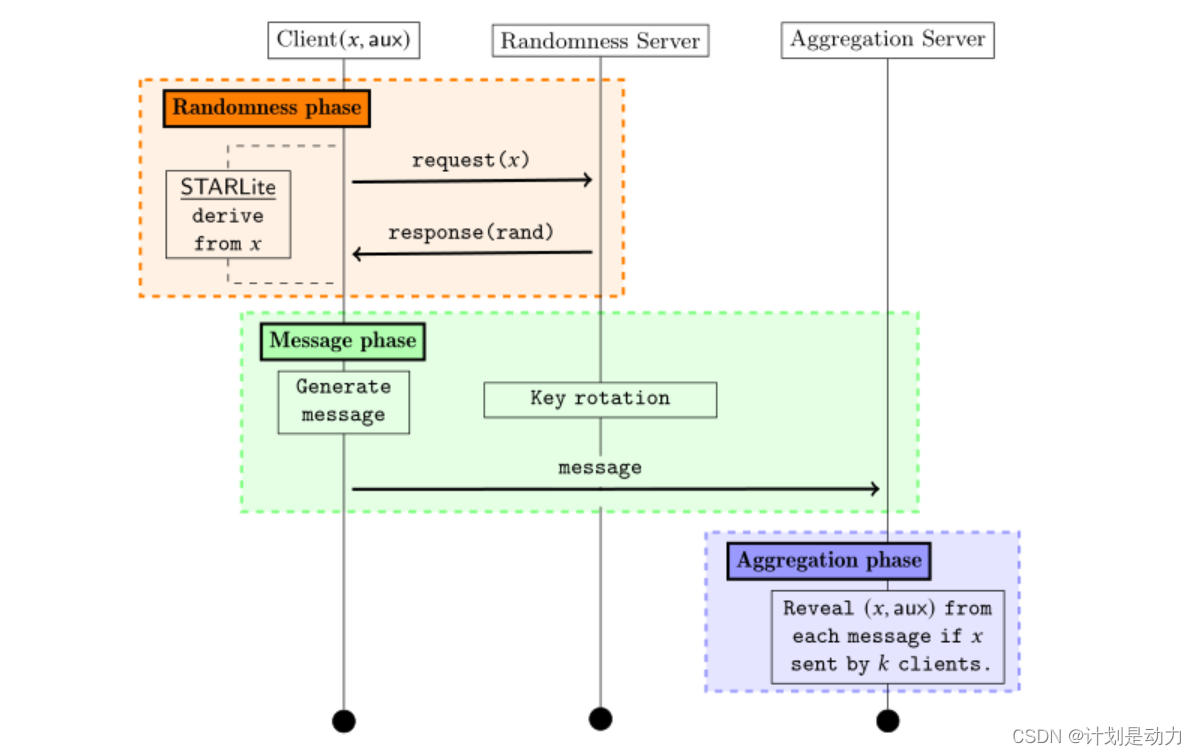
通用STAR架构。在随机性阶段,客户端从专用服务器中采样随机性。在消息阶段,客户端生成要发送到聚合服务器的消息。聚合服务器获取由客户端ui的聚合信息。
STAR:用于私有阈值聚合报告的秘密共享
(1)
假设
k
−
o
u
t
−
o
f
−
n
门限秘密共享方案
Π
k
,
n
运行在算数电路有限域
F
p
(
p
为>
0
的素数
)
假设k-out-of-n门限秘密共享方案\Pi_{k,n} \\运行在算数电路有限域F_p(p为>0的素数)
假设k−out−of−n门限秘密共享方案Πk,n运行在算数电路有限域Fp(p为>0的素数)
s ← Π k , n s h a r e ( z ; r ) :一种产生随机数的概率算法 k − o u t − o f − n s h a r e s ∈ F q o f z s \leftarrow \Pi_{k,n}share(z;r):一种产生随机数的概率算法 \\ k-out-of-n \ \ share \ \ s \in \mathbb F_q \ \ of \ \ z s←Πk,nshare(z;r):一种产生随机数的概率算法k−out−of−n share s∈Fq of z
(2)
(
z
−
,
⊥
)
←
Π
k
,
n
.
r
e
c
o
v
e
r
(
{
s
i
}
i
∈
[
l
]
)
输出
z
−
,当
l
≥
k
且
∀
s
i
∈
s
是一个合理的
z
−
的共享秘钥,否则输出⊥
(\overset{-}z,⊥)←\Pi_{k,n}.recover(\{s_i\}_{i\in[l]}) \\输出 \overset{-}z,当l ≥ k 且\forall s_i \in s 是一个合理的\overset{-}z的共享秘钥,否则输出⊥
(z−,⊥)←Πk,n.recover({si}i∈[l])输出z−,当l≥k且∀si∈s是一个合理的z−的共享秘钥,否则输出⊥
为了安全起见,我们要求任何小于k的秘密共享与一组随机字符串无法区分,是基于传统Shamir秘密共享的秘密共享方法实现的
注意
请注意,共享算法保持概率性,并在构建单个共享时对内部随机性进行采样。 在 S h a m i r 秘密共享语言中,显式随机性输入 r 用于导出 k − 1 次多项式和 P 然后通过对随机值进行抽样来得出值 c ∈ F p 和价值评估 P ( c ) 请注意,共享算法保持概率性,并在构建单个共享时对内部随机性进行采样。 \\在Shamir秘密共享语言中,显式随机性输入r 用于导出k − 1次多项式和P\\ 然后通过对随机值进行抽样来得出值c ∈ \mathbb F_p 和价值评估P(c) 请注意,共享算法保持概率性,并在构建单个共享时对内部随机性进行采样。在Shamir秘密共享语言中,显式随机性输入r用于导出k−1次多项式和P然后通过对随机值进行抽样来得出值c∈Fp和价值评估P(c)
我们要求 p 足够大,可以从 F q 中采样并极不可能导致碰撞 但 p 的大小与安全性没有影响 我们要求p足够大,可以从\mathbb F_q 中采样并极不可能导致碰撞 \\但p的大小与安全性没有影响 我们要求p足够大,可以从Fq中采样并极不可能导致碰撞但p的大小与安全性没有影响
平面有
(
x
0
,
y
0
)
,
.
.
.
,
(
x
n
,
y
n
)
共
n
个点
,
过这些点的多项式
p
k
(
x
)
设集合
D
n
=
{
x
0
,
x
1
,
.
.
,
x
n
−
1
}
,
集合
B
k
=
{
i
∣
i
≠
k
,
i
∈
D
n
}
满足
p
k
(
x
)
=
Π
i
∈
B
k
x
−
x
i
x
k
−
x
i
p
k
(
x
)
是
n
−
1
次多项式,满足
∀
m
∈
B
k
,
P
k
(
m
)
=
0
根据拉格朗日差值
L
n
(
x
)
=
∑
j
=
0
n
−
1
y
j
p
j
(
x
)
例如
f
(
x
)
=
(
x
−
x
1
)
(
x
−
x
2
)
(
x
−
x
3
)
(
x
0
−
x
1
)
(
x
0
−
x
2
)
(
x
0
−
x
3
)
y
0
+
(
x
−
x
0
)
(
x
−
x
2
)
(
x
−
x
3
)
(
x
1
−
x
0
)
(
x
1
−
x
2
)
(
x
1
−
x
3
)
y
1
+
(
x
−
x
0
)
(
x
−
x
1
)
(
x
−
x
3
)
(
x
2
−
x
0
)
(
x
2
−
x
1
)
(
x
2
−
x
3
)
y
2
+
(
x
−
x
0
)
(
x
−
x
1
)
(
x
−
x
2
)
(
x
3
−
x
0
)
(
x
3
−
x
1
)
(
x
3
−
x
2
)
y
3
(
n
=
4
的情况
)
平面有(x_0,y_0),...,(x_n,y_n)共n个点,过这些点的多项式p_k(x) \\设集合D_n = \{x_0,x_1,..,x_{n-1}\},集合B_k=\{i|i≠k,i\in \ D_n\} \\满足p_k(x)=\Pi_{i\in B_k}\frac{x-x_i}{x_k-x_i} \\p_k(x)是n-1次多项式,满足\forall m\in B_k,P_k(m)=0 \\根据拉格朗日差值L_n(x)=\sum_{j=0}^{n-1}y_jp_j(x) \\例如f(x)=\frac{(x-x_1)(x-x_2)(x-x_3)}{(x_0-x_1)(x_0-x_2)(x_0-x_3)}y_0+\frac{(x-x_0)(x-x_2)(x-x_3)}{(x_1-x_0)(x_1-x_2)(x_1-x_3)}y_1+\\\frac{(x-x_0)(x-x_1)(x-x_3)}{(x_2-x_0)(x_2-x_1)(x_2-x_3)}y_2+\frac{(x-x_0)(x-x_1)(x-x_2)}{(x_3-x_0)(x_3-x_1)(x_3-x_2)}y_3(n=4的情况)
平面有(x0,y0),...,(xn,yn)共n个点,过这些点的多项式pk(x)设集合Dn={x0,x1,..,xn−1},集合Bk={i∣i=k,i∈ Dn}满足pk(x)=Πi∈Bkxk−xix−xipk(x)是n−1次多项式,满足∀m∈Bk,Pk(m)=0根据拉格朗日差值Ln(x)=j=0∑n−1yjpj(x)例如f(x)=(x0−x1)(x0−x2)(x0−x3)(x−x1)(x−x2)(x−x3)y0+(x1−x0)(x1−x2)(x1−x3)(x−x0)(x−x2)(x−x3)y1+(x2−x0)(x2−x1)(x2−x3)(x−x0)(x−x1)(x−x3)y2+(x3−x0)(x3−x1)(x3−x2)(x−x0)(x−x1)(x−x2)y3(n=4的情况)
可能存在的问题:m of n 阈值签名
- 密钥分发者知晓完整的密钥,有作恶的可能,例如对部分秘密持有者发放错误的分片数据
- 密钥分片的持有者可能提供非真实的分片数据
- 当考虑存在不诚实参与方时,对于一个秘密需要有相应的算法来验证其确实是秘密的有效片段
秘密分发阶段计算承诺:
a
(
x
)
=
a
0
+
a
1
x
+
.
.
+
a
k
−
1
x
k
−
1
a(x) = a_0+a_1x+..+a_{k-1}x^{k-1}
a(x)=a0+a1x+..+ak−1xk−1
c 0 = g a 0 , c 1 = g a 1 , . . . , c k − 1 = g a k − 1 以上运算在 m o d p 基础上 c_0=g^{a_0},c_1=g^{a_1},...,c_{k-1}=g^{a_{k-1}} \\以上运算在mod \ p基础上 c0=ga0,c1=ga1,...,ck−1=gak−1以上运算在mod p基础上
承诺和秘钥(s=a0)一同发放给参与者p,对第i个参与者校验
g
s
i
=
Π
j
=
0
k
−
1
(
c
j
)
i
j
m
o
d
p
g^{s_i} = \Pi_{j=0}^{k-1}(c_j)^{i^j} mod \ p
gsi=Πj=0k−1(cj)ijmod p
证明:
取
i
=
2
Π
j
=
0
k
−
1
(
c
j
)
i
j
m
o
d
p
=
(
g
a
0
)
2
0
⋅
(
g
a
1
)
2
1
⋅
.
.
.
⋅
(
g
a
k
−
1
)
2
k
−
1
=
g
a
0
+
2
a
1
+
2
2
a
2
+
.
.
.
+
2
k
−
1
a
k
−
1
=
g
a
0
(
模
p
的循环群
)
取i=2\\ \Pi_{j=0}^{k-1}(c_j)^{i^j} mod \ p=(g^{a_0})^{2^0}·(g^{a_1})^{2^1}·...·(g^{a_{k-1}})^{2^{k-1}}=\\g^{a_0+2a_1+2^2a_2+...+2^{k-1}a_{k-1}} =g^{a_0} \\(模p的循环群)
取i=2Πj=0k−1(cj)ijmod p=(ga0)20⋅(ga1)21⋅...⋅(gak−1)2k−1=ga0+2a1+22a2+...+2k−1ak−1=ga0(模p的循环群)
由于承诺绑定了系数,如果分发者给出承诺不是用多项式方程真实系数,会导致验证失败。
秘密重构阶段:
当一个参与者提供他保存的分片数据(ci和si)时,其他参与者会做同样的验证,这样可以保证参与者在恢复阶段的诚实行为。
多点验证的话可以采用基于pairing曲线构建的kate承诺。
Benaloh 的可验证密明共享方案也是建立在 Shamir 的密朗共享方案基础上的。与 Feldman 的方案不同,Benaloh 的方案是无条件安全的。Feldman的安全是建立在离散对数困难的基础上的。
在的密钥共享方案中,所有的参与者的子密钥都是来自一个 k - 1 次的线性多项式,如果密钥分发者分发出一个或者多个错误的子密钥,那么这些 n 个子密钥必然会不一致,它们的插值多项式的次数在很大的概率上会大于 k -1。换句话说,如果我们能过在不泄露子密钥信息的前提下得出这些子密明的插值多项式的次数,那么就可以验证出子密朗的有效性。
该方案安全性是建立在攻击者不可能在秘密的生命周期内获取特定阈值(门限)如t个子密钥的前提之下的,但是在秘密的生命周期较长的情况下,这一点难以保证,例如参与者电脑可能受到病毒攻击,或者其他原因没有妥善保管以至于泄露或者遗忘等,如果面对长时间的破坏性攻击,可验证秘密共享方案VSS并没有一直较好的安全性。
动态秘密共享方案-- Amir Herzberg 方案
密钥分片更新协议:
每个时段开始时要进行子秘密更新
进入第
k
时段后,参与者
P
i
持有的子秘密要从
s
i
k
−
1
=
f
k
−
1
(
i
)
更新到
s
i
k
此时秘钥还是
f
k
−
1
(
0
)
=
s
每个时段开始时要进行子秘密更新\\进入第 k 时段后,参与者 P_i 持有的子秘密要从s_i^{k-1}=f^{k-1}(i)更新到s_i^{k} \\此时秘钥还是f^{k-1}(0) = s
每个时段开始时要进行子秘密更新进入第k时段后,参与者Pi持有的子秘密要从sik−1=fk−1(i)更新到sik此时秘钥还是fk−1(0)=s
步骤:
-
参与者 P i 在 Z q 中随机选择 t − 1 个数 记作 a i j ( j = 1 , 2 , . . . , t − 1 ) 多项式: h i k ( x ) = a i 1 x + a i 2 x 2 + . . . + a i t − 1 x t − 1 满足 h i k ( 0 ) = 0 参与者P_i在\Z_q中随机选择t-1个数 \\记作a_{ij}(j=1,2,...,t-1) \\多项式:h_i^{k}(x) = a_{i1}x+a_{i2}x^2+...+a_{it-1}x^{t-1} \\满足h_i^k(0) = 0 参与者Pi在Zq中随机选择t−1个数记作aij(j=1,2,...,t−1)多项式:hik(x)=ai1x+ai2x2+...+ait−1xt−1满足hik(0)=0
-
P i ( i = 1 , 2 , . . . , n ) 计算 δ i j k = h i k ( j ) m o d q P_i(i=1,2,...,n)计算\delta_{ij}^k=h_i^k(j)mod \ q Pi(i=1,2,...,n)计算δijk=hik(j)mod q
并将δ发给其他参与者
- 参与者 P j 计算 s j k ( x ) = s j k − 1 ( x ) + ∑ i = 0 n δ i j 作为新秘钥分片 这样的话,密钥更新后,原始隐藏秘钥的多项式变成 : f k ( x ) = f k − 1 ( x ) + ∑ i = 0 n h i k ( x ) 显然 f k ( 0 ) = f k − 1 ( 0 ) + ∑ i = 0 n h i k ( 0 ) = s 参与者P_j计算s_j^k(x)=s_j^{k-1}(x)+\sum_{i=0}^{n}\delta_{ij}作为新秘钥分片 \\这样的话,密钥更新后,原始隐藏秘钥的多项式变成: \\f^k(x)=f^{k-1}(x)+\sum_{i=0}^{n}h_i^k(x) \\显然f^k(0) = f^{k-1}(0)+\sum_{i=0}^n h_i^k(0)=s 参与者Pj计算sjk(x)=sjk−1(x)+i=0∑nδij作为新秘钥分片这样的话,密钥更新后,原始隐藏秘钥的多项式变成:fk(x)=fk−1(x)+i=0∑nhik(x)显然fk(0)=fk−1(0)+i=0∑nhik(0)=s
更新后,也是符合门限秘密共享的要求,任意大于或等于 t 个参与者即可恢复原始秘密.本质上是 n 个参与者协商了一个常数项为零的 t-1 次多项式
voprf可验证的不经意伪随机函数
我们假设存在由voprf表示的可验证的不经意伪随机函数(VO-PRF)协议。
备注:不经意伪随机函数(OPRF)协议最早由Freedman等人引入。
它们使客户端能够从服务器接收PRF评估,而客户端的输入是保密的,并且不会透露任何关于服务器PRF密钥的信息。
可验证的OPRF(VOPRF),如
Jarecki等人的OPRF,为客户端提供了验证(在零知识的情况下)服务器是否正确评估了PRF的能力。
根据Tyagi等人给出的描述,我们定义了VOPRF,VOPRF,以具有以下算法:
-
p p ← v o p r f . s e t u p ( 1 λ ) : 为 V O P R F 生成公共参数 p p 的服务器端算法 pp \leftarrow voprf.setup(1^\lambda):\\为VOPRF生成公共参数pp的服务器端算法 pp←voprf.setup(1λ):为VOPRF生成公共参数pp的服务器端算法
-
( m s k , m p k ) ← v o p r f . k e y g e n ( p p ) : 服务器端算法,其对与输入参数 p p 兼容的密钥对进行采样 (msk,mpk)\leftarrow voprf.keygen(pp):\\服务器端算法,其对与输入参数pp兼容的密钥对进行采样 (msk,mpk)←voprf.keygen(pp):服务器端算法,其对与输入参数pp兼容的密钥对进行采样
-
( r q , s t ) ← v o p r f . r e q ( x ) : 客户端算法,根据一些初始输入 x ∈ { 0 , 1 } ∗ 生成请求 r q 和状态 s t (rq,st)\leftarrow voprf.req(x): \\客户端算法,根据一些初始输入x\in \{0,1\}^*生成请求rq和状态st\\ (rq,st)←voprf.req(x):客户端算法,根据一些初始输入x∈{0,1}∗生成请求rq和状态st
-
r q ← v o p r f . e v a l ( m s k , r q ) : 一种服务器端算法,使用密钥 m s k 和客户端请求 r q 生成响应 r p rq \leftarrow voprf.eval(msk,rq): \\一种服务器端算法,使用密钥msk和客户端请求rq生成响应rp rq←voprf.eval(msk,rq):一种服务器端算法,使用密钥msk和客户端请求rq生成响应rp
-
y ← v o p r f . f i n a l i z e ( m p k , r p , s t ) : 使用服务器响应 r p 、公钥 m p k 和客户端状态 s t 产生 m s k 上的 P R F 输出和用 r q 编码的输入 x 。 y \leftarrow voprf.finalize(mpk,rp,st):\\使用服务器响应rp、公钥mpk和客户端状态st\\产生msk上的PRF输出和用rq编码的输入x。 y←voprf.finalize(mpk,rp,st):使用服务器响应rp、公钥mpk和客户端状态st产生msk上的PRF输出和用rq编码的输入x。
我们假设VOPRF协议遵循Albrecht等人提出的标准理想功能。基于One-More-Gap -Diffie-Hellman假设,此类VOPRF已被证明是存在的,UC安全模型已证明其安全性.
PRF
简要描述一下 R F : 对于一个函数 F ,其本质是一个映射 将一个输入集合 X → 输出集合 Y 有很多种方式 ( 其总数为 m n , 假设 ∣ X ∣ = m , ∣ Y ∣ = n ) 所谓 R a n d o m 是指从 F = f ∣ f : X → Y 均匀随机的选取一个 f , 对于一个特定的输入 x i ∈ X 得到 f ( x i ) = y ∈ Y 。 简要描述一下RF:对于一个函数\mathcal F,其本质是一个映射 \\将一个输入集合X \to 输出集合Y有很多种方式(其总数为m^n,假设|X|=m,|Y|=n) \\所谓Random是指从\mathcal F = {f|f:X \to Y}均匀随机的选取一个f,对于一个特定的输入x_i \in X得到f(x_i)=y \in Y。 简要描述一下RF:对于一个函数F,其本质是一个映射将一个输入集合X→输出集合Y有很多种方式(其总数为mn,假设∣X∣=m,∣Y∣=n)所谓Random是指从F=f∣f:X→Y均匀随机的选取一个f,对于一个特定的输入xi∈X得到f(xi)=y∈Y。
形式化定义:
f
函数
:
{
0
,
1
}
n
×
{
0
,
1
}
s
→
{
0
,
1
}
m
是一个
(
t
,
ϵ
,
q
)
−
P
R
F
⇔
1.
给一个秘钥
K
∈
{
0
,
1
}
s
和输入
X
∈
{
0
,
1
}
n
,
这里有一个高效算法去计算
:
F
K
(
X
)
=
F
(
X
,
K
)
2.
对任何
t
−
t
i
m
e
的算法,我们有:
∣
P
r
K
←
{
0
,
1
}
s
[
A
f
K
]
−
P
r
f
∈
F
[
A
f
]
∣
<
ϵ
F
=
{
f
:
{
0
,
1
}
n
→
{
0
,
1
}
m
}
且
A
最多执行
q
次查询
f函数:\{0,1\}^n \times \{0,1\}^s \to \{0,1\}^m 是一个(t,\epsilon,q)-PRF \Leftrightarrow \\1.给一个秘钥K \in \{0,1\}^s 和 输入X\in \{0,1\}^n,这里有一个高效算法去计算: \\F_K(X) = F(X,K) \\2.对任何t-time的算法,我们有: \\|Pr_{K\leftarrow \{0,1\}^s}[A^{f_K}]-Pr_{f\in \mathcal F}[A^f]| < \epsilon \\\mathcal F=\{f:\{0,1\}^n \to \{0,1\}^m\} 且 A最多执行q次查询
f函数:{0,1}n×{0,1}s→{0,1}m是一个(t,ϵ,q)−PRF⇔1.给一个秘钥K∈{0,1}s和输入X∈{0,1}n,这里有一个高效算法去计算:FK(X)=F(X,K)2.对任何t−time的算法,我们有:∣PrK←{0,1}s[AfK]−Prf∈F[Af]∣<ϵF={f:{0,1}n→{0,1}m}且A最多执行q次查询

P
R
F
是指现在有一个密钥
k
去选择
F
集合中的第
k
个
f
,
并不是均匀随机选取的
为了保证伪随机性还需准备另一个
f
′
是均匀随机选取的
f
当
P
1
拥有密钥
k
,
P
2
拥有输入
x
i
,
双方执行
P
R
F
协议时
P
2
无法区分
P
R
F
的输出
f
(
x
i
)
是由
P
1
通过自己的密钥
k
选取的
f
k
计算得到的
f
k
(
x
i
)
还是由
f
′
计算得到的
f
′
(
x
i
)
PRF是指现在有一个密钥k去选择F集合中的第k个f,并不是均匀随机选取的\\为了保证伪随机性还需准备另一个f'是均匀随机选取的f \\当P1拥有密钥k,P2拥有输入x_i,双方执行PRF协议时 \\P2无法区分PRF的输出f(x_i)是由P1通过自己的密钥k选取的f_k计算得到的f_k(x_i)还是由f'计算得到的f'(x_i)
PRF是指现在有一个密钥k去选择F集合中的第k个f,并不是均匀随机选取的为了保证伪随机性还需准备另一个f′是均匀随机选取的f当P1拥有密钥k,P2拥有输入xi,双方执行PRF协议时P2无法区分PRF的输出f(xi)是由P1通过自己的密钥k选取的fk计算得到的fk(xi)还是由f′计算得到的f′(xi)

OPRF不经意伪随机函数
简述:理论的角度来看,我们的工作留下的最有趣的开放问题之一是找到一种完全自适应的OPRF和KS(支持任意数量的查询)的有效黑盒构造,它只使用OT的黑盒。
相比之下,通过使用OT的非黑盒,可以容易地获得这样的构造。
因此,我们在密码学中有一个罕见的非黑箱构造的例子,即使在随机预言机模型中,也不知道黑箱构造。
相关论文:Keyword Search and Oblivious Pseudorandom Functions
O
P
R
F
是一个
M
P
C
协议,允许两个参与方对一个
P
R
F
的
F
求值
协议运行前
:
接收者
R
有一系列的输入
q
1
,
q
2
,
.
.
.
,
q
t
运行协议后
:
发送者
S
可以得到一个
P
R
F
(
伪随机函数
)
F
的秘钥
K
接收者获得一系列伪随机函数的计算结果
F
(
K
,
q
1
)
,
F
(
K
,
q
2
)
,
.
.
.
F
(
K
,
q
t
)
同时接受者
S
不知道
R
的输入,
R
也不知道
S
得到的秘钥
K
OPRF是一个MPC协议,允许两个参与方对一个PRF的F求值 \\协议运行前:接收者R有一系列的输入q_1,q_2,...,q_t \\运行协议后: \\发送者S可以得到一个PRF(伪随机函数)F的秘钥K \\接收者获得一系列伪随机函数的计算结果F(K,q_1),F(K,q_2),...F(K,q_t) \\同时接受者S不知道R的输入,R也不知道S得到的秘钥K
OPRF是一个MPC协议,允许两个参与方对一个PRF的F求值协议运行前:接收者R有一系列的输入q1,q2,...,qt运行协议后:发送者S可以得到一个PRF(伪随机函数)F的秘钥K接收者获得一系列伪随机函数的计算结果F(K,q1),F(K,q2),...F(K,qt)同时接受者S不知道R的输入,R也不知道S得到的秘钥K
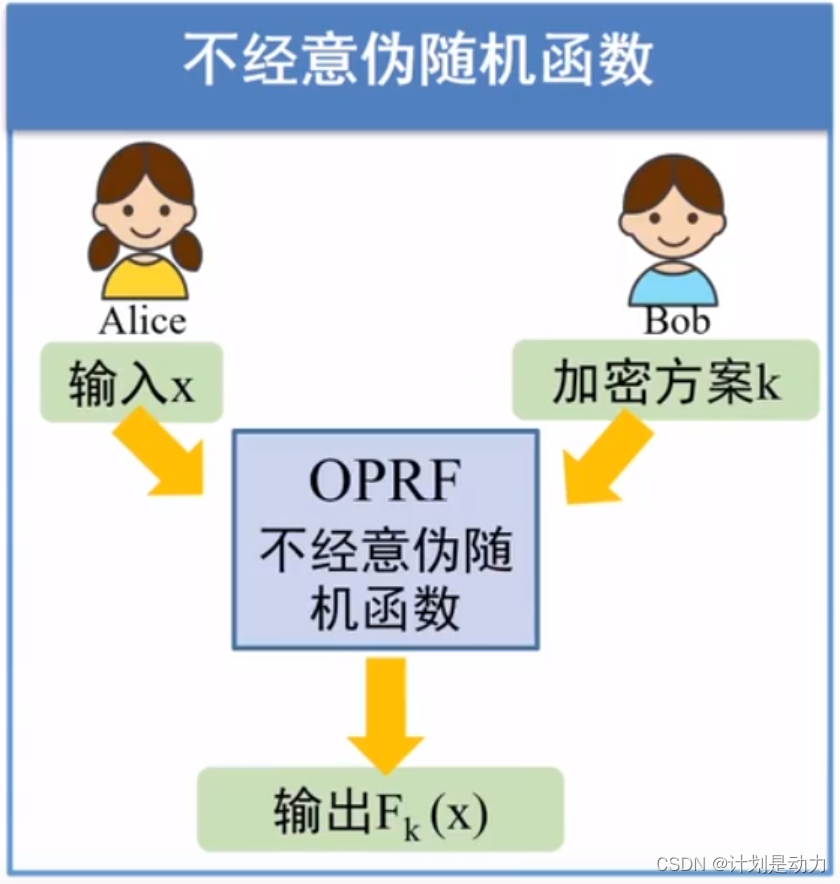
Alice在不知道Bob的加密方案,Bob不知道Alice的输入的情况下输出Fk(x).
不经意伪随机数的具体实现
基于DH实现:
Naor和Reingold基于数论假设给出了PRF的两种构造:其中一种基于决策Diffie-Hellman假设(DH)
DH:基于离散对数困难问题

让 g 是素数阶 p 的群 G g 的生成元,对于该群, D D H 假设成立 伪随机函数 f 的秘钥 r − 在 Z p ∗ 随机均匀采样 r − : { 0 , 1 } m ↦ G g 包含的 m 个值 { r 1 , r 2 , . . . , r m } F k ( x ) = f r − ( x ) = g Π x i = 1 r i , 对于任意比特 x = x 1 x 2 . . . x m H 是一个在 Z p ∗ 上的 h a s h 函数 , 这个 h a s h 也是随机的 ( 在范围 σ = l o g 2 ( N x N y ) + λ b i t ) 采用 C o i n − F l i p p i n g P r o t o c o l 协议 让g是素数阶p的群G_g的生成元,对于该群,DDH假设成立 \\伪随机函数f的秘钥\overset {-}r在\Z_p^*随机均匀采样 \\\overset{-}r:\{0,1\}^m\mapsto G_g包含的m个值\{r_1,r_2,...,r_m\} \\F_k(x)=f_{\overset{-}r}(x) = g^{\Pi_{x_i=1}r_i},对于任意比特 \ x = x_1x_2...x_m \\H是一个在\Z_p^*上的hash函数,这个hash也是随机的 \\(在范围\sigma=log_2(N_xN_y)+\lambda bit) \\采用Coin-Flipping Protocol协议 让g是素数阶p的群Gg的生成元,对于该群,DDH假设成立伪随机函数f的秘钥r−在Zp∗随机均匀采样r−:{0,1}m↦Gg包含的m个值{r1,r2,...,rm}Fk(x)=fr−(x)=gΠxi=1ri,对于任意比特 x=x1x2...xmH是一个在Zp∗上的hash函数,这个hash也是随机的(在范围σ=log2(NxNy)+λbit)采用Coin−FlippingProtocol协议
发送者发送
X
′
=
{
H
(
F
k
(
x
)
)
:
x
∈
X
}
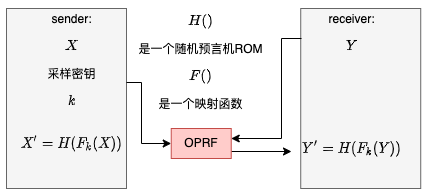
发送者发送X' = \{H(F_k(x)) :x\in X\}
发送者发送X′={H(Fk(x)):x∈X}
接受者使用随机排序集合 Y 作为私有输入 发送者使用 k 作为私有输入 接收方获取 Y ′ = { H ( F k ( y ) ) : y ∈ Y } 接受者使用随机排序集合Y作为私有输入 \\发送者使用k作为私有输入 \\接收方获取Y' = \{H(F_k(y)):y\in Y\} 接受者使用随机排序集合Y作为私有输入发送者使用k作为私有输入接收方获取Y′={H(Fk(y)):y∈Y}
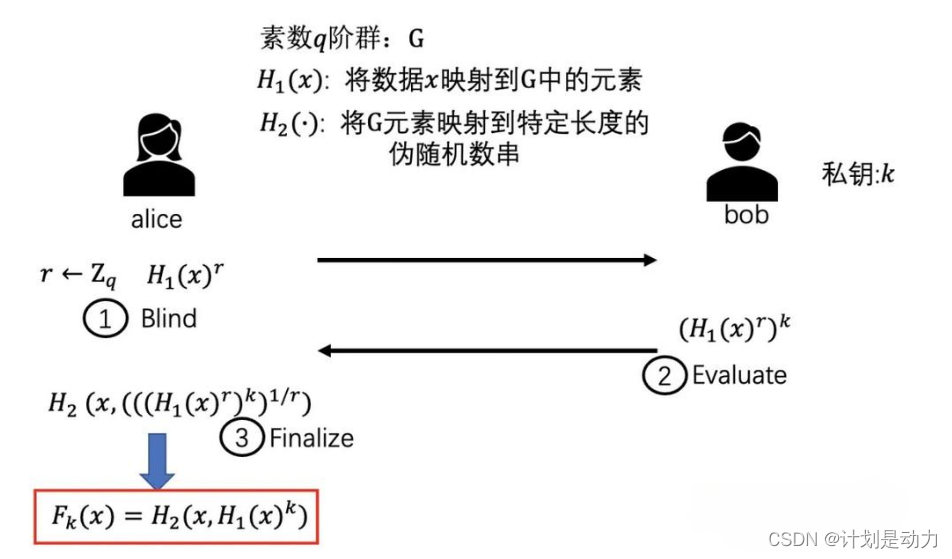

这里有一个基于椭圆曲线实现hash的版本
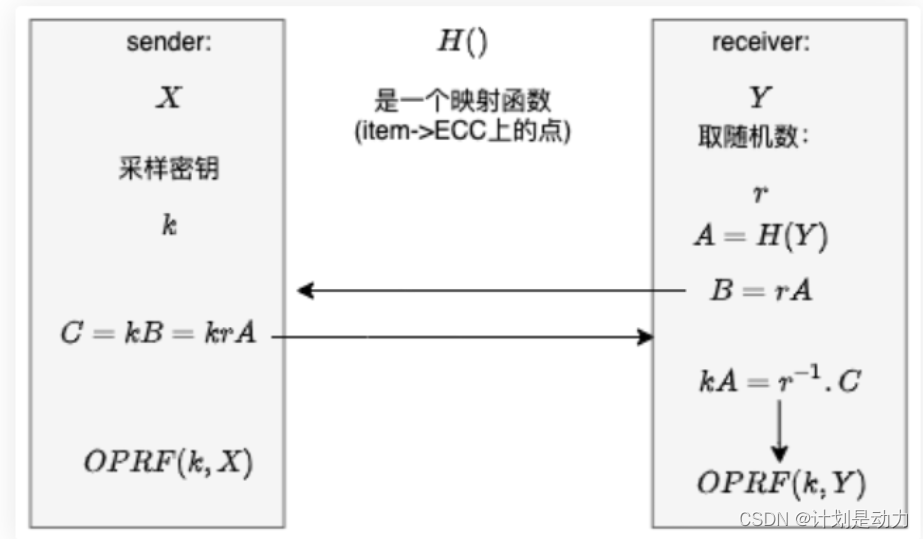
通过OT协议实现的:
参考一下1-n OT协议模型:
发送方
A
持有数据
m
0
和
m
1
,接收方持有比特
b
∈
{
0
,
1
}
则
1
−
n
O
T
可以描述为
:
O
T
(
(
m
0
,
m
1
,
.
.
.
,
m
n
)
,
b
)
=
m
b
其中
B
只知道
m
b
,
不知知道
m
i
∈
{
0
,
1
,
.
.
,
n
}
╲
b
,
而
A
不知道
b
发送方A持有数据m_0和m_1,接收方持有比特b \in \{0,1\}\\ 则1-n \ \ OT可以描述为: \\OT((m_0,m_1,...,m_n),b) = m_b \\其中B只知道m_b,不知知道m_{i\in\{0,1,..,n\}\diagdown b},而A不知道b
发送方A持有数据m0和m1,接收方持有比特b∈{0,1}则1−n OT可以描述为:OT((m0,m1,...,mn),b)=mb其中B只知道mb,不知知道mi∈{0,1,..,n}╲b,而A不知道b
如果将OT作为黑盒,可以得到OPRF
我们现在提出了一种基于一般假设的自适应t时间r-OPRF的新构造,以黑箱方式使用OT和PRF原语。(事实上,正如前面所讨论的,PRF本身就是OT所暗示的黑盒。)

论文里的这个有点抽象
举个例子:在隐私求交的场景,简化一下,设定集合长度就为1,那么这样子就是一个隐私比较
假设
A
持有数据
x
,
B
持有数据
y
我们假设
∣
x
∣
=
∣
y
∣
=
l
(
字节长度
)
假设A持有数据x,B持有数据y \\我们假设|x| = |y| =l (字节长度)
假设A持有数据x,B持有数据y我们假设∣x∣=∣y∣=l(字节长度)
(1)现在A为数据x的每一位都生成两个随机的二进制串(服从均匀分布),长度为n:
即
K
i
,
0
,
K
i
,
1
,
i
=
(
0
,
1
,
.
.
.
,
l
−
1
)
,
∣
K
i
,
0
∣
=
∣
K
i
,
1
∣
=
n
即K_{i,0},K_{i,1},i=(0,1,...,l-1),|K_{i,0}|=|K_{i,1}|=n
即Ki,0,Ki,1,i=(0,1,...,l−1),∣Ki,0∣=∣Ki,1∣=n
(2)现在B作为接收方,A作为发送方,开始执行1-2不经意传输协议
即
B
根据
y
的每一位
y
i
,选择
A
持有的
K
i
,
0
,
K
i
,
1
中的一个
即
O
T
(
(
K
i
,
0
,
K
i
,
1
)
,
y
i
)
=
K
i
,
y
i
,
i
=
(
0
,
1
,
.
.
.
,
l
−
1
)
即B根据y的每一位y_i,选择A持有的K_{i,0},K_{i,1}中的一个 \\即OT((K_{i,0},K_{i,1}),y_i)=K_{i,y_i},i=(0,1,...,l-1)
即B根据y的每一位yi,选择A持有的Ki,0,Ki,1中的一个即OT((Ki,0,Ki,1),yi)=Ki,yi,i=(0,1,...,l−1)
(3)
B
将接收到的
l
个二进制串进行异或
⨁
,得到二进制串
K
y
即
K
y
=
f
r
−
(
y
)
=
⨁
K
i
,
y
i
,
i
=
(
0
,
1
,
.
.
.
,
l
−
1
)
B将接收到的l个二进制串进行异或\bigoplus,得到二进制串K_y \\即K_y = f_{\overset{-}r}(y)=\bigoplus K_{i,y_i},i=(0,1,...,l-1)
B将接收到的l个二进制串进行异或⨁,得到二进制串Ky即Ky=fr−(y)=⨁Ki,yi,i=(0,1,...,l−1)
(4)
发送方
A
也可以跟
B
一样,根据
x
的每一位
x
i
,
选择一个二进制串
K
i
,
x
i
将这
l
个二进制串进行异或,得到一个二进制串
即
K
x
=
f
r
−
(
x
)
=
⨁
K
i
,
x
i
,
i
=
(
0
,
1
,
.
.
.
,
l
−
1
)
发送方A也可以跟B一样,根据x的每一位x_i,选择一个二进制串K_{i,x_i} \\将这l 个二进制串进行异或,得到一个二进制串 \\即K_x =f_{\overset{-}r}(x)= \bigoplus K_{i,x_i},i=(0,1,...,l-1)
发送方A也可以跟B一样,根据x的每一位xi,选择一个二进制串Ki,xi将这l个二进制串进行异或,得到一个二进制串即Kx=fr−(x)=⨁Ki,xi,i=(0,1,...,l−1)
注意这里的A生成Kx的时候不需要使用不经意传输OT,因为x与K都在A的手中
(5)
A
将
K
x
发送给
B
,
B
即可判断
x
与
y
是否相等
A将K_x 发送给B,B即可判断x与y是否相等
A将Kx发送给B,B即可判断x与y是否相等
B 使用不经意传输获得 K y 的过程中,由于不经意传输的特性 A 不会知道 B 的数据 y ; 使用异或得到的 K x 与 K y ,与一个随机的 n 位二进制串是无法区分的 所以 B 也无法通过反推出 x 。 B使用不经意传输获得K_y的过程中,由于不经意传输的特性\\A不会知道B的数据y;\\使用异或得到的K_x与K_y ,与一个随机的n位二进制串是无法区分的\\所以B也无法通过 反推出x。 B使用不经意传输获得Ky的过程中,由于不经意传输的特性A不会知道B的数据y;使用异或得到的Kx与Ky,与一个随机的n位二进制串是无法区分的所以B也无法通过反推出x。
拓展一下:
可以把这个二进制串
K
i
,
0
,
K
i
,
1
,
i
=
(
0
,
1
,
.
.
.
,
l
−
1
)
作为随机种子
K
交给
A
持有
从
B
的角度来看,隐私比较的过程,就是
B
输入数据
y
得到一个随机二进制串
K
y
,这个二进制串由
A
持有的随机种子
K
与输入
y
来决定
同时
A
无法得知
B
的输入
y
。
这一过程,就可以看作是不经意伪随机函数
可以把这个二进制串K_{i,0},K_{i,1},i = (0,1,...,l-1)作为随机种子K \\交给A持有 \\从B的角度来看,隐私比较的过程,就是B输入数据y\\得到一个随机二进制串K_y ,这个二进制串由A持有的随机种子K 与输入y来决定\\同时A无法得知B的输入y。\\这一过程,就可以看作是不经意伪随机函数
可以把这个二进制串Ki,0,Ki,1,i=(0,1,...,l−1)作为随机种子K交给A持有从B的角度来看,隐私比较的过程,就是B输入数据y得到一个随机二进制串Ky,这个二进制串由A持有的随机种子K与输入y来决定同时A无法得知B的输入y。这一过程,就可以看作是不经意伪随机函数
挑战:如果扩展到1-m的OT上

这个时候需要生成l维随机序列
VOPRF伪随机函数
在零知识的情况下验证是否存在OPRF的能力
最小熵
对于一个分布 D ( 输入空间为 X ) D 的最小熵 : m i n x ∈ X ( − l o g 2 ( P r ( [ X = x ] ) ) ) 对于一个分布\mathcal D (输入空间为\mathcal X) \\\mathcal D的最小熵:min_{x\in \mathcal X}(-log_2(Pr([\mathcal X =x]))) 对于一个分布D(输入空间为X)D的最小熵:minx∈X(−log2(Pr([X=x])))
协议安全模型:
我们描述了阈值聚合协议的理想功能,包括输入、输出和潜在信息泄漏。
并使用它来表明在现实世界协议中可能的任何攻击也有可能针对理想世界功能发起。直观地说,这证明了协议除了函数输出所揭示的内容加上特定泄漏函数输出的有界泄漏量之外,什么都没有揭示。
协议安全性
对于协议 P ,理想函数由 F P 表示。 让输入 i n p u t H 和 i n p u t A 分别表示诚实的一方 H 和敌手 A 选择的一组输入 额外,让 R e a l ( P , A ; i n p u t s A , i n p u t s H ) 表示真实协议中敌手 A 的现实世界 让 I d e a l ( F P , S , A ; i n p u t s A , i n p u t s H ) 表示 通过与 F P 交互的 P P T 算法 S 模拟时的 A 的理想世界 我们说 P 是安全的 ⇔ 如果对于所有输入的选择,以下等式成立,则可以防止恶意对手 : R e a l ( P , A ; i n p u t s A , i n p u t s H ) ≃ c I d e a l ( F P , S , A ; i n p u t s A , i n p u t s H ) ≃ c 是指两个范式的概率分布是计算不可区分 对于协议\mathcal P,理想函数由\mathcal F_\mathcal P表示。 \\让输入input_{\mathcal H}和input_{\mathcal A}分别表示诚实的一方\mathcal H和敌手\mathcal A选择的一组输入 \\额外,让Real(\mathcal P,\,\mathcal A; inputs_\mathcal A, inputs_\mathcal H)表示真实协议中敌手A的现实世界 \\让Ideal({\mathcal F}_{\mathcal P},\mathcal S,\mathcal A;inputs_\mathcal A, inputs_\mathcal H)表示\\通过与FP交互的PPT算法\mathcal S模拟时的A的理想世界 \\我们说\mathcal P是安全的\Leftrightarrow\\如果对于所有输入的选择,以下等式成立,则可以防止恶意对手: \\Real(\mathcal P,\,\mathcal A; inputs_\mathcal A, inputs_\mathcal H) \overset{c}\simeq Ideal({\mathcal F}_{\mathcal P},\mathcal S,\mathcal A;inputs_\mathcal A, inputs_\mathcal H) \\\overset{c}\simeq是指两个范式的概率分布是计算不 可区分 对于协议P,理想函数由FP表示。让输入inputH和inputA分别表示诚实的一方H和敌手A选择的一组输入额外,让Real(P,A;inputsA,inputsH)表示真实协议中敌手A的现实世界让Ideal(FP,S,A;inputsA,inputsH)表示通过与FP交互的PPT算法S模拟时的A的理想世界我们说P是安全的⇔如果对于所有输入的选择,以下等式成立,则可以防止恶意对手:Real(P,A;inputsA,inputsH)≃cIdeal(FP,S,A;inputsA,inputsH)≃c是指两个范式的概率分布是计算不可区分
这种安全模型通常被称为在现实/理想世界范式中证明安全
泄露函数
泄漏函数指定了对手在完成模拟所需的协议期间可能学习的附加信息。该信息反映了在协议执行期间发生的实际泄漏。
我们用L表示泄漏函数,该函数将一组输入输入(诚实和对抗)作为输入,并输出一些泄漏L(输入)。
协议实现
协议参数
-
我们使用 P 来指代 S T A R 协议 使用 P ∼ 来指代 S T A R L i t e 我们使用\mathcal P来指代STAR协议\\使用\overset{\sim} {\mathcal P}来指代STARLite 我们使用P来指代STAR协议使用P∼来指代STARLite
-
k 是执行聚合的阈值 k是执行聚合的阈值 k是执行聚合的阈值
-
C 是客户的集合 { C i } i ∈ [ n ] \mathcal C是客户的集合\{\mathbb C_i\}_{i\in[n]} C是客户的集合{Ci}i∈[n]
-
S 表示服务器的聚合 \mathbb S表示服务器的聚合 S表示服务器的聚合
-
O 是 P 中的随机性服务器通用符号 \mathbb O是\mathcal P中的随机性服务器通用符号 O是P中的随机性服务器通用符号
通用符号
-
D 是在 U 客户从中取样测量上的分布 \mathcal D是在\mathcal U客户从中取样测量上的分布 D是在U客户从中取样测量上的分布
-
( c i , s i , t i ) 是由 C i 发出的 m e s s a g e (c_i,s_i,t_i)是由\mathbb C_i发出的message (ci,si,ti)是由Ci发出的message
-
X 是 S 接收到的所有测量值的集合 让 X H ( X A ) 表示从诚实(敌手)客户端接收的测量子集 \mathcal X是\mathbb S接收到的所有测量值的集合 \\让\mathcal X_\mathcal H(\mathcal X_\mathcal A)表示从诚实(敌手)客户端接收的测量子集 X是S接收到的所有测量值的集合让XH(XA)表示从诚实(敌手)客户端接收的测量子集
-
让 E 1 = ( x 1 , a u x x 1 , k 1 ) , . . . , E ℓ = ( x ℓ , a u x x ℓ , k ℓ ) 对应于由客户端发送到 S 的 ℓ 个独特的测量 x i 因此 a u x x i 是与包含测量值 x i 的每条消息相关联的所有辅助数据的集合 k i 是 S 接收到的此类消息的数量 让 \mathcal E_1 = (x_1,aux_{x_1},k_1),...,\mathcal E_ℓ = (x_ℓ,aux_{x_ℓ},k_ℓ)\\对应于由客户端发送到\mathbb S的ℓ个独特的测量x_i \\因此aux_{x_i}是与包含测量值x_i的每条消息相关联的所有辅助数据的集合 \\k_i是\mathbb S接收到的此类消息的数量 让E1=(x1,auxx1,k1),...,Eℓ=(xℓ,auxxℓ,kℓ)对应于由客户端发送到S的ℓ个独特的测量xi因此auxxi是与包含测量值xi的每条消息相关联的所有辅助数据的集合ki是S接收到的此类消息的数量
-
Y 是一个集合包含每一个由 S 输出的 E l ( k l ≥ k ) \mathcal Y是一个集合包含每一个由\mathbb S输出的\mathcal E_l(k_l≥k) Y是一个集合包含每一个由S输出的El(kl≥k)
-
Γ 是一个 V O P R F Γ是一个VOPRF Γ是一个VOPRF
-
( m s k , m p k ) 是一个由 O 对于 Γ 的秘钥对 (msk,mpk)是一个由\mathbb O对于Γ的秘钥对 (msk,mpk)是一个由O对于Γ的秘钥对
-
∑ 是一种满足 I N D − C P A 安全性的对称加密方案 \sum 是一种满足IND-CPA安全性的对称加密方案 ∑是一种满足IND−CPA安全性的对称加密方案
-
Π k , n 是一个 ( k , n ) 的秘钥共享方案,并且让 F q 是一个 p ∈ Z 的有限域 \Pi_{k,n}是一个(k,n)的秘钥共享方案,并且让\mathbb F_q是一个p\in \Z的有限域 Πk,n是一个(k,n)的秘钥共享方案,并且让Fq是一个p∈Z的有限域
-
A 是一个恶意 P P T 敌手 \mathcal A是一个恶意PPT敌手 A是一个恶意PPT敌手
-
S 是一个 P P T 的模拟器 \mathcal S是一个PPT的模拟器 S是一个PPT的模拟器
-
F P 是对应协议 P 相对应的理想函数 L 是协议 P 的泄露函数 \mathcal F_{\mathcal P}是对应协议\mathcal P相对应的理想函数 \\\mathcal L是协议\mathcal P的泄露函数 FP是对应协议P相对应的理想函数L是协议P的泄露函数
-
F Γ 是对应 Γ 的理想函数 \mathcal F_Γ是对应Γ的理想函数 FΓ是对应Γ的理想函数
设计空间
我们假设元素M(例如≥64位的位串)的区间表示客户端发送到单个不可信聚合服务器的潜在测量。
例如,这样的测量可以包括关于用户(例如浏览器用户代理)或安装在设备上的应用程序集的简档信息。客户端可以选择性地发送任意附加数据及其测量值。
每个可用的客户端在历元期间发送单个编码的测量值。聚合服务器应该能够揭示至少接收到的所有编码的测量值(以及任何相关联的数据)k 次。阈值k ≥ 1从一开始就公开同意。
STAR 协议
随机性阶段:STAR
首先,每个客户端与随机性服务器 O 交互,以获取用于其数据 x i 的相关随机值 . 首先,每个客户端与随机性服务器\mathbb O交互,以获取用于其数据x_i的相关随机值. 首先,每个客户端与随机性服务器O交互,以获取用于其数据xi的相关随机值.
本质上,客户端作为 V O P R F 协议中的客户端进行操作,并带有输入 x i , 随机性服务器回答查询并将结果返回给客户端。 请注意,客户端还必须拥有 O 生成的公共参数 p p 和公钥 m p k 。 本质上,客户端作为VOPRF协议中的客户端进行操作,并带有输入x_i,\\随机性服务器回答查询并将结果返回给客户端。\\请注意,客户端还必须拥有\mathbb O生成的公共参数pp和公钥mpk。 本质上,客户端作为VOPRF协议中的客户端进行操作,并带有输入xi,随机性服务器回答查询并将结果返回给客户端。请注意,客户端还必须拥有O生成的公共参数pp和公钥mpk。
客户端,在处理了 V O P R F 输出后接收 r i ∈ { 0 , 1 } 3 w 对于某一个 w > 0 ∈ Z 现在有了结果 ( x i , r i ) . 客户端,在处理了VOPRF输出后接收r_i ∈ \{0, 1\}^{3w} 对于某一个w > 0∈\Z\\现在有了结果(x_i, r_i). 客户端,在处理了VOPRF输出后接收ri∈{0,1}3w对于某一个w>0∈Z现在有了结果(xi,ri).
请注意,任何共享测量的客户 x i 也将接收相同的输出 r i 。 请注意,随机性服务器应定期轮换其 V O P R F 密钥对以提高客户端隐私保证 并且客户端应能够相应地下载新的公钥数据 请注意,任何共享测量的客户x_i 也将接收相同的输出r_i。 \\请注意,随机性服务器应定期轮换其VOPRF密钥对以提高客户端隐私保证\\并且客户端应能够相应地下载新的公钥数据 请注意,任何共享测量的客户xi也将接收相同的输出ri。请注意,随机性服务器应定期轮换其VOPRF密钥对以提高客户端隐私保证并且客户端应能够相应地下载新的公钥数据
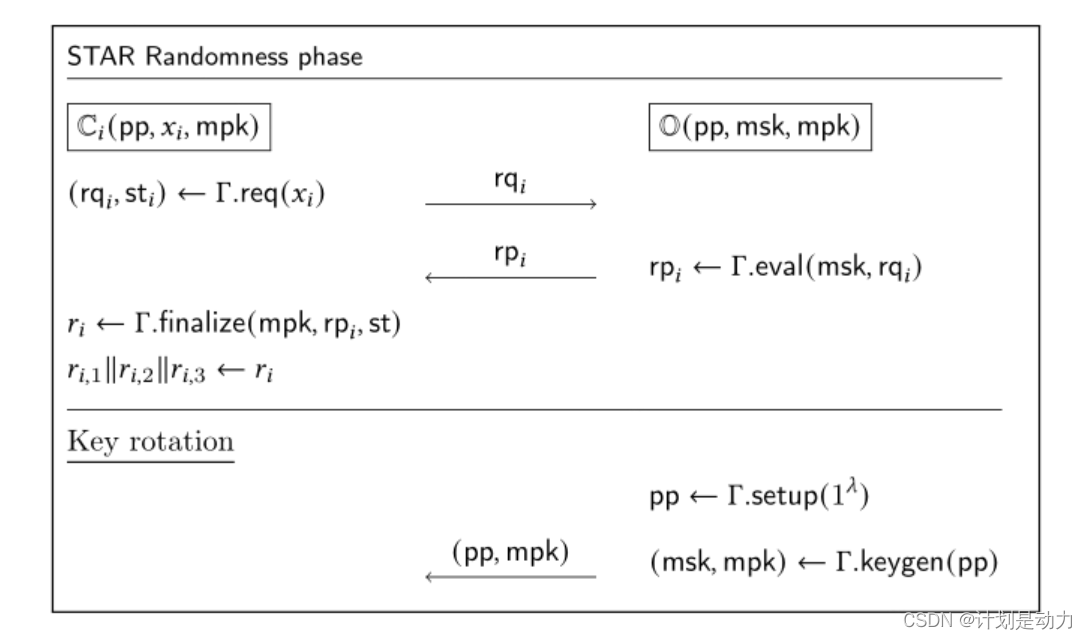
用于执行测量阈值聚合的 S T A R 协议。 在随机性阶段,客户端从 O 中采样 V O P R F 随机性, O 以规则的间隔旋转其 V O P R F 密钥对。 在消息阶段,客户端构建与其测量值相对应的编码消息。 在聚合阶段, S 从客户端接收编码消息,并学习由 ≥ k 客户发送的测量值 ( 以及相关数据 ) 。 用于执行测量阈值聚合的STAR协议。 \\在随机性阶段,客户端从\mathbb O中采样VOPRF随机性,\mathbb O以规则的间隔旋转其VOPRF密钥对。 \\在消息阶段,客户端构建与其测量值相对应的编码消息。 \\在聚合阶段,S从客户端接收编码消息,并学习由≥k 客户发送的测量值(以及相关数据)。 用于执行测量阈值聚合的STAR协议。在随机性阶段,客户端从O中采样VOPRF随机性,O以规则的间隔旋转其VOPRF密钥对。在消息阶段,客户端构建与其测量值相对应的编码消息。在聚合阶段,S从客户端接收编码消息,并学习由≥k客户发送的测量值(以及相关数据)。
随机性阶段:STARLite
可以构建一个称为STARLite的STAR版本,该版本提供较弱的安全保证,有利于减少对随机性服务器的要求(这可以导致更简单的实际部署)。STARLite协议仅在从适当的高熵分布中对客户端测量进行采样时才保留安全性。
S
T
A
R
L
i
t
e
协议中的客户端只是直接从他们的测量
(
例如
r
i
←
H
(
x
i
)
)
采样
r
i
H
是一个随机的
o
r
a
c
l
e
模型散列函数),然后直接进入消息阶段。
STARLite协议中的客户端只是直接从他们的测量(例如r_i ← H(x_i))采样r_i\\H 是一个随机的oracle模型散列函数),然后直接进入消息阶段。
STARLite协议中的客户端只是直接从他们的测量(例如ri←H(xi))采样riH是一个随机的oracle模型散列函数),然后直接进入消息阶段。
消息阶段

消息构建阶段由以下步骤组成:
(1)
客户
(
x
i
,
r
i
)
解析
r
i
为三部分
:
(
r
i
,
1
,
r
i
,
2
,
r
i
,
3
)
∈
(
{
0
,
1
}
w
×
{
0
,
1
}
w
×
{
0
,
1
}
w
)
客户(x_i,r_i)解析r_i为三部分: \\(r_{i,1},r_{i,2},r_{i,3})\in (\{0,1\}^w\times\{0,1\}^w\times\{0,1\}^w)
客户(xi,ri)解析ri为三部分:(ri,1,ri,2,ri,3)∈({0,1}w×{0,1}w×{0,1}w)
(2)
他们用伪随机数生成器导出了一个对称秘钥
K
i
,将
r
i
,
1
作为种子
他们用伪随机数生成器导出了一个对称秘钥K_i,将r_{i,1}作为种子
他们用伪随机数生成器导出了一个对称秘钥Ki,将ri,1作为种子
(3)
他们使用
k
−
o
u
t
−
o
f
−
n
秘密共享方案构建了一个随机共享
s
i
o
f
r
i
,
1
使用
r
i
,
2
作为在共享生成过程中使用的随机值
(
如基于
s
h
a
m
i
r
的一组随机多项式系数
)
他们使用k-out-of-n秘密共享方案构建了一个随机共享s_i \ of \ r_{i,1} \\使用r_{i,2}作为在共享生成过程中使用的随机值(如基于shamir的一组随机多项式系数)
他们使用k−out−of−n秘密共享方案构建了一个随机共享si of ri,1使用ri,2作为在共享生成过程中使用的随机值(如基于shamir的一组随机多项式系数)
(4)
他们构造了密文
c
i
作为他们测量数据
x
i
的加密结果
以及他们想要附加的任何辅助数据
使用具有先前导出的密钥的对称加密方案和秘钥
K
i
.
他们构造了密文c_i 作为他们测量数据x_i的加密结果 \\以及他们想要附加的任何辅助数据\\使用具有先前导出的密钥的对称加密方案和秘钥K_i.
他们构造了密文ci作为他们测量数据xi的加密结果以及他们想要附加的任何辅助数据使用具有先前导出的密钥的对称加密方案和秘钥Ki.
(5)
最后构造消息
:
(
c
i
,
s
i
,
t
i
)
t
i
=
r
i
,
3
最后构造消息:(c_i,s_i,t_i) \\t_i = r_{i,3}
最后构造消息:(ci,si,ti)ti=ri,3
聚合阶段

在最后的聚合阶段,聚合服务器从至少n个客户端接收消息,并知道至少由k 客户收集数据的中的任何一个的编码。步骤如下
(1)
聚合服务器将共享相同
t
l
的消息分组在一起,即子集
E
l
.
聚合服务器将共享相同t_l的消息分组在一起,即子集\mathcal E_l.
聚合服务器将共享相同tl的消息分组在一起,即子集El.
(2)
他们丢弃子集的数量少于
k
的消息
然后对剩余的每个子集执行以下操作:
(
a
)
对共享值的集合运行共享恢复算法
{
s
l
}
∈
E
l
输出
r
l
,
1
(
b
)
根据
r
l
,
1
导出加密秘钥
K
i
(
c
)
使用
K
i
解密每个客户端密文
c
j
并将测量值
x
i
分组
(
带有辅助数据对象
a
u
x
k
的列表
)
,
由每个客户端发送
他们丢弃子集的数量少于k的消息\\然后对剩余的每个子集执行以下操作: \\(a)对共享值的集合运行共享恢复算法\{s_l \} ∈ \mathcal E_l 输出r_{l,1} \\(b)根据r_{l,1}导出加密秘钥K_i \\(c)使用K_i解密每个客户端密文c_j \\ 并将测量值x_i分组( 带有辅助数据对象aux_k的列表) , 由每个客户端发送
他们丢弃子集的数量少于k的消息然后对剩余的每个子集执行以下操作:(a)对共享值的集合运行共享恢复算法{sl}∈El输出rl,1(b)根据rl,1导出加密秘钥Ki(c)使用Ki解密每个客户端密文cj并将测量值xi分组(带有辅助数据对象auxk的列表),由每个客户端发送


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









