




 本文解决在Windows环境下使用gensim加载中文分词语料库时遇到的UnicodeDecodeError问题,通过调整文本文件编码至utf-8,成功避免了无效续行字节错误。
本文解决在Windows环境下使用gensim加载中文分词语料库时遇到的UnicodeDecodeError问题,通过调整文本文件编码至utf-8,成功避免了无效续行字节错误。
在window下使用gemsim.models.word2vec.LineSentence加载中文语料库(已分词)时报如下错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 0: invalid continuation byte
我是将语料存储在news-sentences-cut.txt文件之中,然后读取进行操作,具体操作如下:
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
news_word2ve= Word2Vec(LineSentence('news-sentences-cut.txt'), size=35, workers=8)
news_word2ve.most_similar('葡萄牙', topn=20)
运行以上代码时遇到到报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 0: invalid continuation byte
网上参考大佬博客:https://www.cnblogs.com/jiangxinyang/p/10411595.html 请点击这里
参考完后还是没有解决问题,还遇到其他问题了!
我解决的方法是:
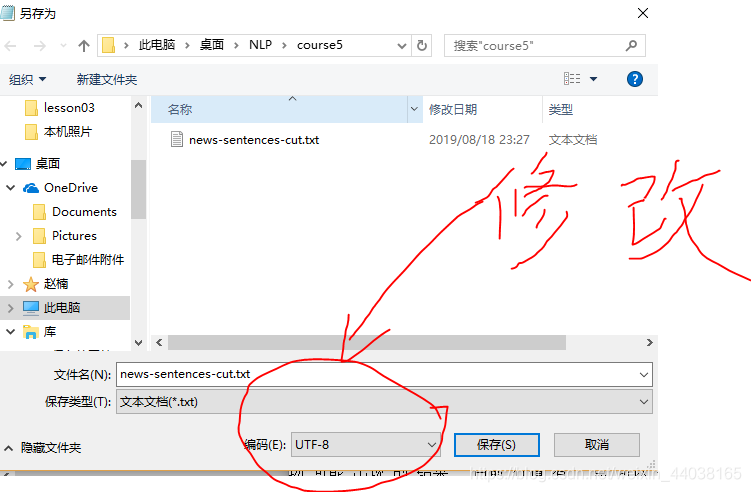
将news-sentences-cut.txt另存为txt文件时修改编码方式为utf-8.如以下截图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









