







1 如何处理类别变量?
方法一:丢弃(一般不用)
方法二:LabelEncoder
from sklearn.processing import LabelEncoder
label_encoder = LabelEncoder()
X[col] = label_encoder.fit_transform(X[col])
X_val[col] = label_encoder.transform(X_val[col]
方法三:OneHotEncoding:
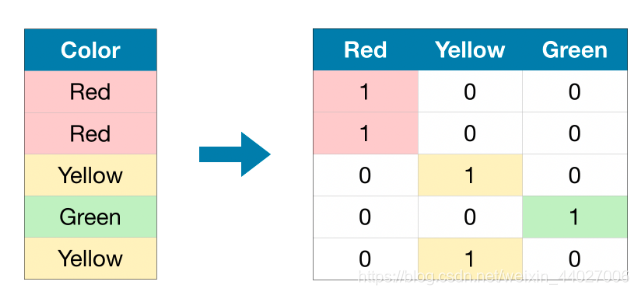
作用:可用来处理无序的类别特征。
注意:当特征类别数大于15的时候不使用该方法
from sklearn.procession import OneHotEncoding
One_H_encoder = OneHotEncoding(handle_unknown='ignore',sparse=False)
OH_cols_train = pd.DataFrame(One_H_encoder.fit_transform(X_train[object_cols])
OH_cols_val = pd.DataFrame(One_H_encoder.transform(X_val[object_cols])
OH_cols_train.index = X_train.index
OH_cols_val.index = X_val.index
num_X_train = X_train.drop(object_cols,axis=1)
num_X_val = X_val.drop(object_cols,axis=1)
OH_X_train = pd.concat([num_X_train,OH_cols_train],axis=1)
OH_X_test = pd.concat([num_X_val,OH_cols_val],axis=1)
方法四:CountEncoding
- 思想:使用某个特征中的某个取值出现的次数来代替这个值
- 为何有效:Rare values tend to have similar counts (with values like 1 or 2), so you can classify rare values together at prediction time. Common values with large counts are unlikely to have the same exact count as other values. So, the common/important values get their own grouping.
代码:
import category_encoder as ce
cat_cols = ['currency','country','category']
count_encoder = ce.CountEncoder()
count_encoded = count_encoder.fit_transform(train_data[cat_cols])
data = baseline_data.join(count_encoded).add_suffix('_count')
方法五:TargetEncoding
-
思想:使用每个特征值对应的均值来替换,比如country=‘A’,可以计算出所有country='A’的样本对应的某个数值型特征的均值是多少。
-
注意1:这里不能将测试集也包含进去,否则会发生Target Leakage。
-
注意2:如果某个特征取值非常多,会导致方差过高。Target encoding attempts to measure the population mean of the target for each level in a categorical feature. This means when there is less data per level, the estimated mean will be further away from the “true” mean, there will be more variance. There is little data per IP address so it’s likely that the estimates are much noisier than for the other features. The model will rely heavily on this feature since it is extremely predictive. This causes it to make fewer splits on other features, and those features are fit on just the errors left over accounting for IP address. So, the model will perform very poorly when seeing new IP addresses that weren’t in the training data (which is likely most new data). Going forward, we’ll leave out the IP feature when trying different encodings.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









