



 本文深入探讨了数据归一化的两种主要方法:最值归一化和均值方差归一化,详细解释了它们的应用场景及优缺点,并通过Python代码示例展示了如何进行数据归一化。
本文深入探讨了数据归一化的两种主要方法:最值归一化和均值方差归一化,详细解释了它们的应用场景及优缺点,并通过Python代码示例展示了如何进行数据归一化。
数据归一化用来解决数据之间尺度标准不一样从而造成的信息影响。
常用的数据归一化方案有两种:
1、最值归一化:把所有数据映射到0-1之间
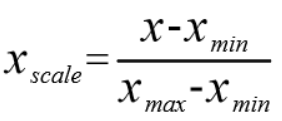
*适用于分布有明显边界的情况;
*受outlier影响较大。
2、均值方法归一化:把所用数据归一到均值为0方差为1的分布中。
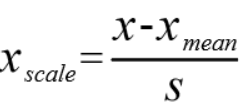
*数据分布没有明显的边界;
*有可能存在极端数据值。
import numpy as np
import matplotlib.pyplot as plt
#######最值归一化Normalization########
#向量
x = np.random.randint(0, 100, size = 100)
new_x = (x - np.min(x)) / (np.max(x) - np.min(x))
#矩阵
X = np.random.randint(0, 100, (50, 2))
X = np.array(X, dtype=float)
for i in range(X.shape[1]):
new_X[:,i] = (X[:,i] - np.min(X[:,i])) / (np.max(X[:,i]) - np.min(X[:,i]))
#画出点
plt.scatter(X[:,0], X[:1])
plt.show()
#######均值方差归一化Standardization#########
X2 = np.random.randint(0, 100, (50, 2))
X2 = np.array(X2, dtype=float)
X2[:,0]=(X2[:,0] - np.mean(X2[:,0])) / np.std(X2[:,0])
X2[:,1]=(X2[:,1] - np.mean(X2[:,1])) / np.std(X2[:,1])
plt.scatter(X2[:,0].X2[:,1])
plt.show()
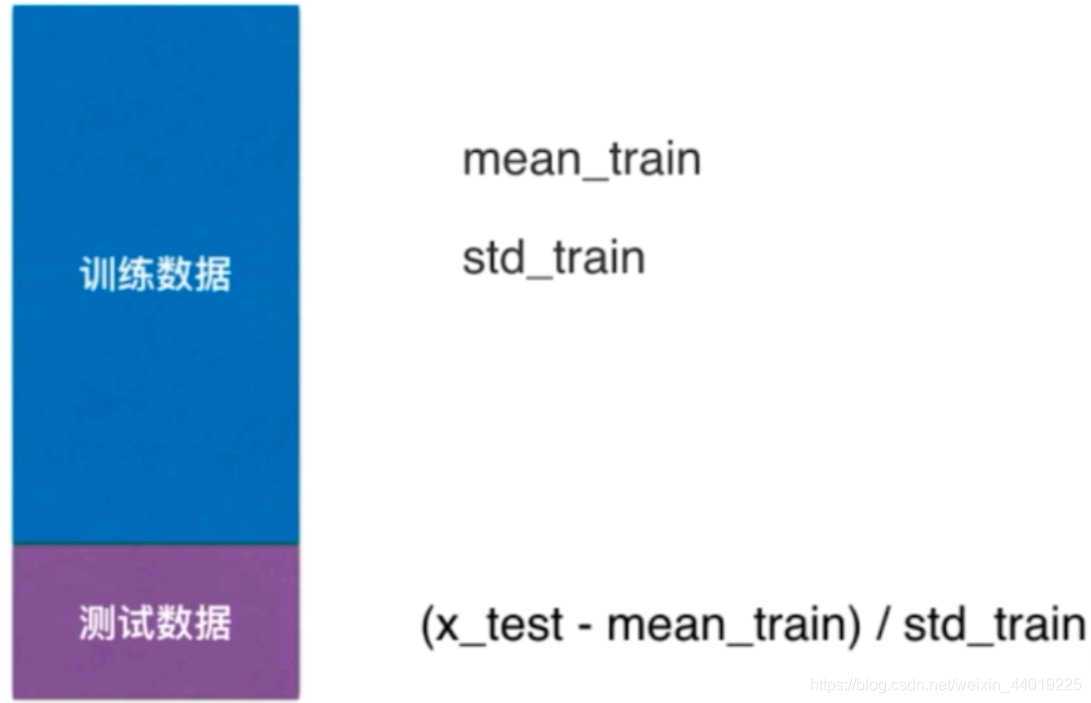

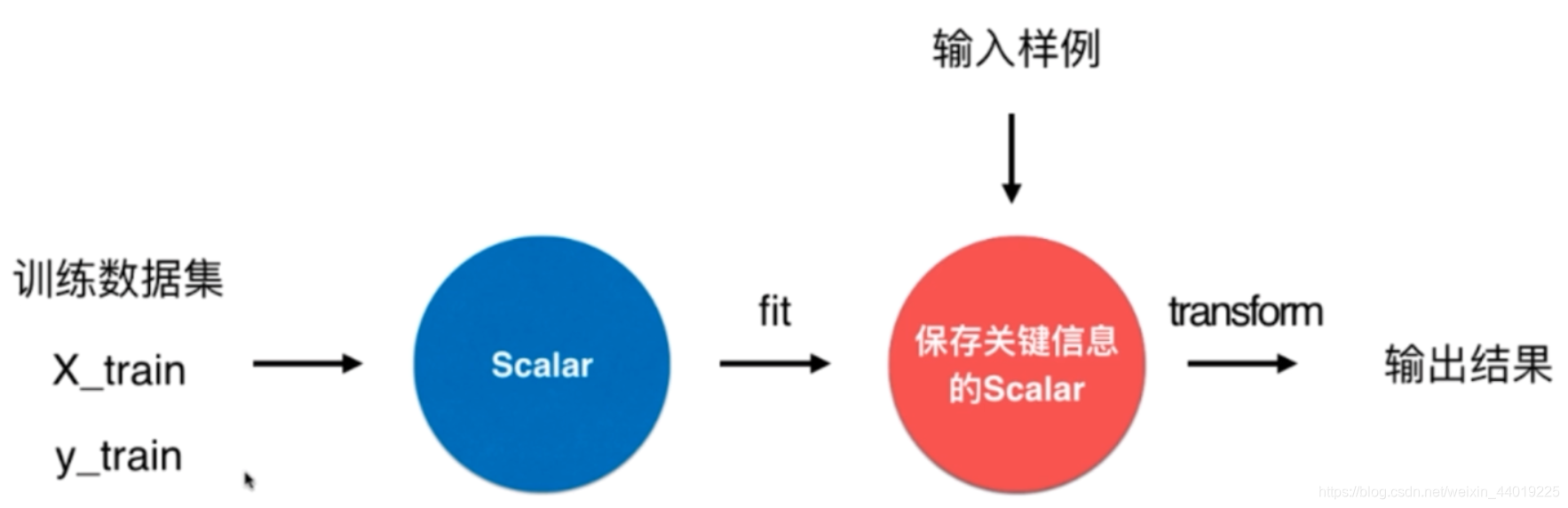
在scikit-learn中使用Scaler保存训练集数据集得到的均值核方差。

















 3595
3595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









