







 本文集合了四篇关于基于对比学习的小样本学习(few-shot learning)的论文,涵盖了ECCV 2020、NIPS 2020和AAAI 2021等会议。研究内容包括:预训练阶段使用自监督和监督对比损失提升模型性能,元训练阶段通过Cross-view Episodic Training和Distance-scaled Contrastive Loss增强表征的可转移性和判别能力;提出CrossTransformer结构,利用自监督学习SimCLR和Transformer进行局部信息匹配;以及通过Augmented Embeddings和对比原型学习CPL解决FSL中样本不足的问题。
本文集合了四篇关于基于对比学习的小样本学习(few-shot learning)的论文,涵盖了ECCV 2020、NIPS 2020和AAAI 2021等会议。研究内容包括:预训练阶段使用自监督和监督对比损失提升模型性能,元训练阶段通过Cross-view Episodic Training和Distance-scaled Contrastive Loss增强表征的可转移性和判别能力;提出CrossTransformer结构,利用自监督学习SimCLR和Transformer进行局部信息匹配;以及通过Augmented Embeddings和对比原型学习CPL解决FSL中样本不足的问题。
基于contrast learning的few-shot learning论文集合(2)
基于contrast learning的few-shot learning论文集合(3)
论文一:ECCV 2020《Few-Shot Classification with Contrastive Learning》

论文链接:https://arxiv.org/pdf/2209.08224.pdf
code链接:https://github.com/Yzy5020/fsc-cl
在本文中,提出了一种新的基于对比学习的框架,将对比学习无缝地集成到两个阶段,以提高小样本分类的性能。在预训练阶段,我们分别提出了两种基于自监督和监督信号的对比损失来训练模型,即,提出的自监督对比损失利用了特征向量与特征映射(vector-map),和特征映射与特征映射(map-map)两种形式的局部信息,我们的监督对比损失很好地利用了单个实例之间的相关性和同一类别的不同实例之间的相关性。在元训练阶段,出于从共享上下文(如原始图像)的多个视图(例如,通过对图像应用不同的数据增强)中提取的特征之间最大化相互信息的想法(例如,通过对图像应用不同的数据增强),我们提出了一种跨视点情景训练机制(CVET),对同一事件的两个不同视点进行最近质心分类,并在此基础上采用距离尺度的对比损失。这两种策略迫使模型克服观点之间的偏见,促进表征的可转移性。
辅助:对比学习之SimCLR
1. 总框架
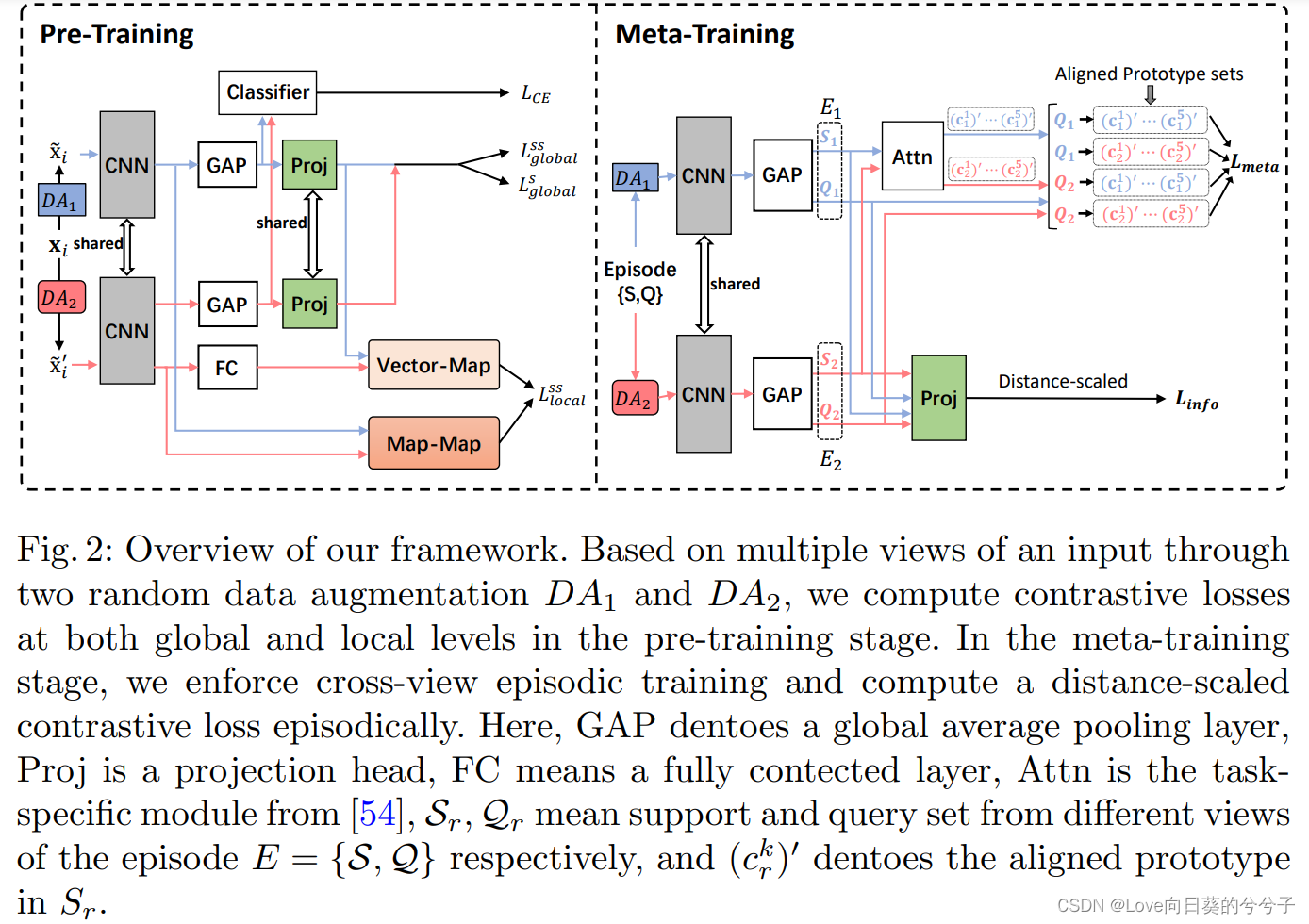
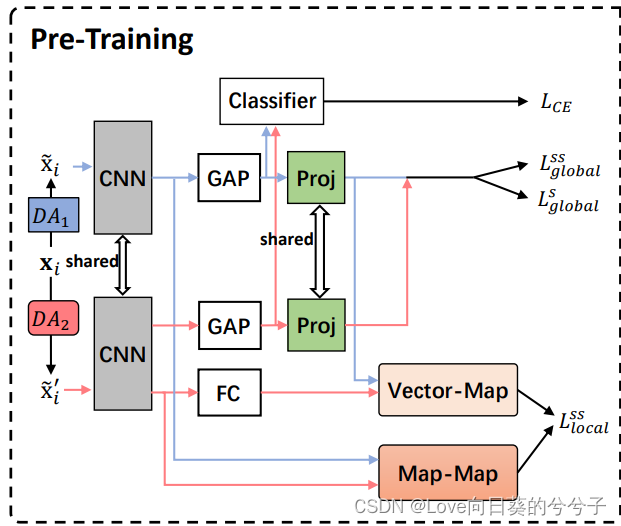
2. 预训练阶段
在预训练阶段引入实例判别对比学习,以缓解仅使用CE损失训练导致的过拟合问题。如下图所示,我们分别在global和local层面提出了自监督对比损失。在这些损失中使用自我监督有助于产生更一般化的表示。同时,我们还采用全局监督对比损失 L g l o b a l s L^s_{global} Lglobals来捕获同一类别的实例之间的相关性。
- Global self-supervised contrastive loss
这种损失(又称InfoNCE损失)的目的是增强同一图像视图之间的相似性,同时降低不同图像视图之间的相似性。形式上,我们对元训练集 D t r a i n D_{train} Dtrain中的一批样本 { x i , y i } i = 1 N \{x_i, y_i \}^N_{i=1} { xi,yi}i=1N随机应用两种数据增广方法,生成增广batch { x ~ i , y ~ i } i = 1 2 N \{\tilde{x}_i, \tilde{y}_i \}^{2N}_{i=1} { x~i,y~i}i=12N。这里, x ~ i \tilde{x}_i x~i和 x ~ i ′ \tilde{x}'_i x~i′表示 x i x_i xi的两种不同的view,它们被认为是一对正样本。 x ~ i \tilde{x}_i x~i依次经过特征提取器( x ^ i \hat{x}_i x^i),GAP ( h i h_i hi)和一个映射层获得全局特征映射 z i z_i zi。
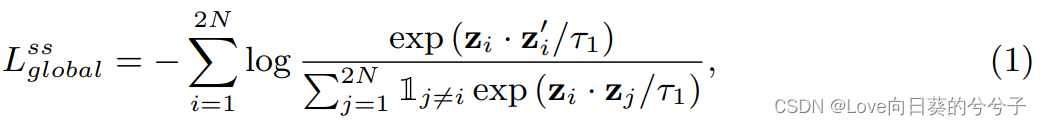
其中·运算表示l2归一化后的内积。 - Local self-supervised contrastive loss
虽然 L g l o b a l s s L^{ss}_{global} Lglobalss(Eq.(1))倾向于基于全局特征向量 h i h_i hi的可转移表示,但它可能会忽略特征映射 x i x_i xi中的一些局部判别信息,这些信息可能有利于元测试。为此,我们在local-level上计算自监督对比损失。与以前的方法不同,我们利用映射-映射和向量-映射模块来提高表示的鲁棒性和泛化性。
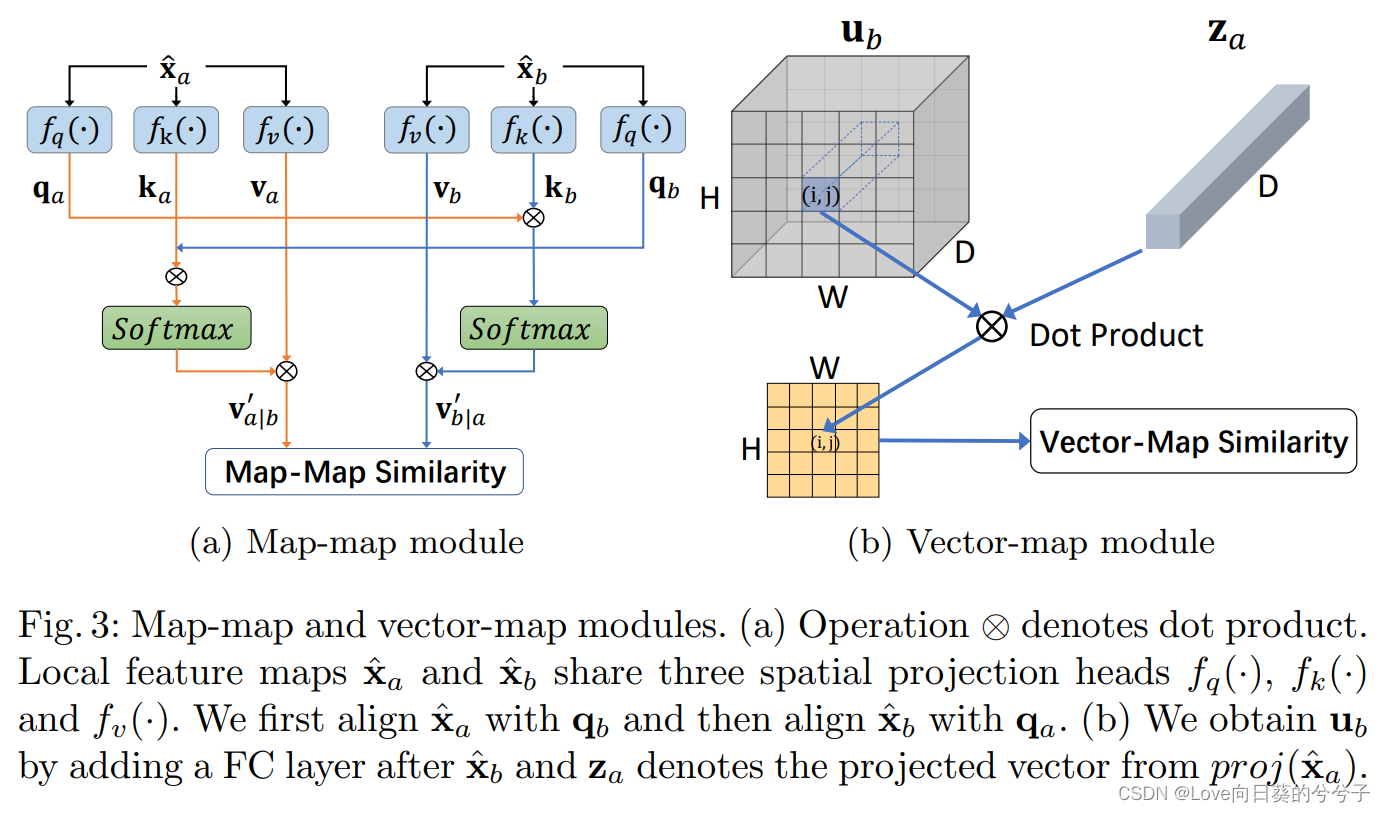
1)map-map module:
将局部特征 x ^ i \hat{x}_i x^i映射成查询 q i = f q ( x ^ i ) q_i = f_q(\hat{x}_i) qi=fq(x^i), key k i = f k ( x ^ i ) k_i= f_k(\hat{x}_i) ki=fk(x^i), value v i = f v ( x ^ i ) v_i = f_v(\hat{x}_i) vi=fv(x^i),其中 q i , k i , v i ∈ R H W × D q_i, k_i, v_i ∈ R^{HW×D} qi,ki,vi∈RHW×D。对于一对局部特征映射 x ^ a \hat{x}_a x^a和 x ^ b \hat{x}_b x^b,我们将 x ^ a \hat{x}_a x^a和 x ^ b \hat{x}_b x^b对齐,得到
将 x ^ b \hat{x}_b x^b和 x ^ a \hat{x}_a x^a对齐,得到

对对齐结果的每个位置 ( i , j ) (i, j) (i,j)进行l2归一化后,我们可以计算两个局部特征映射 x ^ a \hat{x}_a x^a和 x ^ b \hat{x}_b x^b之间的相似度如下:
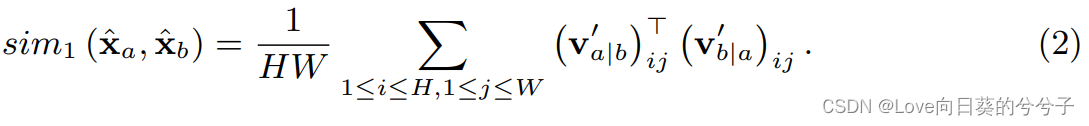
基于此,基于两两特征映射的自监督对比损失可以计算如下
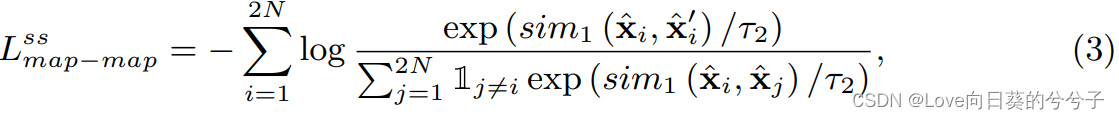
2)vector-map module:
采用向量映射模块进一步挖掘实例间的局部对比信息。具体来说,我们使用全连通(FC)层得到 u i = g ( x ^ i ) = σ ( W x ^ i ) ∈ R D × H W u_i = g(\hat{x}_i) = σ(W\hat{x}_i)∈R^{D×HW}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









