




 本文介绍了单目深度估计的无监督和有监督方法,重点关注数据集、网络模型和损失函数。讨论了包括基于多任务网络、GAN网络和其他方法在内的技术,并详细解析了几篇重要的学术论文,探讨了它们的创新点和应用。
本文介绍了单目深度估计的无监督和有监督方法,重点关注数据集、网络模型和损失函数。讨论了包括基于多任务网络、GAN网络和其他方法在内的技术,并详细解析了几篇重要的学术论文,探讨了它们的创新点和应用。
单目深度估计
问题公式化:求非线性映射函数![]()
一、数据集:
NYU Depth:视频序列和dense depth map通过RGB-D采集的,但是不是每一种图像都有深度图,因为映射是离散的。
KITTI:计算机视觉中最大的数据集包括光流、视觉里程、深度、目标检测、语义分割、跟踪,有一部分是有稀疏的深度图来自LIDAR sensor。
Make3D:有image-depth pairs 没有视频序列和stereo images 适用于有监督任务和测试无监督网络。
Cityscapes:主要用于语义分割任务包含语义lable, 也包含一些stereo 视频序列但是没有深度图 适合无监督深度估计。
二、无监督方法:
输入:序列 或 stereo images
方法分类:
1.基于多任务网络:
利用深度图、位姿检测等重构目标图,再用源图进行监督学习,公式化如下:
整体网络:, E是位姿检测或转换网络
光一致性监督:![]() ,再添加一些其他loss约束:如深度图光滑约束:
,再添加一些其他loss约束:如深度图光滑约束: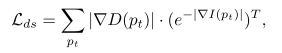
2.基于GAN网络:
同上类似,利用生成器重构目标图,再把判别器当作无监督loss 判断真假进行训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4632
4632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









