 爬取豆瓣热门电影
爬取豆瓣热门电影





基于python爬取豆瓣网站最近热门电影信息
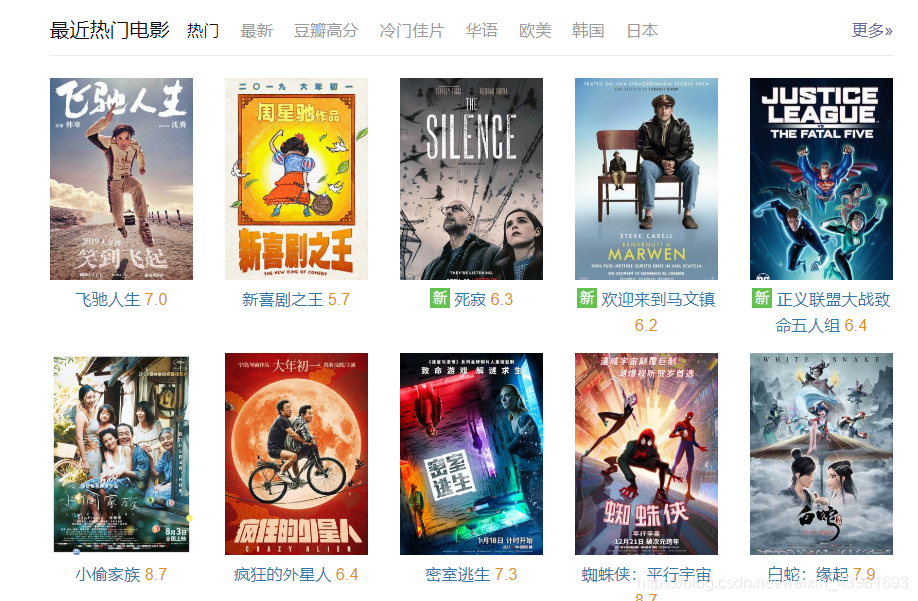
使用chorm浏览器打开豆瓣网站,进入最近热门电影,按“F12”调出开发者工具,点击Network,此时,我们看到,打开网络面板后,发现有很多响应。在网络面板中 XHR 是 Ajax 中的概念,表示
XML-HTTP-request,一般 Javascript 加载的文件隐藏在 JS 或者 XHR。通过查找发现,网页的Javascript 加载的文件在 XHR 面板。 “最近热门电影”模块的信息在 XHR 的 Preview 标签中有需要的信息。在网络面板的 XHR中,查看资源的 Preview 信息,可以看到电影列表的 HTML 信息。

1、 单击资源的 Headers 标签,找到“Request URL”信息
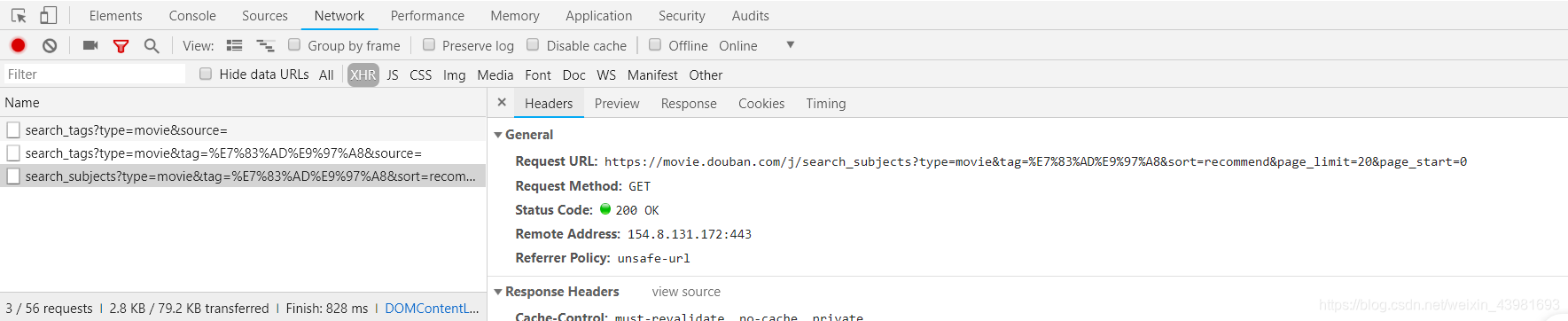
2、打开“Request URL”URL 网址信息,找到需要爬取的信息,这里要爬取的是每个电影对应的连接
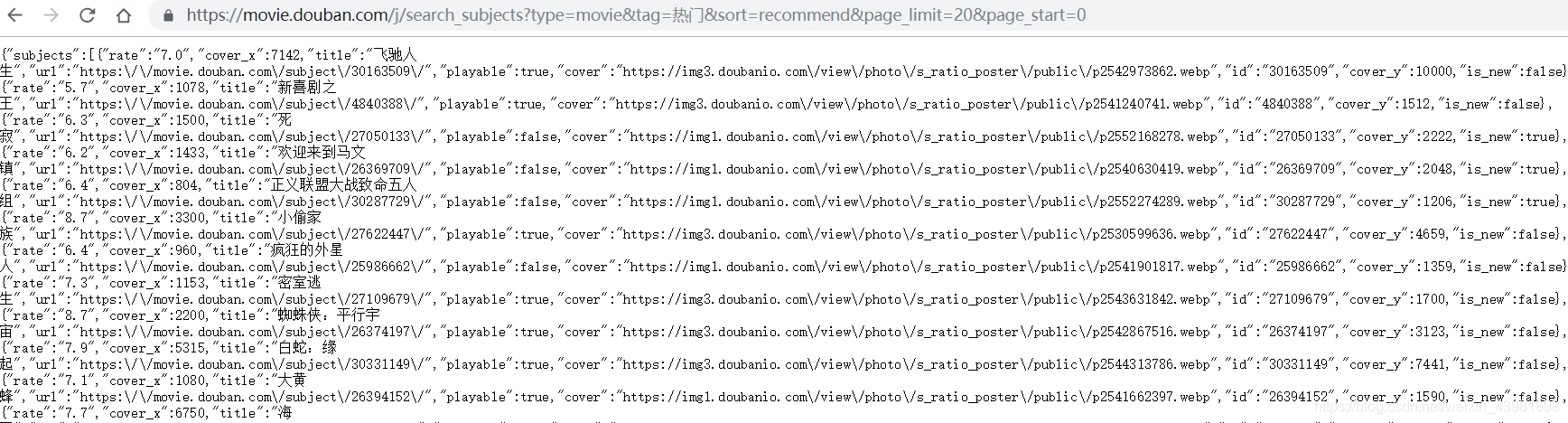
3、通过“Request URL”URL 网址分析,page_limit=紧接的数值就是电影的个数,在程序里设定这个值可以控制你要获取电影信息的个数

4、通过正则表达式来筛选出每个电影对应的链接
def craw(url):
ua = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"}
rqg = requests.get(url, headers=ua)
html = rqg.content.decode('utf-8')
pat1='"url":"(.*?)","playable"'
news1=re.compile(pat1,re.S).findall(html)
list1=[]
for i in news1:
a=i.replace('\\','')
list1.append(a)
return list1
5、获取到电影的链接后通过链接访问每个电影的主页,按静态网页的爬取方法来获取电影的详细信息并保存到MySQL数据库里。
import requests
import re
from lxml import etree
import pymysql
def craw(url):
ua = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"}
rqg = requests.get(url, headers=ua)
html = rqg.content.decode('utf-8')
pat1='"url":"(.*?)","playable"'
news1=re.compile(pat1,re.S).findall(html)
list1=[]
for i in news1:
a=i.replace('\\','')
list1.append(a)
return list1
def readurl(list):
for i in list:
ua = {"User-Agent": "Mozill 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2022
2022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









