







本文整理自云邪、雪尽在 Flink Forward Asia 2020 的分享,该分享以 4 个章节来详细介绍如何利用 Flink SQL 构建流批一体的 ETL 数据集成, 文章的主要内容如下:
- 数据仓库与数据集成
- 数据接入(E)
- 数据入仓/湖(L)
- 数据打宽(T)
数据仓库与数据集成

数据仓库是一个集成的(Integrated),面向主题的(Subject-Oriented),随时间变化的(Time-Variant),不可修改的(Nonvolatile)数据集合,用于支持管理决策。这是数据仓库之父 Bill Inmon 在 1990 年提出的数据仓库概念。该概念里最重要的一点就是“集成的”,其余特性都是一些方法论的东西。因为数据仓库首先要解决的问题,就是数据集成,就是将多个分散的、异构的数据源整合在一起,消除数据孤岛,便于后续的分析。这个不仅适用于传统的离线数仓,也同样适用于实时数仓,或者是现在火热的数据湖。首先要解决的就是数据集成的问题。如果说业务的数据都在一个数据库中,并且这个数据库还能提供非常高效的查询分析能力,那其实也用不着数据仓库和数据湖上场了。

数据集成就是我们常称作 ETL 的过程,分别是数据接入、数据清洗转换打宽、以及数据的入仓入湖,分别对应三个英文单词的首字母,所以叫 ETL。ETL 的过程也是数仓搭建中最具工作量的环节。那么 Flink 是如何改善这个 ETL 的过程的呢?我们先来看看传统的数据仓库的架构。
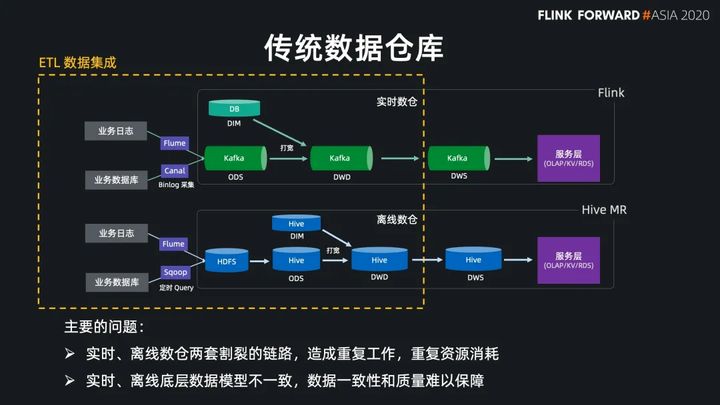
传统的数据仓库,实时和离线数仓是比较割裂的两套链路,比如实时链路通过 Flume和 Canal 实时同步日志和数据库数据到 Kafka 中,然后在 Kafka 中做数据清理和打宽。离线链路通过 Flume 和 Sqoop 定期同步日志和数据库数据到 HDFS 和 Hive。然后在 Hive 里做数据清理和打宽。
这里我们主要关注的是数仓的前半段的构建,也就是到 ODS、DWD 层,我们把这一块看成是广义的 ETL 数据集成的范围。那么在这一块,传统的架构主要存在的问题就是这种割裂的数仓搭建这会造成很多重复工作,重复的资源消耗,并且实时、离线底层数据模型不一致,会导致数据一致性和质量难以保障。同时两个链路的数据是孤立的,数据没有实现打通和共享。
那么 Flink 能给这个架构带来什么改变呢?
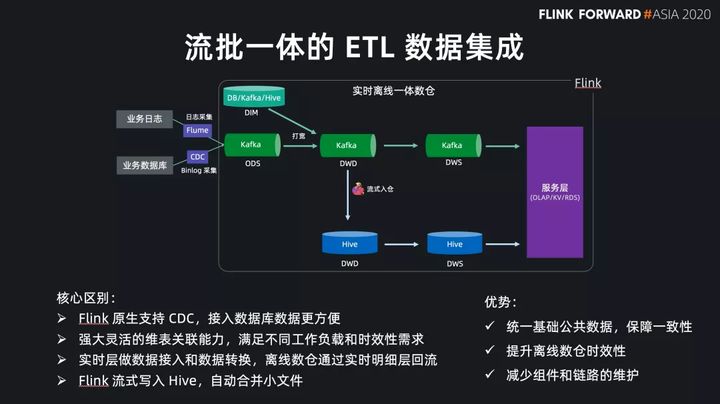
基于 Flink SQL 我们现在可以方便地构建流批一体的 ETL 数据集成,与传统数仓架构的核心区别主要是这几点:
- Flink SQL 原生支持了 CDC 所以现在可以方便地同步数据库数据,不管是直连数据库,还是对接常见的 CDC工具。
- Flink SQL 在最近的版本中持续强化了维表 join 的能力,不仅可以实时关联数据库中的维表数据,现在还能关联 Hive 和 Kafka 中的维表数据,能灵活满足不同工作负载和时效性的需求。
- 基于 Flink 强大的流式 ETL 的能力,我们可以统一在实时层做数据接入和数据转换,然后将明细层的数据回流到离线数仓中。
- 现在 Flink 流式写入 Hive,已经支持了自动合并小文件的功能,解决了小文件的痛苦。
所以基于流批一体的架构,我们能获得的收益:
- 统一了基础公共数据
- 保障了流批结果的一致性
- 提升了离线数仓的时效性
- 减少了组件和链路的维护成本
接下来我们会针对这个架构中的各个部分,结合场景案例展开进行介绍,包括数据接入,数据入仓入湖,数据打宽。
数据接入
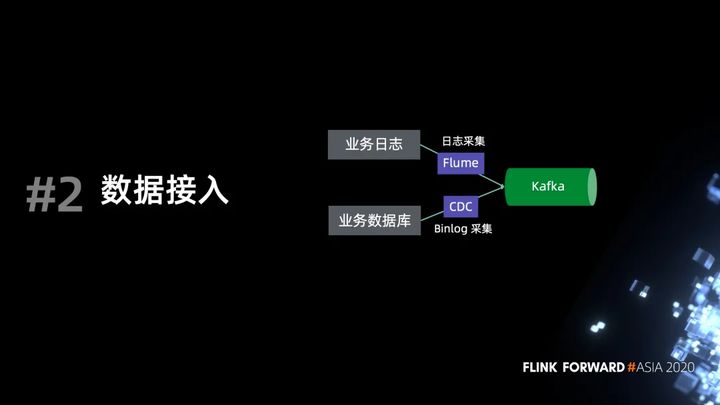
现在数据仓库典型的数据来源主要来自日志和数据库,日志接入现阶段已经非常成熟了,也有非常丰富的开源产品可供选择,包括 Flume,Filebeat,Logstash 等等都能很方便地采集日志到 Kafka 。这里我们就不作过多展开。
数据库接入会复杂很多,常见的几种 CDC 同步工具包括 Canal,Debezium,Maxwell。Flink 通过 CDC format 与这些同步工具做了很好的集成,可以直接消费这些同步工具产生的数据。同时 Flink 还推出了原生的 CDC connector,直连数据库,降低接入门槛,简化数据同步流程。
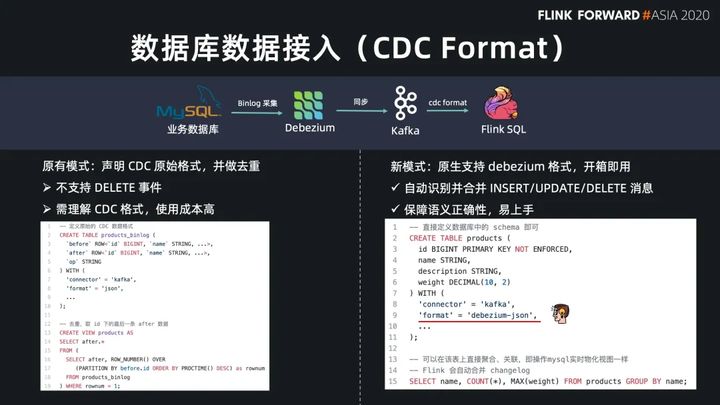
我们先来看一个使用 CDC format 的例子。现在常见的方案是通过 Debezium 或者 Canal 去实时采集 MySQL 数据库的 binlog,并将行级的变更事件同步到 Kafka 中供 Flink 分析处理。在 Flink 推出 CDC format 之前,用户要去消费这种数据会非常麻烦,用户需要了解 CDC 工具的数据格式,将 before,after 等字段都声明出来,然后用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









