







 本文详细介绍了Hadoop集群的搭建过程。首先阐述准备工作,包括设置服务器名和配置免密;接着说明安装步骤,如安装JDK和Hadoop;然后讲解各项配置文件的设置;还提及启动与关闭操作,首次启动需初始化;最后介绍了通过web查看和集群状态检查来验证集群是否正常。
本文详细介绍了Hadoop集群的搭建过程。首先阐述准备工作,包括设置服务器名和配置免密;接着说明安装步骤,如安装JDK和Hadoop;然后讲解各项配置文件的设置;还提及启动与关闭操作,首次启动需初始化;最后介绍了通过web查看和集群状态检查来验证集群是否正常。
序
1、准备
hadoop集群搭建需要准备以下内容:
| 材料 | 版本 | 数量 | 备注 |
|---|---|---|---|
| 安装包 | hadoop-3.2.0.tar.gz | 3 | |
| 虚拟机 | CentOS 7.5 | 3 | |
| IP | / | 3 | 192.168.28.61/62/63 |
| 服务器名 | hosts文件 | 3 | hadoop1、 hadoop2、 hadoop3 |
| 免密 | ssh | 3 | 设置ssh公钥免密,hadoop守护程序需要免密支持 |
| jdk | 版本7以上 | 3 | 提前安装好 |
hadoop集群是不需要zookeeper作为支撑,只要在具备jdk环境下即可进行安装。
1.1 设置服务器名
编辑三台服务器的/etc/hosts文件,写入如下内容,保存。
192.168.28.61 hadoop1
192.168.28.62 hadoop2
192.168.28.63 hadoop3
1.2 配置免密
| IP | 服务器名 |
|---|---|
| 192.168.28.61 | hadoop1 |
| 192.168.28.62 | hadoop2 |
| 192.168.28.63 | hadoop3 |
(1)获取公钥:
在192.168.28.61服务器上输入如下命令,一直回车。
ssh-keygen -t rsa
(2)建立authorized_keys文件
在192.168.28.62和192.168.28.63服务器上的/root/.ssh目录下分别建立authorized_keys文件
touch /root/.ssh/authorized_keys
(3)将192.168.28.61的公钥写入192.168.28.62和192.168.28.63服务器上的authorized_keys文件中。
2、安装
2.1 安装jdk
略
2.3 安装hadoop
安装目录是任意选择的,这里我们将hadoop安装在/opt/hadoop 目录下。
(1)上传文件
将安装包hadoop-3.2.0.tar.gz,上传到/opt目录下。
(2)解压文件
进入/opt目录中,找到hadoop-3.2.0.tar.gz,并解压。
tar -zxvf hadoop-3.2.0.tar.gz
(3)重命名
将解压后的hadoop-3.2.0文件夹重命名为hadoop
mv hadoop-3.2.0 hadoop
(3)建立补充目录
mkdir -p /opt/hadoop/hdfs/name
mkdir -p /opt/hadoop/hdfs/data
mkdir -p /opt/hadoop/tmp
三台虚拟机的操作一致,至此安装步骤就简单的完成了。
3、配置
hadoop配置文件都在/opt/hadoop/etc/hadoop目录下,
| 序号 | 配置文件名 | 说明 |
|---|---|---|
| 1 | core-site.xml | |
| 2 | hadoop-env.sh | hadoop环境配置 |
| 3 | hdfs-site.xml | hdfs配置 |
| 4 | mapred-env.sh | mapreduce环境配置 |
| 5 | workers | data节点配置 |
| 6 | yarn-env.sh | yarn环境配置 |
3.1 配置core-site.xml
<configuration>
<!-- HDFS的URI,文件系统://namenode标识:端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- namenode上本地的hadoop临时文件夹 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
3.2 配置hadoop-env.sh
在hadoop-env.sh配置文件中,增加jdk的环境变量
export JAVA_HOME=/usr/local/java
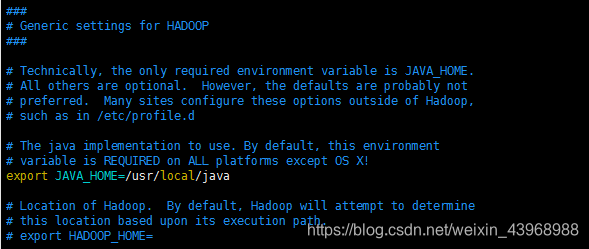
3.3 配置hdfs-site.xml
在hdfs-site.xml文件中,增加如下内容:
<configuration>
<!-- namenode上存储hdfs名字空间元数据 -->
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hdfs/name </value>
</property>
<!-- datanode上数据块的物理存储位置 -->
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hdfs/data</value>
</property>
<property>
<!-- 副本数,一般小于节点数 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- HDFS主节点地址,这里的配置直接影响web页面的访问 -->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.28.61:50070</value>
</property>
<!-- 配置为false后,可以允许不要检查权限就生成dfs上的文件,虽然方便,但是你需要防止误删除,虚拟机上测试建议使用false -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
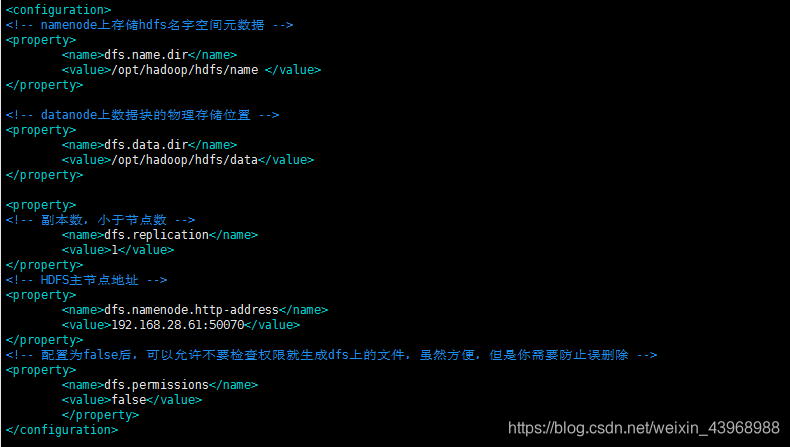
3.4 配置mapred-env.sh
增加JDK环境变量:
export JAVA_HOME=/usr/local/java
3.5 配置workers
新版本的hadoop集群使用了workers文件,取代了1.0版本的slaves文件。这里的workers文件控制了节点的数量,无论是master还是slaver服务器,均需要写入workers文件。
因为提前做好了服务器名的修好,并配置了每台服务器的hosts文件,因此,这里直接写了服务器名,也可以写每台服务器的IP。

3.6 配置yarn-env.sh
因为这是yarn的环境变量配置文件,这里也需要增加jdk的环境变量
export JAVA_HOME=/usr/local/java
3.7 配置yarn-site.xml
端口号可以任意设置,只要不重复即可。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:18141</value>
</property>
</configuration>
3.8 配置
上述配置是在master服务器上完成的,将配置文件同步至其余的slave服务器上。
4、启动与关闭
(1)启动
hadoop首次启动时需要进行初始化操作,初始化的作用是检查有没有文件缺失,并自动补齐。
格式化之后且集群启动成功后,后续再也不需要进行格式化。格式化操作只要在主节点(master)上操作即可。
hdfs namenode–format
hadoop namenode –format
初始化后,再启动集群。
cd /opt/hadoop/sbin
./start-all.sh
(2)关闭
cd /opt/hadoop/sbin
./stop-all.sh
5、验证
(1)web查看
浏览器输入:http://192.168.28.61:50070
可以看到各个节点服务器的情况。
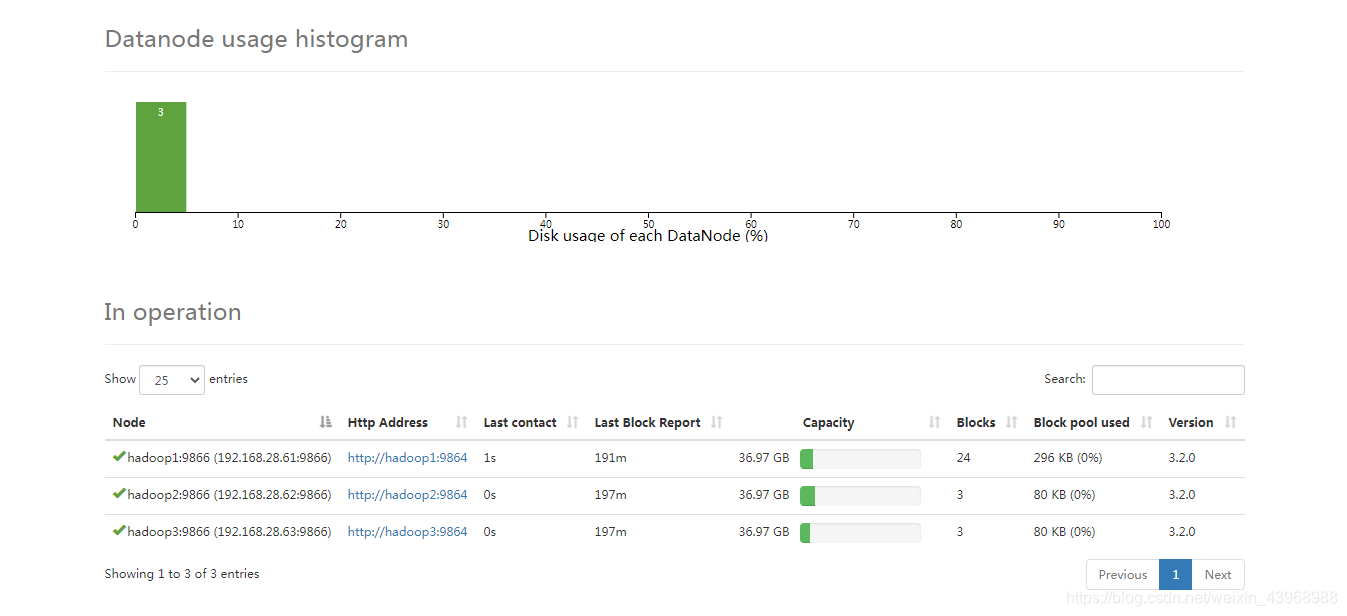
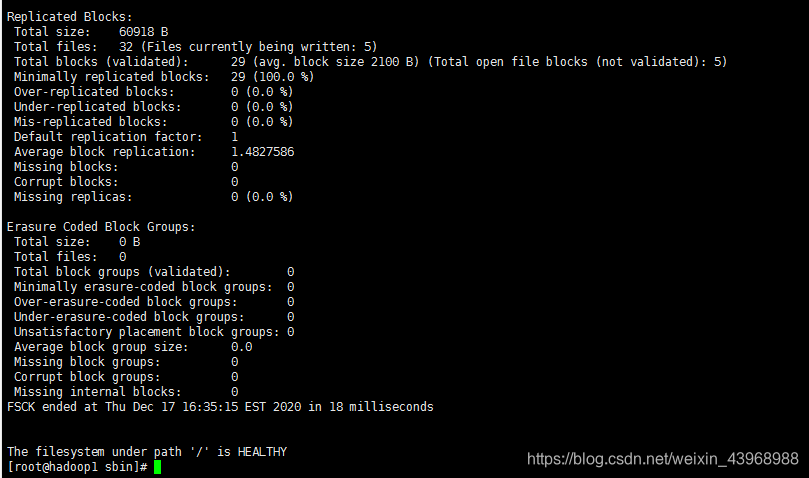
(2)集群状态检查
hadoop fsck /
检查结果如下,即为正常:

















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









