




 提出MuSe-Net解决空中视角地理定位中环境变化问题,通过two-branch网络实现不同环境下的自适应特征提取,有效提升定位精度。
提出MuSe-Net解决空中视角地理定位中环境变化问题,通过two-branch网络实现不同环境下的自适应特征提取,有效提升定位精度。
Multiple-environment Self-adaptive Network for Aerial-View Geo-localization
-
作者
- 王廷宇 杭州电子科技大学,就是之前的 Each Part Matters的作者
-
时间
- 2022年四月
-
问题
- 现在的这一领域的方法无法处理下雨、大雾等恶劣天气,因为并没有考虑在不同的环境下的domain transfer 域转移
-
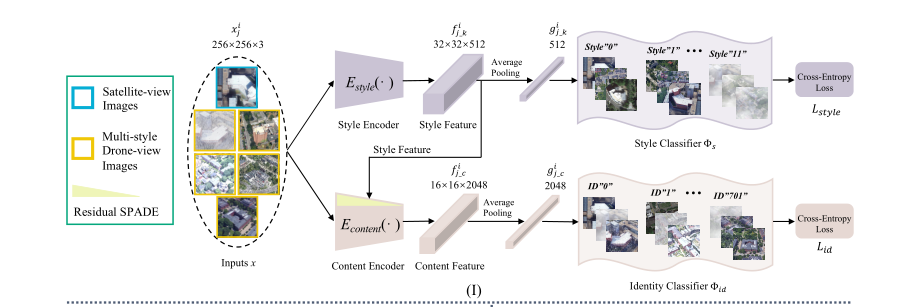
提出了一种 MuSe - Net来动态判断域的转换
- 是一个 two-branch的神经网络,包含了一个 multiple-environment style extraction network 以及一个self-adaptive feature extraction network
-
在University 1652以及CVUSA上跑的数据库,达到了有竞争力的水准
-
提出了未来的研究方向:混合大雾、大雪以及大雨
-
无人机具有更良好的可视性,不会被遮挡
-
恶劣天气导致的严重飞行事故,所以这个很有用
-
人类记住不同环境下的同一个建筑是靠去除环境因素的影响,而不是靠记住不同环境下的这个东西的样子
-
两个难点
-
reproduction of the environmental style information
- 假设一个已经见过的场景会重出现在一个新的场景里
-
使用了 一个off-the-shelf image image transformation library
-
考虑到GAN的速度和便捷性,就没用
-
-
搭建了一个MuSe Net
-
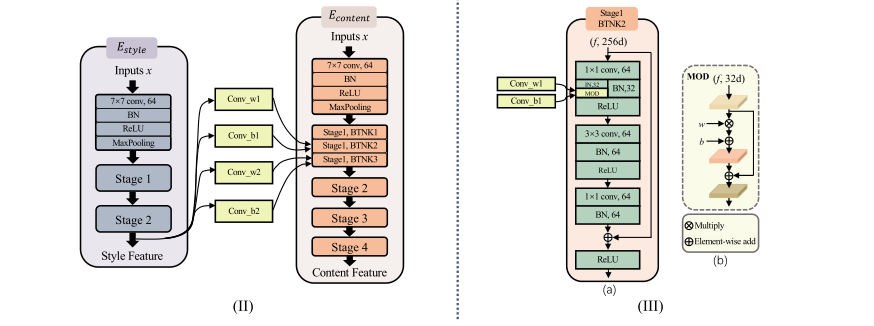
基于IBN-Net
-
Xingang Pan, Ping Luo, Jianping Shi, and Xiaoou Tang. 2018. Two at once: Enhancing learning and generalization capacities via ibn-net. In European Confer-ence on Computer Vision.
-
由于IBN NET里面集成的IN 对于内容的不同的风格,采取的形同的处理手段,作者又继承了一个 Residual Spatially adaptive denormalization,这是第一条分支
-
-
第二条分支就是一个多层的环境特征提取网络,将环境的信息提取出来作为参数投入到Residual Spade里
-
两条分支的输入相同,确保自适应特征提取网络可以利用对应的环境信息
-
-
Related works
-
Domain Generalization 域泛化
-
DG 是指从若干个具有不同数据分布的数据集中学习一个泛化能力强的模型,以便在为止Unseen 的测试集上取得较好的效果。
-
先把上面两个链接资料放这,后面看完这篇论文单独开一个DG的
-
-
IBN-NET
-
BN是一个CNN 中常用的技巧,但是,里面的全局静态变量保留了style information,也就是说,对于不同的环境,这个训练好的模型是不能用的
-
IN 与 BN不同,IN 摒弃了全局参数,试图去缩小每个测试样本与训练样本之间的差距,在抵御了风格差异影响的情况下,也破坏了区分度
-
IBN NET把两个放在一块了
-
affine parameters
- 仿射参数;仿射就是正向传播的矩阵乘积运算,也就是权重和输入特征的成绩,仿射参数就是权重和偏差
-
-
Spatially adaptive denormalization (SPADE)
-
是一个conditional normalization module 首先要求额外的数据来生成学习到的放射参数,然后用这个参数来调节归一化
-
作者加入IN后的改编
-
-
-
整个系统的框架图
-
如图所示
-
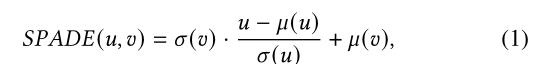
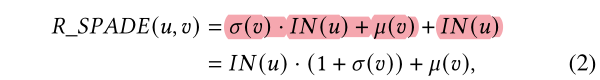
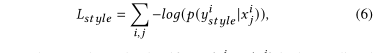


















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











