







“知道[正则表达式]可能意味着用 3 步解决一个问题,而不是用 3000 步。如果
你是一个技术怪侠,别忘了你用几次击键就能解决的问题,其他人需要数天的烦琐 工作才能解决,而且他们容易犯错。”
(1).不用正则表达式来查找文本模式
就是用程序逻辑,自己去匹配符合某种模式的字符串(如电话号码)。假如电话号码的格式如下:
3 个数字,一个短横线,3个数字,一个短横线,再是 4 个数字。例如:415-555-4242。
写出来的匹配程序是这样的:

这太丑陋了。且如果任务是从一长串字符序列中寻找电话号,用这个函数实现是这样的:

就是每12个连续字符匹配一次。太低效了。
(2).用正则表达式查找文本模式
1.创建正则表达式对象
import re
#这里创建的是Regex对象
#re.comile()函数是将字符表示的正则表达式,编译成一个 regular expression object
#这个编译后的对象,有各种匹配、搜索的功能
#如果要多次使用某个正则表达式,编译后使用更高效。要不每次都得重新编译一次
phoneNumRegex = re.compile(r"\d\d-\d")
后面是注:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
一次性匹配的情况就直接使用re.search(),不需要编译表,也不存储表达式。即下面两种方式是等效的:
result = re.match(pattern, string)
和
prog = re.compile(pattern)
result = prog.match(string)
是等价的
正则表达式对象 (正则对象)的作用:
2.进行匹配
import re
phoneNumRegex = re.compile(r"\d\d-\d")
#编译后的正则表达式对象调用搜索函数。search函数是只搜索第一次出现的pattern
mo = phoneNumRegex.search('uiafh23-3kjijkh43-8')
以下是注:
search()只能找到第一个匹配的pattern。然后就不找了。
match()只能从头开始匹配pattern,若开头不匹配则直接返回None。
findall()是老老实实找全部匹配的pattern,返回的是str组成的list。
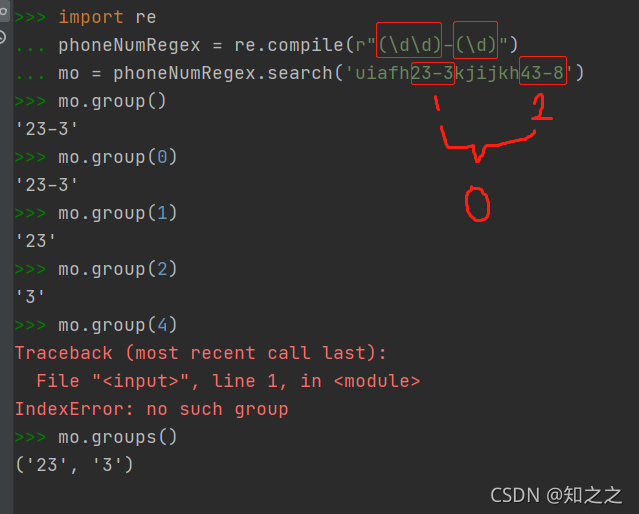
3.输出匹配结果,group()
group()函数跟正则的子表达式机制有关。group()函数的参数是这样的:
match.group([group1, ...])
groupN参数代表正则表达式中第N个括号(即第N个子表达式)。下面是程序截图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









