







实验环境
python 3.7.1+Anaconda 1.9.7+pycharm 2019.1
主要pkg
pandas、numpy、sklearn、mlxtend
数据格式
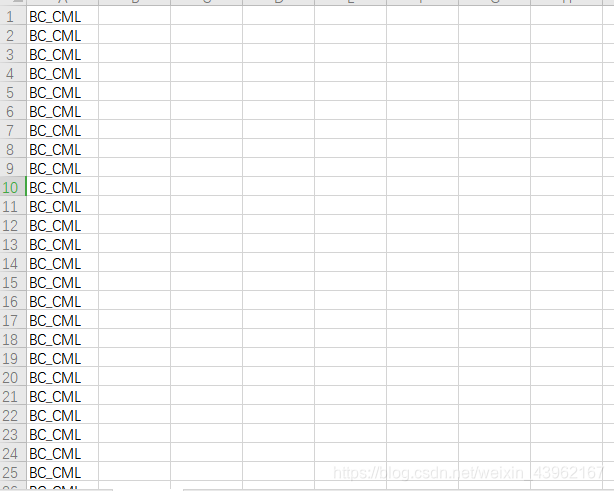
Label:
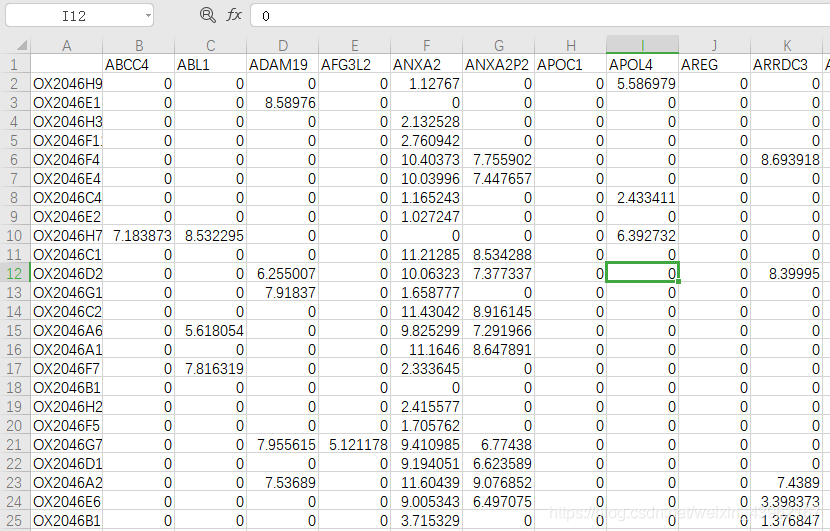
features:
主要实验步骤
- 数据读入
- 数据处理
- 数据集划分
- stacking分类器定义
- 模型训练
- 准确度预测
具体过程
首先利用pandas的read_系列函数读入数据,我用的是read_excel,(很奇怪,不知道为什么用read_csv就会一直读入失败,,)
然后,
千万要注意,要处理好数据中的字符串!否则后面fit是要报错的!!!,比如:
read_excel函数会默认将第一行剔除掉,如果不想剔除的话加一句header=None就可以了;
字符串列也要删除或映射;
续上,label中的字符串都要映射成对应的数值,可以采用简单的序号自增;
❤关于映射,有些包的分类器会将非数值类型自动映射的,但有的就不能,比如这里使用的stackingclassifier
#数据读入
df= pd.read_excel("单细胞测序数据Labels.csv",header=None)#read_csv就是不好用啊
label=df.values.tolist()
tmp = [] #去掉小列表
for i in label:
tmp.append(i[0])#此处是为了将[[a],[b]]这种嵌套列表变成[a,b]
label = tmp
df= pd.read_excel("单细胞测序数据.csv")
feature=df.values.tolist()
for i in feature:#这里是要删除非数字的列,对应数据中的第一列
del i[0]
#label映射
tmp =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









