







题目
MORL提示:离散提示优化的多目标强化学习的实证分析

论文地址:https://openreview.net/forum?id=uTfn2rGEgl
摘要
可以采用基于RL的技术来搜索提示,当将其输入目标语言模型时,最大化一组用户指定的奖励函数。然而,在许多目标应用中,自然的回报函数是相互矛盾的——例如,在风格转换任务中,内容保留与风格匹配。目前的技术专注于最大化奖励函数的平均值,这不一定会导致实现奖励平衡的提示——这是一个在多目标和鲁棒优化文献中已经得到充分研究的问题。在本文中,我们进行了几个现有的多目标优化技术的经验比较,适应这一新的设置:基于RLS的离散提示优化。我们比较了两种优化帕累托回报面的方法,以及一种选择同时使所有回报受益的更新方向的方法。我们评估了两个NLP任务的性能:风格转换和机器翻译,每个都使用三个竞争的奖励函数。我们的实验证明,直接优化帕累托回报表面的体积的多目标方法比那些试图找到单调更新方向的方法执行得更好,并且实现了所有回报的更好平衡。
简介
离散提示调整包括为语言模型(LM)提炼文本提示,以最大化LM输出上的一组用户指定目标(Shin等人,2020;席克和舒策,2020;文等,2023)。成功的提示调优技术允许用户控制强大的LLM并使其适应新任务,而无需手动提示设计的反复试验。虽然基于RL的技术已被证明在寻找优化平均奖励的提示方面是有效的(Deng等人,2022),但在许多目标应用中,自然奖励函数之间存在紧张关系。
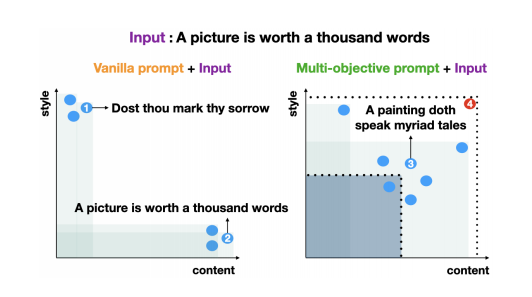
图1:从现代到莎士比亚的文本风格转换设置,其中每个点代表从LM中采样的输出句子,条件是使用平均奖励训练的提示(左)或使用多目标优化技术训练的提示(右)。输出样本1只针对样式匹配进行优化,而输出样本2只针对内容保留。另一方面,样本3同时平衡了两个目标。阴影区域表示帕累托回报面的体积测量。
例如,如图1所示,许多风格转换任务需要保留内容,同时最大限度地转换为目标风格——这两个目标是相互矛盾的。因此,目前的技术导致了一种我们称之为目标崩溃的现象:专注于最大化平均回报函数(也称为标量化)可能导致以牺牲其他目标为代价不成比例地最大化目标子集的提示。例如,在图1中,左侧的提示倾向于产生LM输出(用蓝点表示),它将一个目标的优先级排在另一个之上。相反,右侧的提示会生成同时在所有目标上实现合理性能的样本。然而,在这两种情况下,平均回报几乎相等。
报酬平衡的问题已经在其他领域得到了很好的研究,例如,多目标和稳健优化文献提出了几种具有优势的方法。过度标量化。然而,这些技术还没有应用于NLP中最相关的基于RL的离散提示优化设置。因此,在本文中,我们对几种适用于离散即时优化的现有多目标优化技术进行了实证比较,目的是评估它们在下游即时驱动的NLP任务中实现更有用的回报平衡的有效性。我们比较的前两种方法最大化了帕累托奖励表面的体积,而第三种方法选择了一个梯度更新方向,该方向对所有奖励同时有益。
更具体地说,我们研究中的第一种方法是计算从给定提示中抽取的一组样本的超容量指标(HVI) (Knowles et al,2004),并将这种测量作为RL中的最终奖励。直观地说,HVI测量了从当前提示符采样的输出的帕累托边界下的面积(如图1中阴影区域所示)。实现更好的报酬平衡的样本提高了帕累托边界,增加了HVI。然而,这种方法有一个潜在的缺点:如果一个异常样本(例如,由图1中标记为4的红点表示)在所有奖励中获得了高值,则HVI可能会高得不成比例(由图1中的外部矩形区域表示,其主导了阴影区域)。
这种显著的异常值效应可能会降低RL设置中HVI优化的稳定性,因为它对异常值变得非常敏感。因此,我们还研究了在第二种方法中使用一种更简单的方法来最大化交易量,这种方法被称为期望回报积。在这里,我们通过简单地计算奖励的平均乘积来近似预期量(在图1中由黑色矩形区域暂时描述)。第三种方法采用基于最速梯度下降的不同策略(Fliege和Svaiter,2000)。我们分别近似每个个体奖励的期望梯度,然后搜索更新方向,以同时在每个奖励中取得单调进展。
为了理解这些方法在离散提示优化设置中的有效性,我们对两个文本生成任务进行了实验:文本风格转换和机器翻译,对每个任务使用三个竞争的奖励函数。我们的研究结果表明,在这种情况下,基于数量的方法是最有效的,与基线方法相比,在平衡竞争奖励方面取得了实质性的收益。虽然基于RL的最速下降也改善了平衡,但它不如基于体积的方法那样稳健。
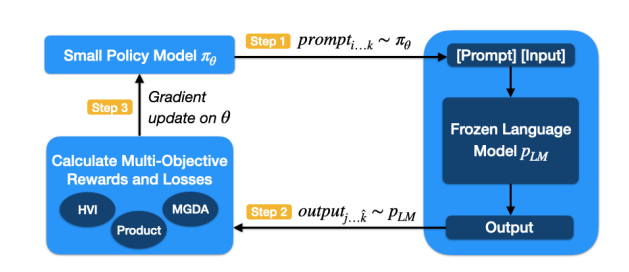
图2:在所有设置中,我们有一个参数高效的策略模型,负责生成特定于任务的提示,其中除了MLP模块之外,模型的所有参数都
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











