




《SSD-Single Shot MultiBox Detector》论文解读
目录
《SSD-Single Shot MultiBox Detector》论文解读
简要介绍
本文提出了一种使用单个深度网络检测图像中目标的方法。命名为SSD,该方法使用小型卷积滤波器来预测一组固定默认框的类别和边界框位置中的偏移量;针对不同的长宽比检测使用单独的卷积核;以及将这些滤波器应用于网络后期的多个特征图,以便执行多尺度检测。 不用对边界框假设的特征进行重新采样,可以显着提高高精度检测的速度,即使输入分辨率较低。
检测精度从YOLO的63.4%mAP提高到了SSD网络的72.1%mAP。
实验部分分别在PASCAL VOC07/12和MS COCO数据集上评估了不同输入大小的模型的性能,并与最新技术做了比较。
SSD300 Architecture
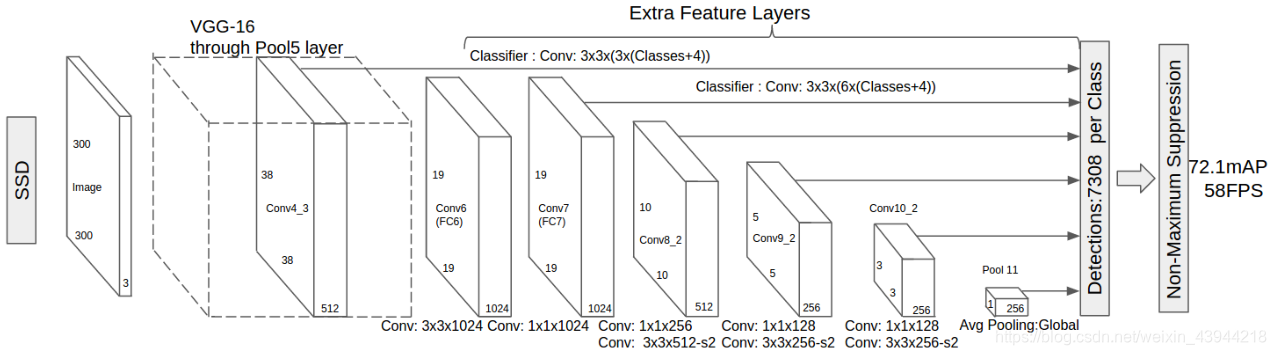
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增卷积特征层(层的大小逐渐减小),来获得更多的特征图以用于检测。
其中VGG16中的Conv4_3层作为检测的第一个特征层;加上提取的Conv7、Conv8_2,Conv9_2,Conv10_2,Pool11共6个预测特征层。然后在这6个特征层上分别预测不同尺度的目标,预测之后经过非极大值抑制算法(NMS)滤除小概率目标,得到最终的预测结果。
在第一层上检测相对较小的目标,随着抽象程度的加深,在后续层上检测越来越大的目标。
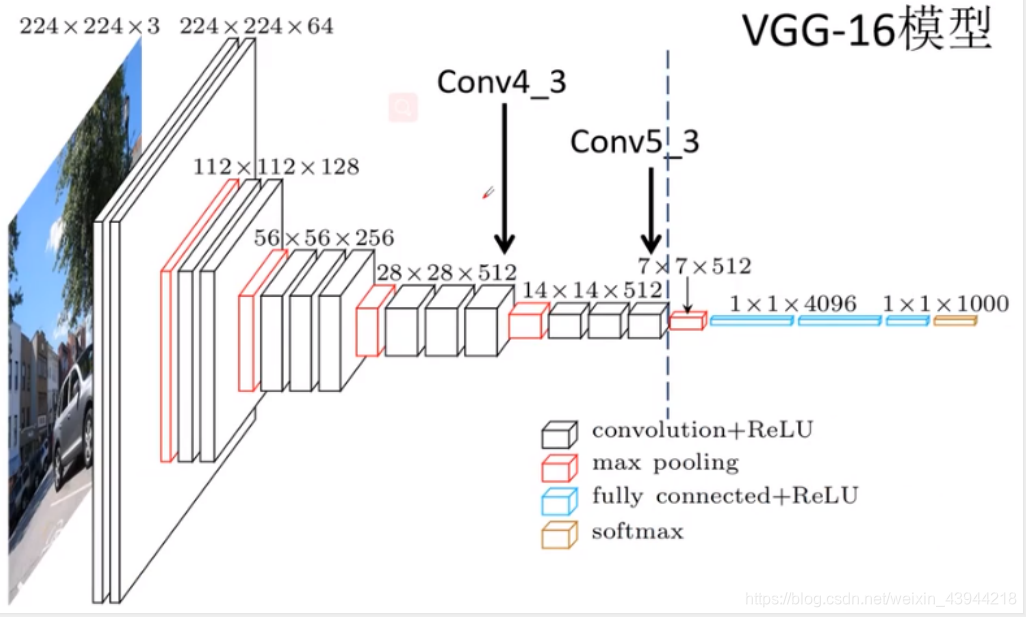
为了便于理解,我将VGG16模型的网络结构图放了上来:
检测分析
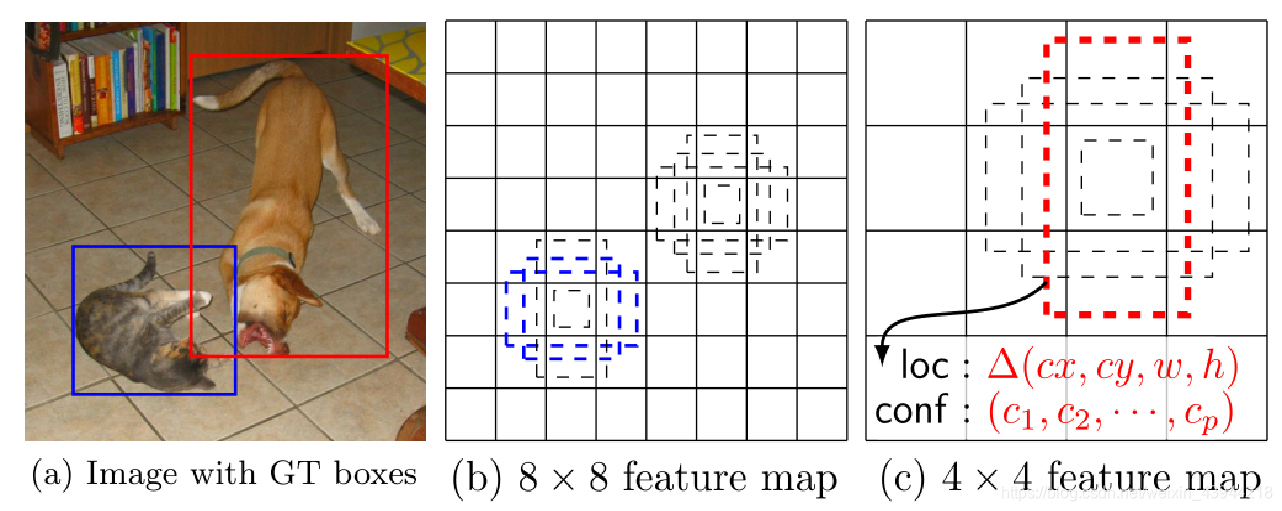
下图中左图为一张标注好的原图,图中有2个GT boxes(grounding true box)。右图是两个不同尺度的特征矩阵,8*8矩阵相对于4*4矩阵的抽样程度更低,保留的细节信息更多一些。所以能在相对低层的特征图上预测较小的目标。
所以使用8*8的特征图对小目标猫进行检测,蓝色框为Default Box;使用4*4对狗进行检测。这样检测的话,特征图上的Default Box就会与GT box进行很好的匹配。
所以这样就实现了在不同特征图上分别匹配不同尺度的目标的功能。这样可以提升小目标的检测效果。而Faster RCNN在检测小目标上效果不够好。
Predictor的实现
对于大小为m×n,通道数为p的特征层,使用3*3*p的卷积层进行预测,通过3*3的卷积核来生成类别分数,以及默认框坐标偏移量。这里的实现方法和faster Rcnn中的预测器基本类似。
对于特征图上的每个位置会生成k个默认框,对每个默认框计算c个类别分数和4个坐标偏移量。这就需要 (c + 4)k个3*3卷积核来进行卷积处理,对于m × n个特征图而言会产生(c + 4)kmn个输出值。
默认框的Scale和Aspect rtaios的设定

正负样本的选取

损失函数

采用数据扩增(Data Augmentation)可以使SSD对各种输入对象的大小和形状更加健壮。
主要采用的技术:使用原始图像;随机采集块域(Randomly sample a patch)(用来获取小目标训练样本),然后将每个patch水平翻转(horizontal flip)。
Experiments
在PASCAL VOC2007中的实验
表1显示SSD300模型比Fast R-CNN更准确。在500×500的输入图像上训练SSD时,它更加准确,mAP比Faster R-CNN快了1.9%。

各组件对性能影响的分析

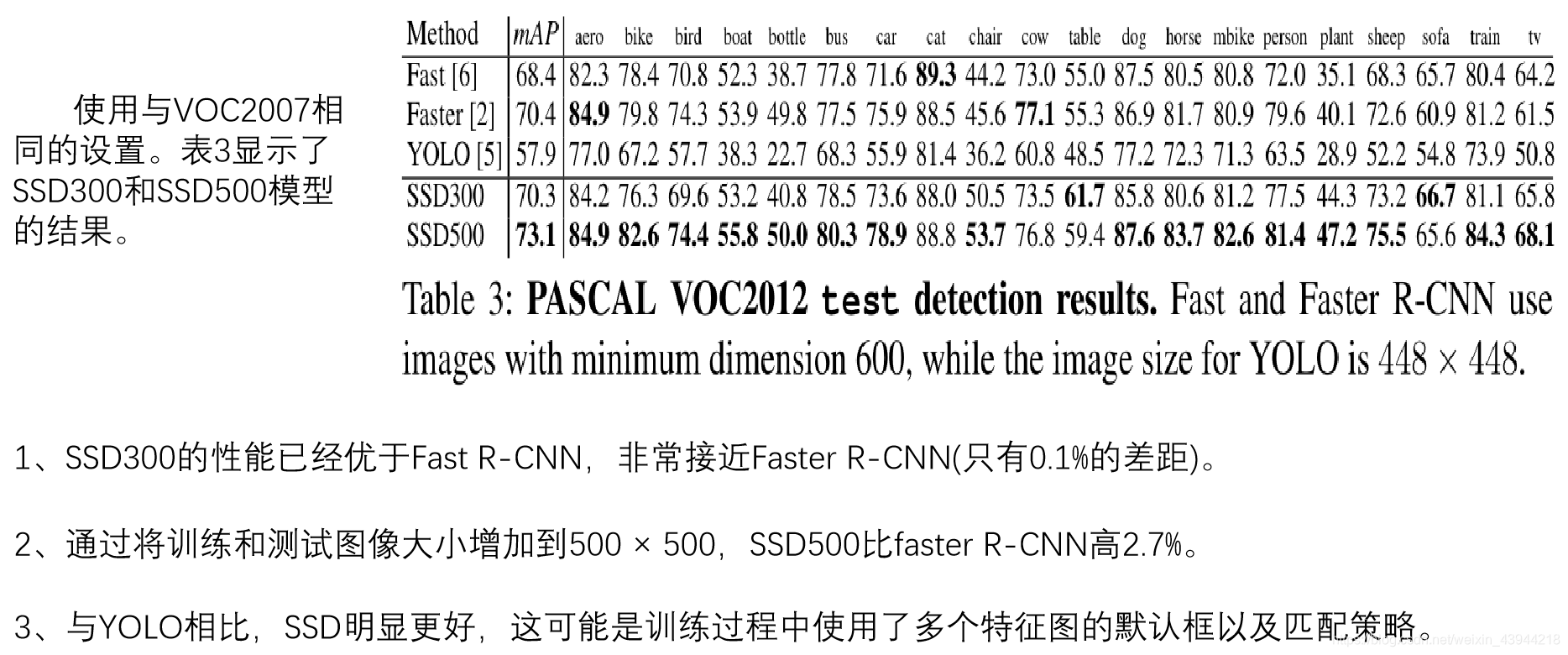
在PASCAL VOC2012数据集中的实验结果
在MS COCO数据集中的实验结果

下图是使用SSD500模型在MS COCO数据集上的检测示例,图中每个颜色框为一个类别。而且这些框的得分都是高于0.6的。

在PASCAL VOC2007中的实验结果
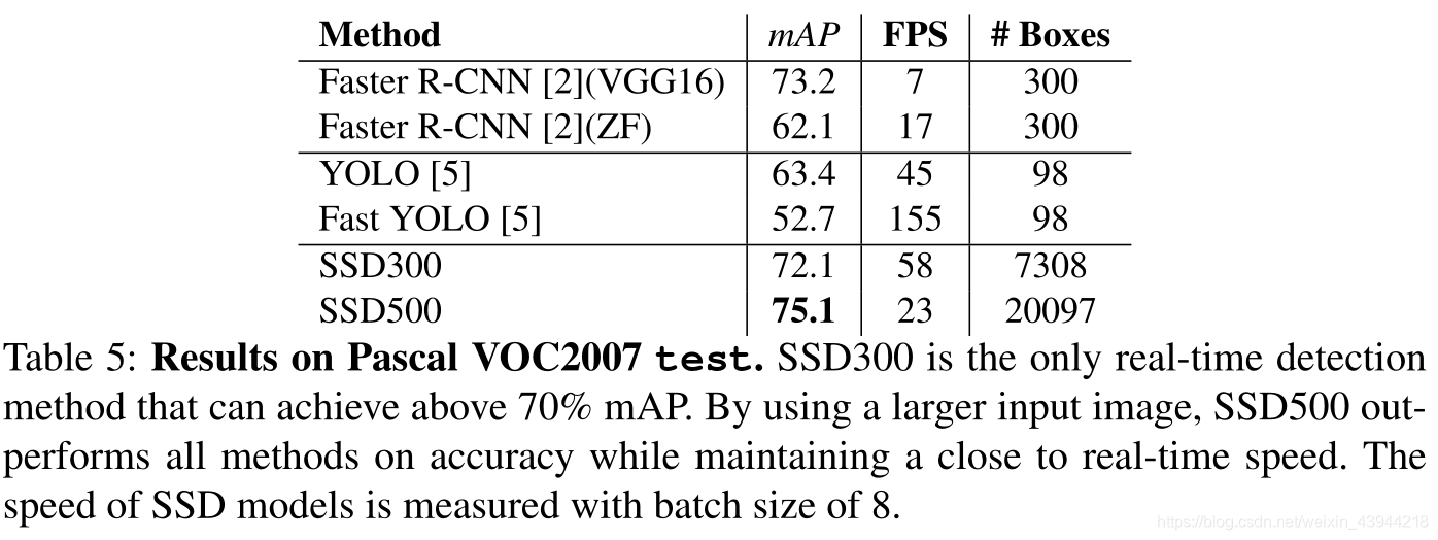
SSD300是目前唯一能够实现70%以上mAP的实时检测方法。通过使用更大的输入图像,SSD500在精度上优于所有方法,同时保持接近实时的速度。(FPS为帧每秒的意思,表示速率)
Faster R-CNN虽然也高于70%,但它对区域建议使用了额外的预测层,并且需要特征重采样,不是实时的。
感谢观看!

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









