







数字型特征预处理
根据模型处理数字特征时,特征的数值量纲大小是否会影响模型效果,分为tree-based models 和 non-tree-based models
基于树的模型tree-based models是基于信息熵来训练数据数据,所以特征的数值范围不会影响训练结果,所以不需要对特征进行feature scaling,即将不同特征数字大小转换到同一范围
而非基于树的模型non-tree-based models
包括:线性模型,KNN,神经网络,特征的数值范围都会对预测结果产生很大影响,所以需要进行feature scaling
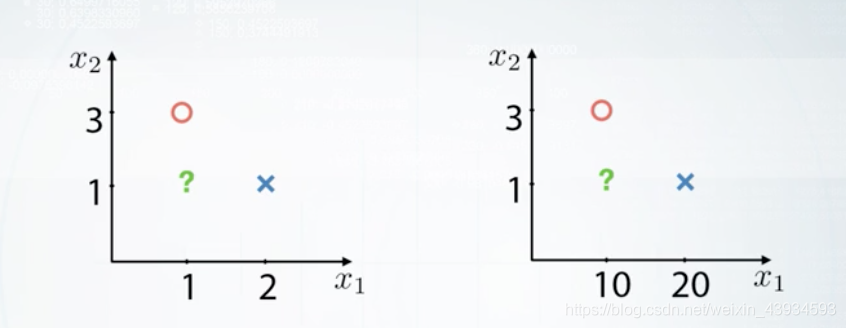
例如下图中的绿色点,用KNN算法预测它是属于红点还是蓝点,如果把x1乘以10,就会得到不同的预测结果
Preprocessing:scaling
- 归一化到 [0,1]
sklearn.preprocessing.MinMaxScaler
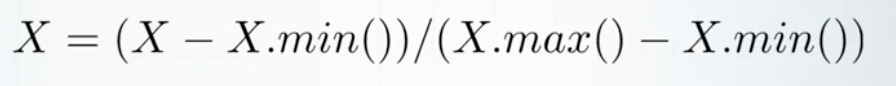
- 标准化,以0位中心,1为标准差
sklearn.preprocessing.StandardScaler
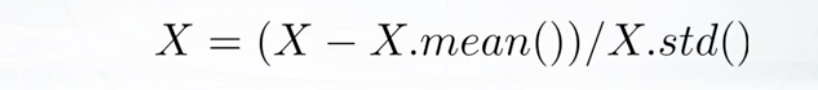
Preprocessing:outliers
离群点outliers对线性模型linear model会产生不小影响,也需要处理
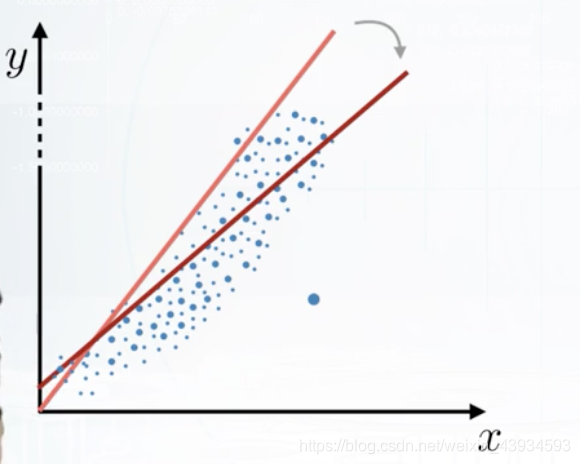
如上面图中所示,仅仅特征中一个离群点,导致模型产生了很大变化。同样,不仅是特征值即X中离群值会产生影响,预测值y中的离群值也会产生巨大影响:
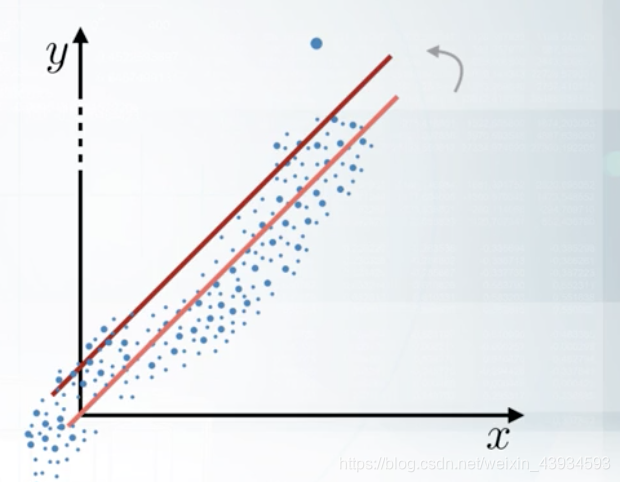
针对outliers,可以设置一个范围,只保留范围内的数据,从而剔除异常点
Preprocessing:rank
rank就是把数字转换为其对应特征中的排序,这也可以消除离群点对模型的影响,因为转为排序后,离群点距离其他点距离变得近了许多,rank时需要训练数据和测试数据一起排序

除此外,还有np.log(1+x)和np.sqrt(1+x)等方法
在运用这些scaling方法时,可以用多个模型在不同的scaling方法处理后的数据上进行训练,然后将这些模型集成,得到更好的效果。
feature generation
根据已有的特征,生成新的特征同样可能会带来更好的效果
1.假如数据中有房屋的价格,房屋的大小,那我们可以生成一个新的特征:每平方米房屋价格
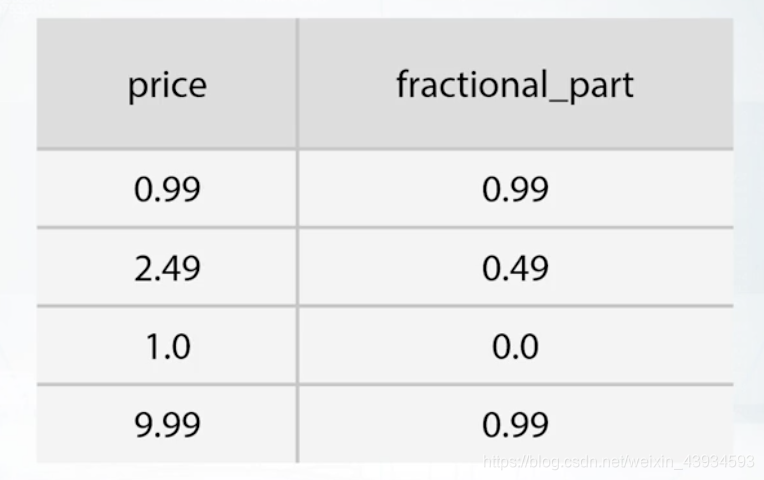
2.可以把价格的小数部分当为新的特征,因为现实生活中,比如9.99和10两个价格,相差不大,但对人们心理影响可能很大

















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









