






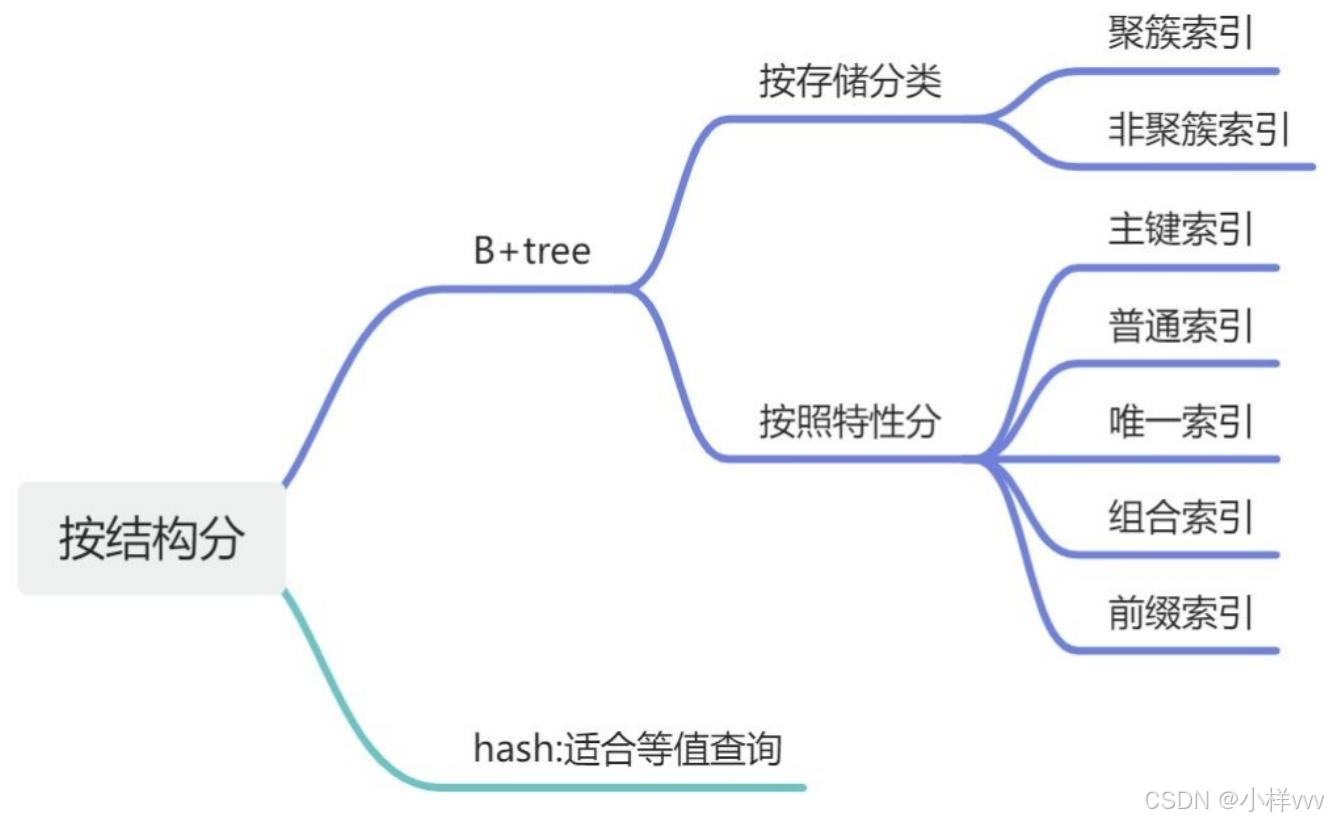
一、索引
1. 索引类型
2. B+树结构
根(index),茎(index),叶(数据)
为什么采用B+树结构作为索引
- 二叉树:左节点小于右节点的有序结构,但是如果数据递增,树结构会转为链表结构
- 红黑树:在二叉树基础之上,通过变色和旋转保证树的平衡,但是实现复杂,而且树深度较深
- 跳表:多级链表,最下面是全量数据,如果数据量多树的深度比较深
- B 树:和 B+树结构基本一样,但是叶子节点之间没有引用,导致范围查询的时候比较复杂
演示网址:http://www.rmboot.com/
3. 索引特性
- 索引下推:索引要包含条件字段,否在出现回表问题,比如 where a=1 and b=1 创建 a,b 索引就能实现索引下推
- 索引覆盖:查询的值包含在索引里,不需要回表
- 索引合并:Mysql5.1 版本推出的功能,正常一个 sql 只能使用一个索引查询数据,但是在特定场景下会使用多个索引,然后把查询结果取交集或者并集
select id from table where a=1 and b=1
note:上面的 sql 每次执行并不一定会出现索引合并,mysql 优化器还是会优先选择其中一个
索引,是根据统计信息选出返回行数少的索引,统计信息有行总数以及字段的总数
4. 创建索引注意事项
- 频繁更改的字段
- 区分率低的字段
- 不要无限制创建索引
- 组合索引注意顺序,查询频率高/等值查询/列区分度高的字段的放在前面
- 尽量设计索引覆盖
- 如果索引列太长可以设置成前缀索引
5. 索引失效场景
索引失效分为绝对和相对的
绝对会失效的
a. 模糊查询%在前面
b. 组合索引没有按照最左原则匹配
c. 查询类型发生转换
d. 字段计算
相对会失效的
<> != between is not null 等范围查询;如果索引页的数据比较均匀的还是会走索引的,类型是 range,如果不均匀可能会走全表
二、事务
1. 事务特性
1. 原子性
要么全部成功,要么全部失败(由 undolog 实现)
2. 隔离性
a. 读未提交
读另一个事务未提交的数据-脏读
b. 读已提交
在一个事务内执行相同的查询,两次查询得到的结果集不一致-不可重复读
c. 读重复(默认隔离级别)
通过 Mvcc 解决不可重复读:读取的快照区,其他线程修改该条记录,不会影响查询
通过 Next-key lock 解决幻读问题:读取的时候会加锁,其他写入线程无法进行写入操作
d. 串行化
3. 持久性
4. 一致性
note:事务的原子性,隔离性,持久性是手段,一致性是目的
2. 事务实现原理
- undo.log(保证原子性)
执行写操作时候,会把原始数据保存到 undo.log 中,并且 Mysql 有一个隐藏字段
roll_pointer,这个字段存储的是原始数据的引用,当事务回滚时候通过 undo.log 把数据恢
复到原始状态,事务提交后,会删除 undo.log 文件 - redo.log(保证持久性)
事务开启后,会把修改的内容保存到 redo.log 中,如果 mysql 出现宕机,重启后会根据
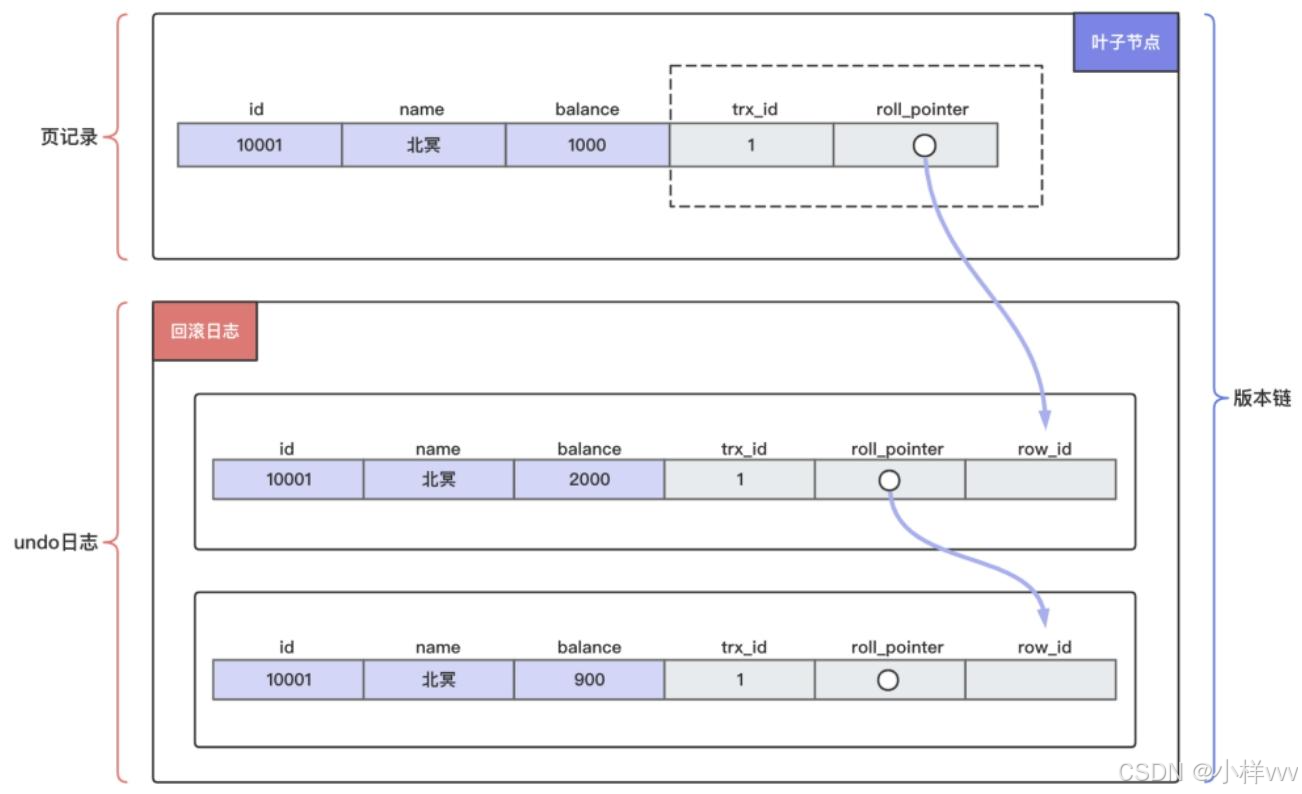
redo.log 文件做数据恢复 - Mvcc(保证隔离性;防止不可重复读问题)
是由版本号+版本链组成,一般隔离性都是通过锁机制实现,Mvcc 类似乐观锁,提升系统并发
版本号:每条记录都有版本号(隐藏字段 tx_id),当修改时候会为记录新增一个版本(复制),这个版本号比当前最大的版本号大 1,查询操作会去查比这个版本号小的版本(类似CopyOnWriteArrayList)
版本链:类似链表结构,用来当事务回滚的时候,可以沿着版本链把数据恢复
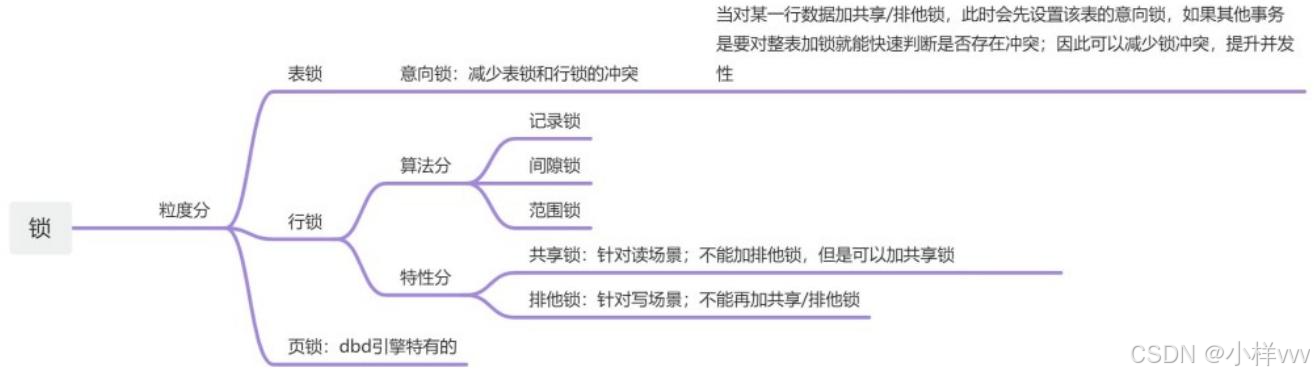
- 锁(保证隔离性;防止幻读问题)
如何解决死锁
关于死锁问题可以从三方面讨论 - 如何避免死锁
固定顺序访问表和行
把大事务拆成小事务
加索引走行锁,减少锁的粒度
设置锁的过期时间(innodb_lock_wait_timeout 默认 50s) - 如何监控死锁
通过日志或者命令 - 出现死锁问题如何解决
mysql 检测到死锁,会选择一个事务作为牺牲品然后回滚
三、sql优化
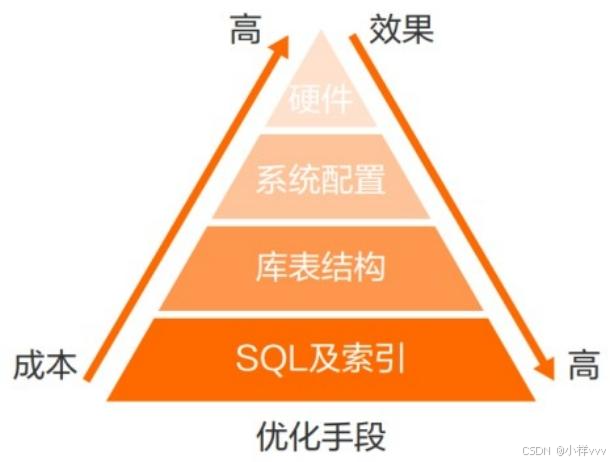
1. sql 优化
索引:where 条件、排序、多表关联字段、分组字段
关联查询尽量用 join 代替 where
深度分页,通过 limit 先查 id,然后用 id 去匹配记录
加 limit 或者限制扫描范围
2. 其他优化
反三范式设计,冗余字段,减少多表关联
字段尽量设计成数字类型
读多写少的场景可以用缓存
批量操作
水平分表(分区)
3. explain关键字
- type
a. all:全表
b. index:全索引
c. ref:普通索引
d. const:唯一索引 - extra
a. use temprary:出现临时表
b. user where:出现回表
c. user index:只用索引就查出数据
d. user index condition:出现索引下推
e. user file sort 排序
四、FAQ
- 索引数大概分几层 可以存储多少数据
索引树一般 3-4 层,3 层可以存储 2000w 数据,4 层可以存 200 亿数据 - 读重复和幻读的区别
读重复:线程 A 读取记录 1,线程 B 更改记录 B,线程 A 再次读取记录 1 与之前的不一样(RP通过记录锁解决)
幻读:线程 A 读取某个范围,线程 B 进行 insert 操作,线程 A 再次读取记录数增多(RP 通过MVCC 解决)
五、实际应用问题
1. 大表怎么加字段
采用 pt-online-change
原理:1. 创建新表
2. 在旧表创建触发器,出现写操作,将数据同步到新表
3. 迁移旧数据
4. 修改表名
这类的思想都是统一的,迁移数据不要动原表,都要创建一个新表,迁移分新旧数据俩部分,新数据可以通过触发器或者代码中双写,旧数据直接复制就可以了
对于 ALTER TABLE 操作,如果是添加或删除列等操作可能会导致表重建,会使用排他锁,这期间会阻塞其他对该表的读写操作。如果使用在线 DDL 功能(MySQL 5.6 及之后版本部分操作支持),对表的锁定会相对宽松,一些读操作可以并发执行,但写操作仍可能被阻塞。
2. 大数据库的导出
大数据的读取如果一次性查询出来会有内存溢出的问题,如果用分页(limit1,1)会有深度分页的问题,可以采用游标的方式查询(将当前页的最后一条记录的标识字段作为下一页查询的起点,查询时按主键或索引范围查询)
SELECT * FROM books
WHERE id > #{lastId}
ORDER BY id ASC
LIMIT #{pageSize}
3. excel 大数据导入
方案一:通过 datax 将 excel 转为 csv 文件,然后配置 datax json,通过 datax 命名执行导入
方案二:分批读取到内存+多线程
4. 深度分页怎么查询
深度分页分为顺序分页和跨分页
顺序分页问题可以通过游标的方式解决(当前页的最后一个 id 作为下一页的起始 id)
跨分页问题 mysql 无法从根本上解决,只能是尽量规避减少该问题,比如查询的时候加上时间范围(设备表几千万数据,加上时间条件);但是可以通过 es 的 search_after 解决深度分页的问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









