






 本文详细介绍VOC数据集的组成部分,包括Annotations、ImageSets等关键文件夹的作用,以及如何使用Python进行数据预处理,包括坐标转换、XML文件生成和ImageSets的创建。
本文详细介绍VOC数据集的组成部分,包括Annotations、ImageSets等关键文件夹的作用,以及如何使用Python进行数据预处理,包括坐标转换、XML文件生成和ImageSets的创建。
textbox之VOC数据集制作
- 数据集包括哪些东西
最近在做VOC数据集方面的制作,和大家分享一下经验。
我们做的项目是基于MobileNet-SSD的文本识别,也就是把20种物体分类用一种文本类代替。
首先我们要知道VOC数据集有哪些东西,一般voc解压出来后都包括Annotations,ImageSets,JPEFImages,SegmentationClass ,SegmentationObject;
Annotations中是放着所有图片的标记信息,以xml为后缀名.以分类检测的数据为例,打开ImageSets中的layout,会有train,trainval,val三个txt格式数据,:
1 train 很明显是训练数据(注意,均为图片名,没有后缀)
2 val 验证数据
3 trainval 则是所有训练和验证数据
4 test 测试数据
而ImageSets中的Main文件夹中保存的是各类数据出现的统计,以areoplane为例,有三个相关文件aeroplane_train.txt,areoplane_val,areoplane_trainval.txt,以areoplain_train.txt为例,分为两列,第一列为图像名如00012(注意没有后缀),第二列为-1和1,-1表示目标在对应的图像没有出现,1则表示出现。
要注意的是我们做的是文本识别,所以只有一类物体,即分好的txt文件中第二列均为1。
segmentationclass和segmentationobject中均为分割后的结果(文本识别不需要)
Annotations文件夹中包含了所有train和val的标记信息,标记信息均以xml结尾。
除了这些文件夹,我们还需要一个labels文件夹(存放文本框坐标信息)用来转为xml文件。即下面四个文件夹是有用的。

- 数据集制作
1.首先把给的图片和txt坐标文件改名为000001这种格式,即长度为6,步长为1的命名格式。

然后就有人会问怎么批量改名了,我推荐用一个批量处理软件Total Commander,亲测很好用。
Total Commander下载
2.接下来要制作labels标签文件,格式如下:

4个数字分别为文本框坐标xmin,ymin,xmax,ymax。
然后我得到的txt是这样的:

即矩形框的四个点(x,y)值都有。
这个转换我用自己写的python脚本处理了一下:
import os
import numpy as np
import codecs
np.set_printoptions(suppress=True)
if __name__=='__main__':
labels_file_path = "labels的路径"
labels_name = os.listdir(labels_file_path)
i=1
for label_name in labels_name:
label_path = os.path.join(labels_file_path, label_name)
# print(label_path)
# print(label_lines)
data = np.loadtxt(label_path,encoding='utf-8-sig',delimiter=',',dtype=np.str,usecols=[0,1,2,3,4,5,6,7])
# label = read_txt(label_path)
# data=data[:,:8]
# data = data.astype(np.float)
a=[0,2,4,6]
b=[1,3,5,7]
c=data[:,a]
d=data[:,b]
# print(data)
# print(c)
# print(d)
e=np.hstack((c,d))
w=[]
q=[]
u=['0','0','0','0']
u=np.loadtxt(u)
for r in e:
# print(r)
x_min=np.array(r[:4],dtype=np.float).min()
x_max=np.array(r[:4],dtype=np.float).max()
y_min=np.array(r[4:],dtype=np.float).min()
y_max=np.array(r[4:],dtype=np.float).max()
w=np.array([x_min,y_min,x_max,y_max],dtype=np.str)
w=np.loadtxt(w)
u=np.vstack((u,w))
# print(w)
# q.extend(w)
# print(u)
u=u[1:,:]
# print(u)
print(i)
i=i+1
np.savetxt(label_path,u,fmt='%s',delimiter=',')#测试的时候可以先注释
3.接下来制作xml文件
先看一下xml文件格式:

代码:
import os
import numpy as np
import codecs
import cv2
def read_txt(label_path):
file = open(label_path,'r',encoding='utf-8-sig')
label_lines = file.readlines()
label = []
for line in label_lines:
one_line = line.strip().split(',')
label.extend(one_line)
return np.array(label)
def covert_xml(label,xml_path, img_name, img_path):
img = cv2.imread(img_path)
# try:
height, width, depth = img.shape
# except:
# raise
xml = codecs.open(xml_path, 'w', encoding='utf-8-sig')
xml.write('<annotation>\n')
xml.write('\t<folder>' + 'VOC2007' + '</folder>\n')
xml.write('\t<filename>' + img_name + '</filename>\n')
xml.write('\t<source>\n')
xml.write('\t\t<database>The VOC2007 Database</database>\n')
xml.write('\t\t<annotation>PASCAL VOC2007</annotation>\n')
xml.write('\t\t<image>flickr</image>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t</source>\n')
xml.write('\t<owner>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t\t<name>Leo</name>\n')
xml.write('\t</owner>\n')
xml.write('\t<size>\n')
xml.write('\t\t<width>' + str(width) + '</width>\n')
xml.write('\t\t<height>' + str(height) + '</height>\n')
xml.write('\t\t<depth>' + str(depth) + '</depth>\n')
xml.write('\t</size>\n')
xml.write('\t<segmented>0</segmented>\n')
for i in range(0,int(len(label)/4)):
if(int(float(label[4 * i].item()))<0):
x_min = 0
print(img_path)
else :
x_min = label[4 * i]
x_min = int(float(x_min.item())+0.5)
if (int(float(label[4 * i+1].item())) < 0):
y_min = 0
print(img_path)
else:
y_min = label[4 * i+1]
y_min = int(float(y_min.item())+0.5)
if (int(float(label[4 * i+2].item())) >width):
x_max = width
print(img_path)
else:
x_max = (label[4 * i + 2])
x_max = int(float(x_max.item())+0.5)
if (int(float(label[4 * i+3].item())) >height):
y_max = height
print(img_path)
else:
y_max = (label[4 * i + 3])
y_max = int(float(y_max.item())+0.5)
xml.write('\t<object>\n')
xml.write('\t\t<name>textbox</name>\n')
xml.write('\t\t<pose>Unspecified</pose>\n')
xml.write('\t\t<truncated>0</truncated>\n')
xml.write('\t\t<difficult>0</difficult>\n')
xml.write('\t\t<bndbox>\n')
xml.write('\t\t\t<xmin>' + str(x_min) + '</xmin>\n')
xml.write('\t\t\t<ymin>' + str(y_min) + '</ymin>\n')
xml.write('\t\t\t<xmax>' + str(x_max) + '</xmax>\n')
xml.write('\t\t\t<ymax>' + str(y_max) + '</ymax>\n')
xml.write('\t\t</bndbox>\n')
xml.write('\t</object>\n')
xml.write('</annotation>')
if __name__=='__main__':
labels_file_path = "labels路径"
imgs_file_path = "图片路径"
xmls_file_path = "xml文件路径"
if not os.path.exists(xmls_file_path):
os.mkdir(xmls_file_path)
labels_name = os.listdir(labels_file_path)
for label_name in labels_name:
label_path = os.path.join(labels_file_path, label_name)
label = read_txt(label_path)
xml_name = label_name[:6]+'.xml'
xml_path = os.path.join(xmls_file_path, xml_name)
img_name = label_name[:6]+'.jpg'
img_path = os.path.join(imgs_file_path, img_name)
# try:
covert_xml(label, xml_path, img_name, img_path)
# except:
# os.remove(label_path)
# print(label_path)
#注释的地方是用来删除不符合格式要求的图片和坐标文件的
这里要注意的是,opencv不能识别小数点,所以要把坐标转为整数;
还有一些越界的坐标值要转换问边界值,不然训练时会报错。
代码中已处理。(我们在这里卡的挺烦的)
然后就是object name都应该是一个,表示只有一类物体。
4.生成ImageSets的main文件
也是用的python
import os
import random
xmlfilepath = "xml文件路径"
saveBasePath = "新建一个文件"
trainval_percent = 0.5
train_percent = 0.5
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
ftrainval = open(os.path.join(saveBasePath, '你的路径/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, '你的路径/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, '你的路径/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath, '你的路径/ImageSets/Main/val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后你还要新建四个txt文件:

将对应的标号考一遍,并在后面加上1;
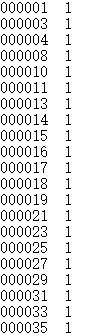
用Notepad++可以直接列块编辑。
至此所有文件夹都制作完毕,要运用到caffe上可以训练还要改一下相应参数。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









