







目录:
第一节 机器学习&深度学习介绍
第二节 机器学习攻略
一、机器学习的框架
二、模型训练攻略
三、针对Optimization Issue的优化,类神经网络训练不起来怎么办
(一) 局部最优点和鞍点
(二) 批处理和momentum
(三) 自动调节学习率Learning rate
(四) 损失函数带来的影响
第三节 CNN & Self-Attention
一、卷积神经网络
二、自注意力模型
待更新.......
本章主要介绍CNN & Self-Attention的内容
一、卷积神经网络(Convolution Neural Network,CNN)
如果现在有一个图像分类的任务,我们用全连接对图片做特征提取时,我们来计算一下,一层全连接所需要的模型参数量,假如输入一张 100×100×3 的3D-tensor的照片,则首先我们需要将它展开成 100×100×3 的1D-tensor,并用一个nn.Linear( 100×100×3 , 100×100×3 )线性层做特征提取,这个时候该层模型的模型参数量就是 3×108 多个,显然一层的神经网络就有很多参数量了,如果再多加几层的话,参数量就成倍的增加了,显然这不适合模型训练和存储。
(1) CNN的由来
观察 1
问题:模型参数量太多
那对于类似于图像辨识这样的问题,我们不需要隐层的每个neural都需要对input的每个dimension都有weight,往往我们只需要neural识别出图像中某些重要的特征即可。举例来说,我们希望隐层的某些neural具有识别鸟嘴的能力,某些neural具有识别鸟眼的能力,某些neural具有识别鸟脚的能力等等...只要能识别出这些具有明显辨识度的内容,基本就能判断出这张图中有鸟类,这个想法和人类识别鸟类是一个道理。那也就是说,我们并不需要每个neural都要看到整张图的特征,只要看到想看的部分就可以了,或者说这些neural并不需要把整张图片当做输入,只需要输入一小部分图片内容并获得其中的特征即可。
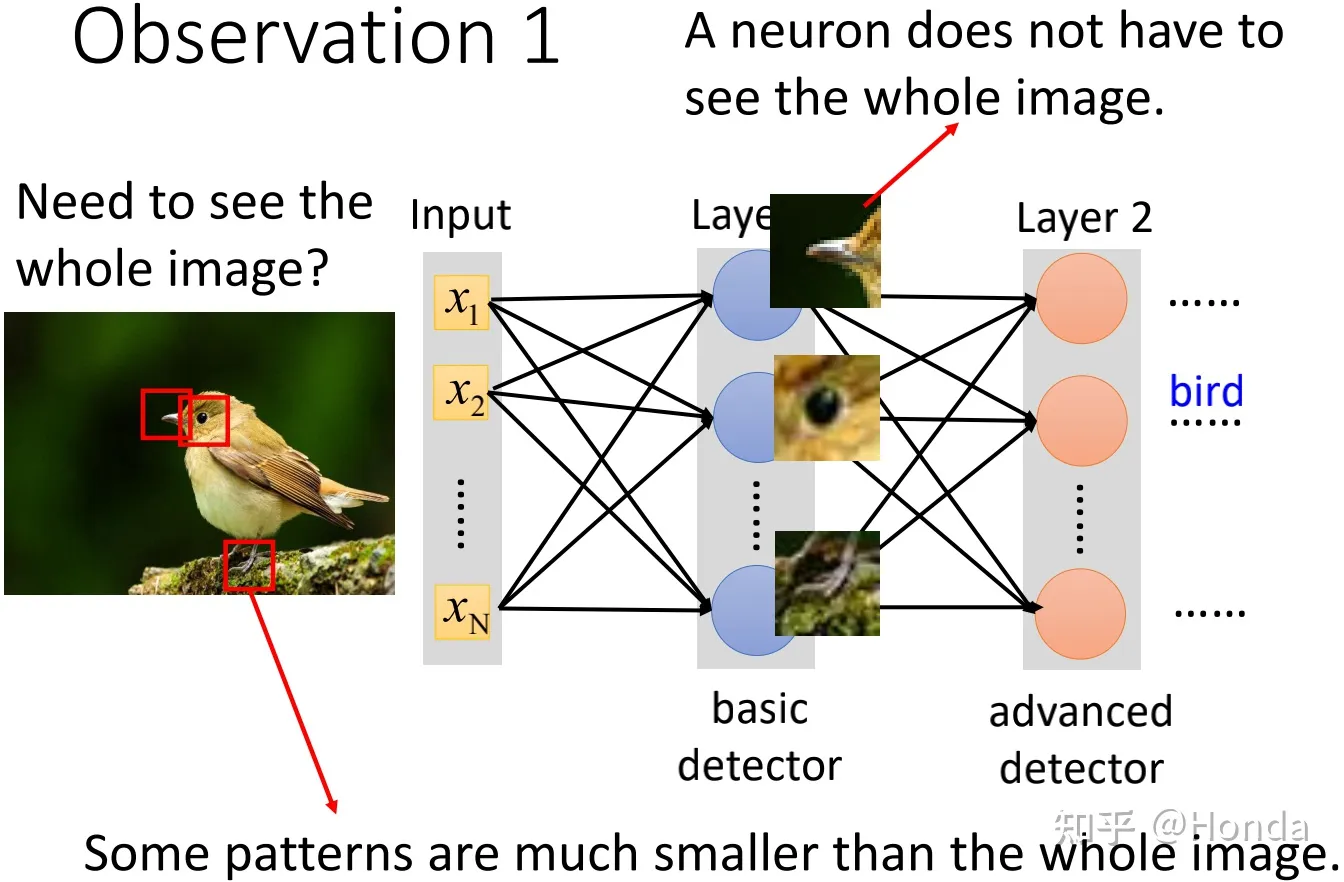
解决方案:
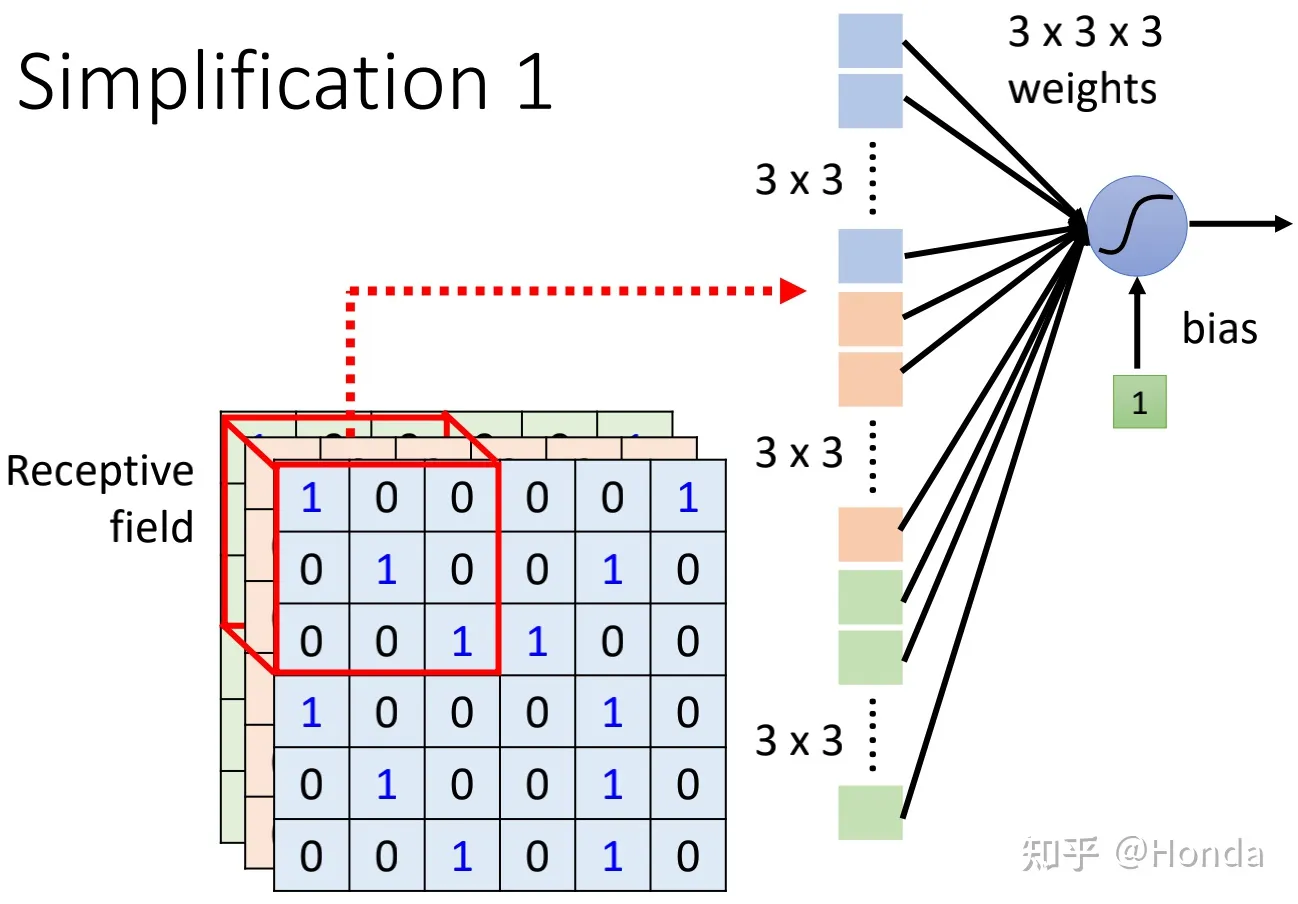
简化 1
我们会想到第一个可能的简化版本,就是隐层的每个neural只看一小部分区域,比如 3×3×3 这个小区域,而这个看的部分就是感受野(Receptive field)(下图中带激活函数的那个部分就是一个neural,其前面是Receptive field的展开),至于你要设计多少个隐层的neural去看,这就决定于你的网络设计,每个neural的感受野(注意这里指的是感受野,不是conv kernel)可以完全不一样,也可以部分重叠,也可以完全不一样,这样每个neural从之前的全连接可以缩短到只有 3×3×3 这么大小的区域了。
再简化一些,我们可以针对每个neural设计不同大小的Receptive field,或者不同channel number的Receptive field,甚至Receptive field可以不是square形状的等等,因此,理论上我们可以自定义我们想要的Receptive field。因此,有了进一步的简化:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









